require("LearnBayes")
beta.par <- beta.select(list(p=0.5, x=0.35), list(p=0.75, x=.45))
betafunction (a, b)
.Internal(beta(a, b))
<bytecode: 0x1561332f0>
<environment: namespace:base>beta.par[1] 4.12 7.38Dok su ostala poglavlja u knjizi usredotočena na primjenu klasične (frekvencijske) statistike, u ovom poglavlju će se samo spomenuti da postoji još jedan pristup u statistici, tzv. Bayesova statistika. Kroz već spomenute primjere testova bit će napravljeni izračuni da bi se mogla napraviti direktna usporedba dvaju pristupa. Primjena Bayesove statistike u odnosu na klasičan pristup je postala popularna u proteklom desetljeću, kroz povećan fokus oko otvorene znanosti i pitanja vezanih za reproducibilnost analize. Ipak, još uvijek većina istraživača provodi analize korištenjem klasičnog pristupa, te se prilikom učenja Bayesove statistike, uglavnom započinje s statističkim postupcima koji su prisutni u klasičnom pristupu (t testovi, korelacije, analize varijanci), iako je sve postupke moguće napraviti i u Bayesovom pristupu.
Naravno, između klasičnog i Bayesovog pristupa postoje određene razlike. Glavna razlika se odnosi na to da se u klasičnom pristupu smatra da postoji neka određena vrijednost u populaciji (parametar) koji mi pokušavamo procijeniti na temelju naših podataka dobivenih slučajnim uzorkovanjem. S druge strane, Bayesova statistika smatra da, umjesto procjene jednog “pravog parametra/vrijednosti” postoji distribucija različitih vrijednosti koji mogu biti rezultat podataka koje imamo, a za svaku od tih vrijednosti postoji određena vjerojatnost da je točna. Ta distribucija vjerojatnosti se zove posteriorna distribucija (posterior) jer nastaje kao rezultat prethodne vjerojatnosti i dostupnih podataka.
Osim distribucije posteriornih vjerojatnosti, u izračun Bayesove statistike ulazi i prior vrijednost, koja označava veličinu parametra (veličinu učinka, korelacije) koji bismo očekivali prema prijašnjim istraživanjima i/ili iskustvu. Kod klasičnog pristupa toga nema, jer u izračunima (npr. t-testa ili korelacije) testiramo razlike ili usporedbe kao da ne znamo ništa o podatcima. Bayesov pristup je malo intuitivniji, jer dopušta mogućnost uvođenja prethodne vjerojatnosi (priora) u izračun, te kombinacijom podataka koje imamo i priora, pokušava donijeti zaključak o veličini učinka ili povezanosti.
Dakle, prior i posterior vrijednosti su ono što esencijalno razlikuje klasičan od Bayesovog pristupa. Pored toga, sam kompleksan izračun postupaka vezanih za Bayesovu statistiku predstavlja dodatan čimbenik zašto se Bayesova statistika rjeđe koristi. Srećom, korištenjem R-a neće biti potrebno (značajno) poznavanje matematike koja se nalazi u podlozi izračuna Bayesove statistike. Koncepti koje ćemo prvo obraditi su vezani za poznavanje terminologije Bayesove statistike, a nakon toga ćemo se orijentirati na usporedbu dviju vrsta statistika na primjerima t-testa, korelacije i analize varijance. Ovo poglavlje nije namijenjeno detaljnom prikazu Bayesove statistike.
Recimo da nas zanima vjerojatnost hoće li sutra biti sunčan dan u našem gradu. Korištenjem paketa “LearnBayes” i funkcije beta select možemo specificirati prethodne (prior) vrijednosti na temelju prethodnog poznavanja centila.
Hipotetski, uzmimo u obzir da je medijan proporcije (p=0.5) sunčanih dana 0.35, a 75. (p=0.75) centil iznosi 0.45. U ovom slučaju smo proizvljno postavili vrijednosti medijana i 75. centila.
require("LearnBayes")
beta.par <- beta.select(list(p=0.5, x=0.35), list(p=0.75, x=.45))
betafunction (a, b)
.Internal(beta(a, b))
<bytecode: 0x1561332f0>
<environment: namespace:base>beta.par[1] 4.12 7.38Interval beta distribucije je od 4.12 do 7.38 (0.412 do 0.738). Distribucija podataka sa medijanom od 0.35 predstavlja našu prior distirbuciju (ili prethodnu vjerojatnost). Svi podatci koje kasnije dodajemo u izračun su pod utjecajem ove prethodne vjerojatnosti.
Sljedeće što trebamo napraviti je dodati podatke. Promatramo vrijeme 10 dana i recimo da od toga bude 6 sunčanih dana (što bi pojednostavljeno značilo da imamo 6 “pogodaka” i 4 “promašaja”). Prema ovim novim informacijama, poteriorna distribucija ima oblik prema parametrima: 4.12+6 i 7.38+4.
Na sljedećem prikazu možemo vidjeti kako izgledaju raspodjele prior vrijednosti, podataka te posteriorna raspodjela, korištenjem funkcije triplot.
triplot(beta.par, c(6, 4))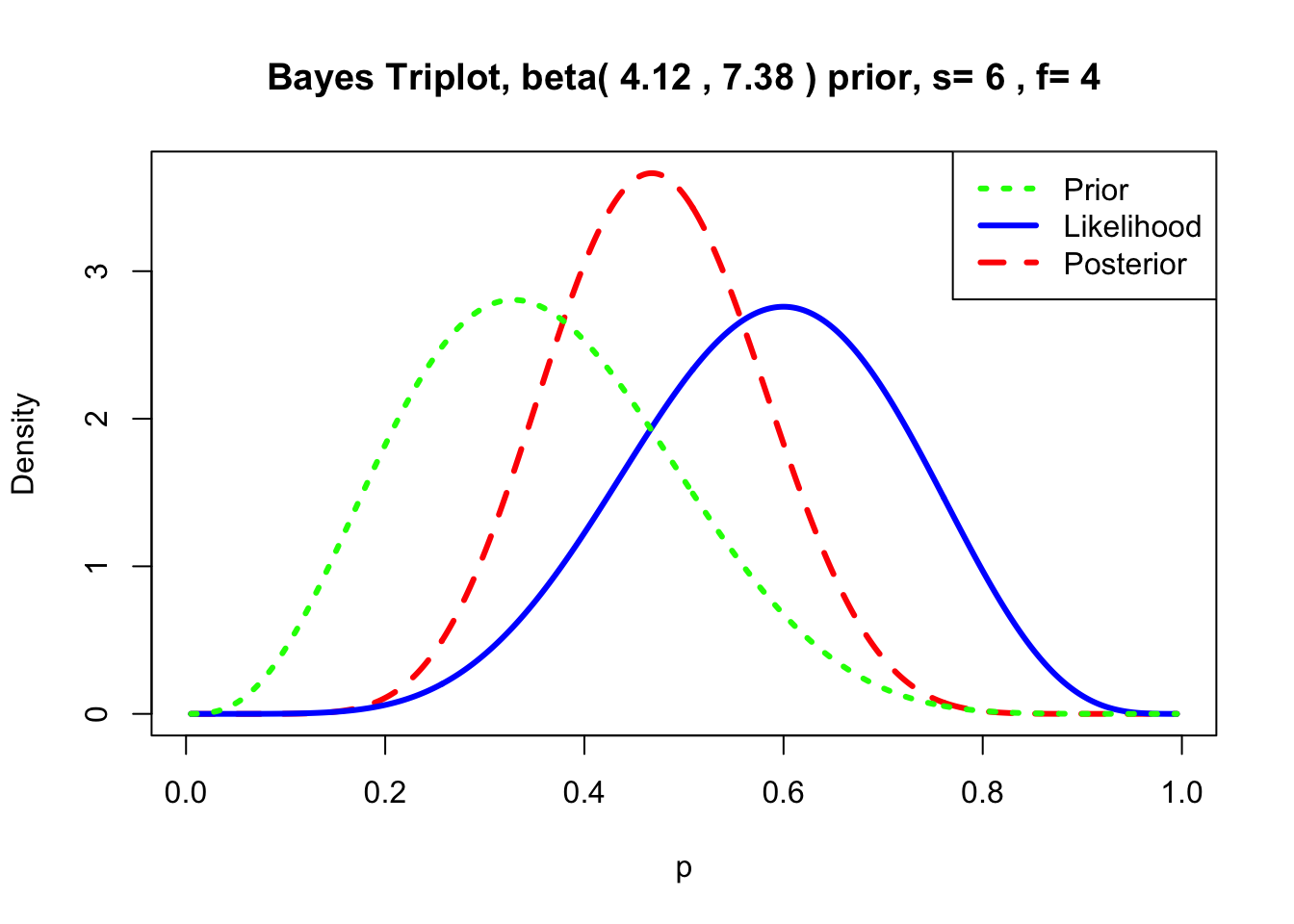
Na slici jasno vidimo kako je medijan sunčanih dana za distribuciju prior-a 0.35, dok je prema našim podatcima najveća gustoća distribucije oko proporcije od 0.60 (jer imamo 6 od 10 sunčanih dana). To je rezultiralo sa posterior distribucijom koja nudi distribuciju vjerojatnosti proporcije sunčanih dana. Osim same posteriorne distribucije, zanima nas (kao i kod frekvencijske statistike!) u kojem rasponu se nalaze naši rezultati, u ovom slučaju vjerojatnost da će sutra biti sunčano. To možemo dobiti korištenjem rbeta funkcije.Na sljedeći način ćemo dobiti 90% raspon vjerojatnosti u kojem se nalazi prava proporcija rezultata, na temelju simulacije velikog broja uzoraka.
beta.post.par <- beta.par + c(6, 4)
post.sample <- rbeta(1000, beta.post.par[1], beta.post.par[2])
quantile(post.sample, c(0.05, 0.95)) 5% 95%
0.2894884 0.6436042 median(post.sample)[1] 0.4740166Dakle, prava proporcija sunčanih dana se nalazi u rasponu od 0.29 do 0.65, što obuhvaća i naše opažanje od p=0.6. Medijan proporcija (broja sunčanih dana) iznosi oko 0.47.
Naravno, cilj nam je uvijek predvidjeti buduće događaje. U ovom slučaju možemo pokušati predvidjeti, na temelju prethodnih parametara, koliko će sunčanih dana biti u sljedećih 30 dana.
U prvom koraku moramo definirati broj opažanja te mogući broj “uspješnih opažanja” (sunčanih dana-s). Nakon toga, na temelju zadanih parametara i prethodnog modela, radimo 90% raspon vjerojatnosti u kojem se nalazi najvjerojatniji broj “uspješnih” opažanja.
n <- 30
s <- 0:n
pred.probs<-pbetap(beta.par, n, s)
discint(cbind(s, pred.probs), 0.90)$prob
[1] 0.9102908
$set
[1] 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18Dakle, raspon u kojem bismo mogli očekivati broj sunčanih dana s 90% sigurnosti ide od 3-18. Naravno, uvijek je dobro distribuciju vjerojatnosti i grafički prikazati.
plot(s, pred.probs, type="h")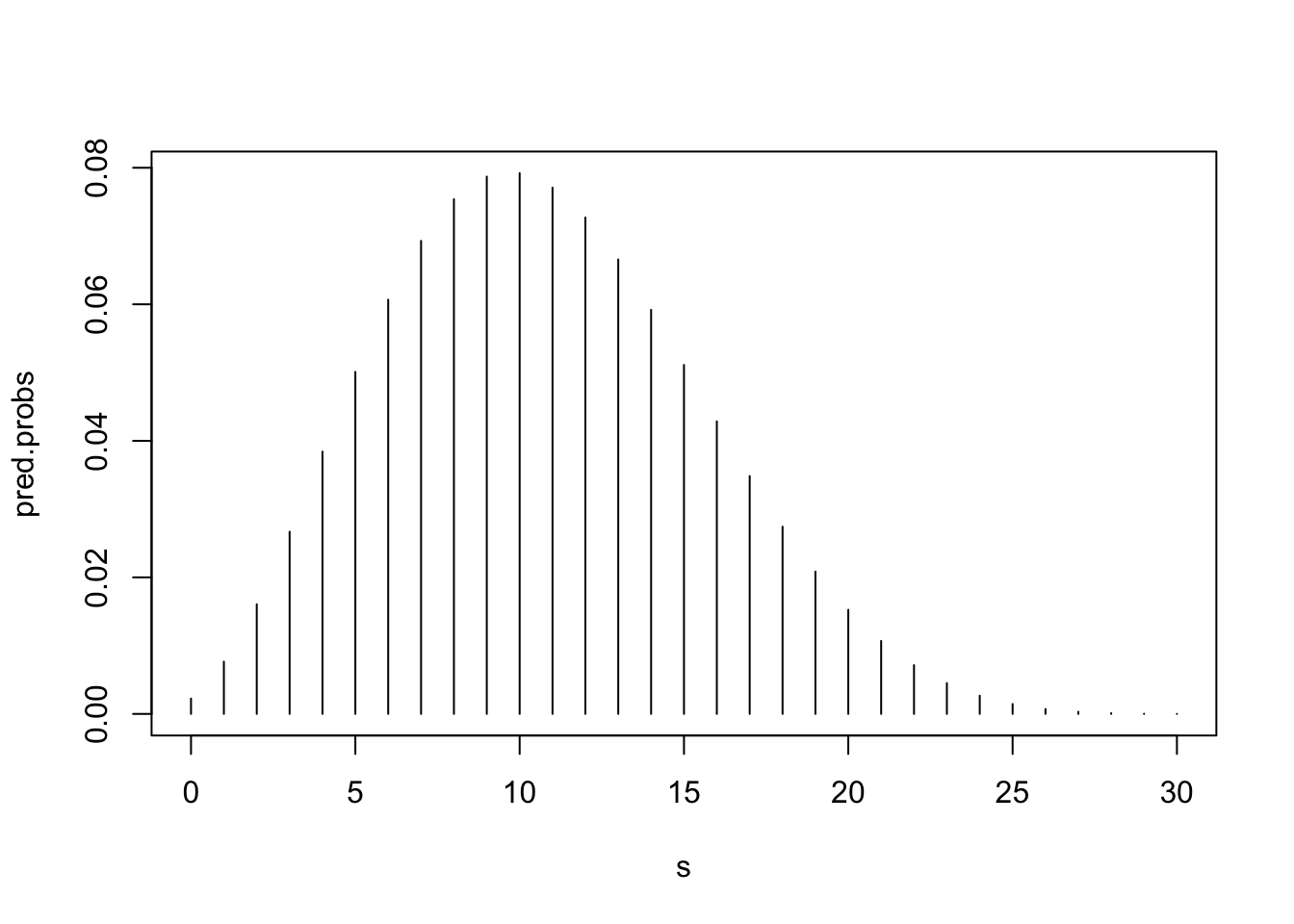
Naravno, moguće je napraviti i izračun vjerojatnosti za svaku pojedinačnu vrijednost, npr. Ako želimo izračunati kolika je vjerojatnost da će u sljedećih 30 dana biti 10 sunčanih dana.
n<-30
s<-10
pred.probs<-pbetap(beta.par, n, s)
pred.probs[1] 0.07920834plot(s, pred.probs, type="h")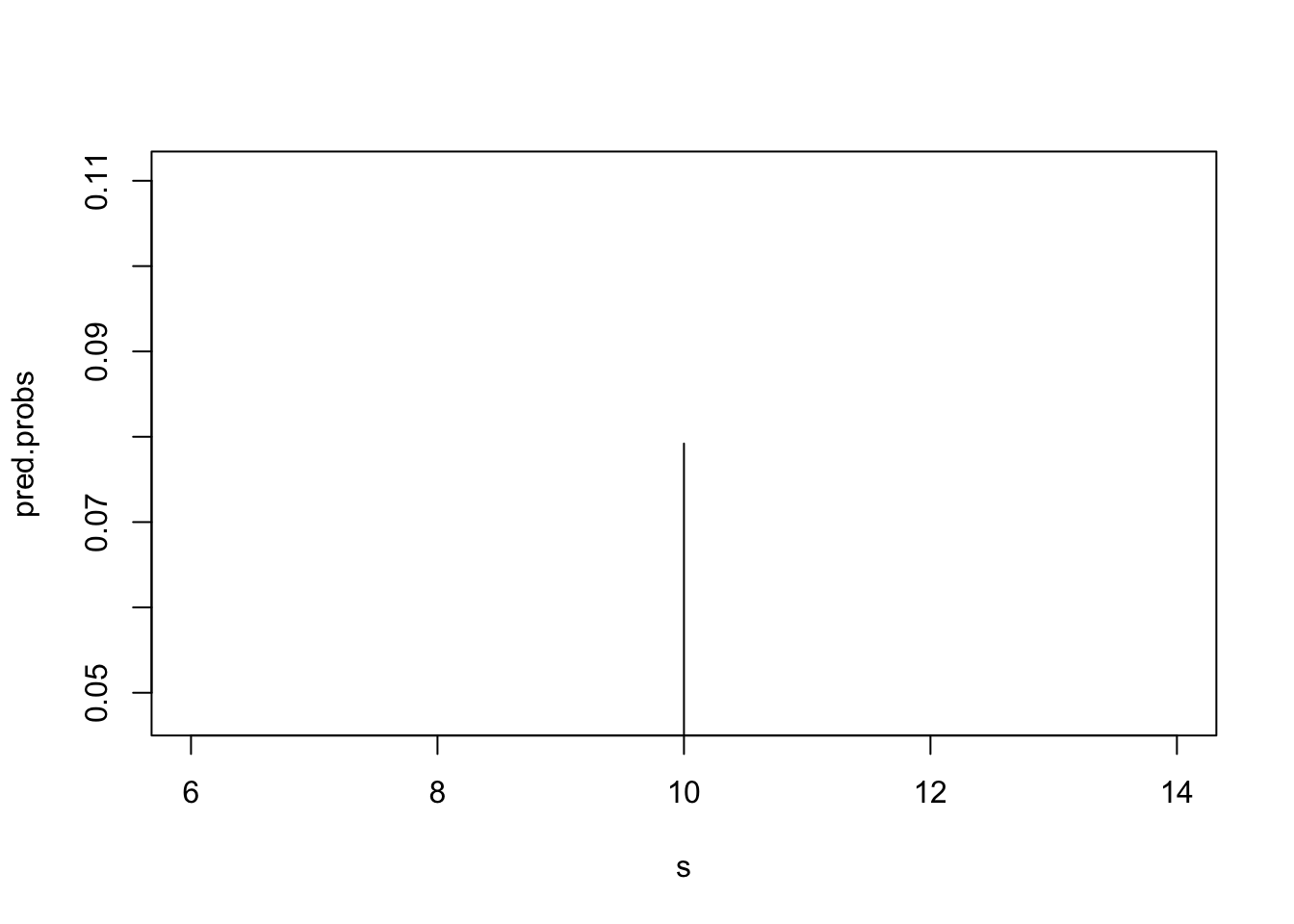
Vjerojatnost za to iznosi oko 8%, što se može činiti malo, ali kada se pogledaju ostali dani, onda je to zapravo najviša vjerojatnost s kojom možemo predvidjeti broj sunčanih dana.
U frekvencijskoj statistici rasponi pouzdanosti imaju središnju vrijednost. Ukoliko se podsjetimo da je u klasičnoj statistici cilj odrediti parametar u populaciji na temelju podataka dobivenih u uzorku, onda nam rasponi pouzdanosti daju važnu informaciju jer se njihova interpretacija temelji na pretpostavci da će se pravi parametar nalaziti u zadanom rasponu u 95% slučajeva ako se mjerenje ponavlja na velikom broju uzoraka.
Ipak, rasponi pouzdanosti su često (pogrešno) interpretirani kao vjerojatnosti (npr. od 95%) da se parametar nalazi u određenom rasponu. To je pogrešna interpretacija, koja zvuči logično, ali koja se ne odnosi na interpretaciju raspona pouzdanosti, već na interpretaciju intervala vjerodostojnosti (engl. credible intervals), koncept vezani za Bayesovu statistiku.
Intervali vjerodostojnosti su iznimno važni u Bayesovoj statistici. Glavna svrha intervala vjerodostojnosti je umanjiti nesigurnost do koje dolazi prilikom procjene nepoznatih parametara. Prema ovoj definiciji, u tom smislu su slični rasponima pouzdanosti. S druge strane, od raspona pouzdanosti se razlikuju jer oni zapravo određuju granice posteriorne distirbucije (recimo, interval vjerodostojnosti od 95% bi označavao 95% središnjih rezultata posteriorne distribucije, odnosno 95% središnjih mogućih rezultata). Postoje dvije glavne metode za određivanje intervala vjerodostojnosti; Highest Density Interval-HDI i Equal-tailed Interval (ETI). Kod HDI fokus je na najvećoj vjerojatnosti i nije potrebna normalna distribucija, dok je kod ETI fokus je na već određenoj vjerojatnosti i potrebna je normalna distribucija.
require(bayestestR)Warning: package 'bayestestR' was built under R version 4.4.1library(dplyr)
library(ggplot2)
posterior<-distribution_normal(1000)
x<-DescTools::MeanCI(posterior)
round(x, digits = 3) mean lwr.ci upr.ci
0.000 -0.062 0.062 ci_hdi <- ci(posterior, method = "HDI")
ci_hdi95% HDI: [-1.97, 1.95]ci_eti <- ci(posterior, method = "ETI")
ci_eti95% ETI: [-1.95, 1.95]posterior%>%
estimate_density(extend=TRUE) %>%
ggplot(aes(x = x, y = y)) +
geom_area(fill = "yellow") +
theme_classic() +
# HDI in blue
geom_vline(xintercept = ci_hdi$CI_low, color = "black", size = 3) +
geom_vline(xintercept = ci_hdi$CI_high, color = "black", size = 3) +
# Quantile in red
geom_vline(xintercept = ci_eti$CI_low, color = "red", size = 1) +
geom_vline(xintercept = ci_eti$CI_high, color = "red", size = 1)Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.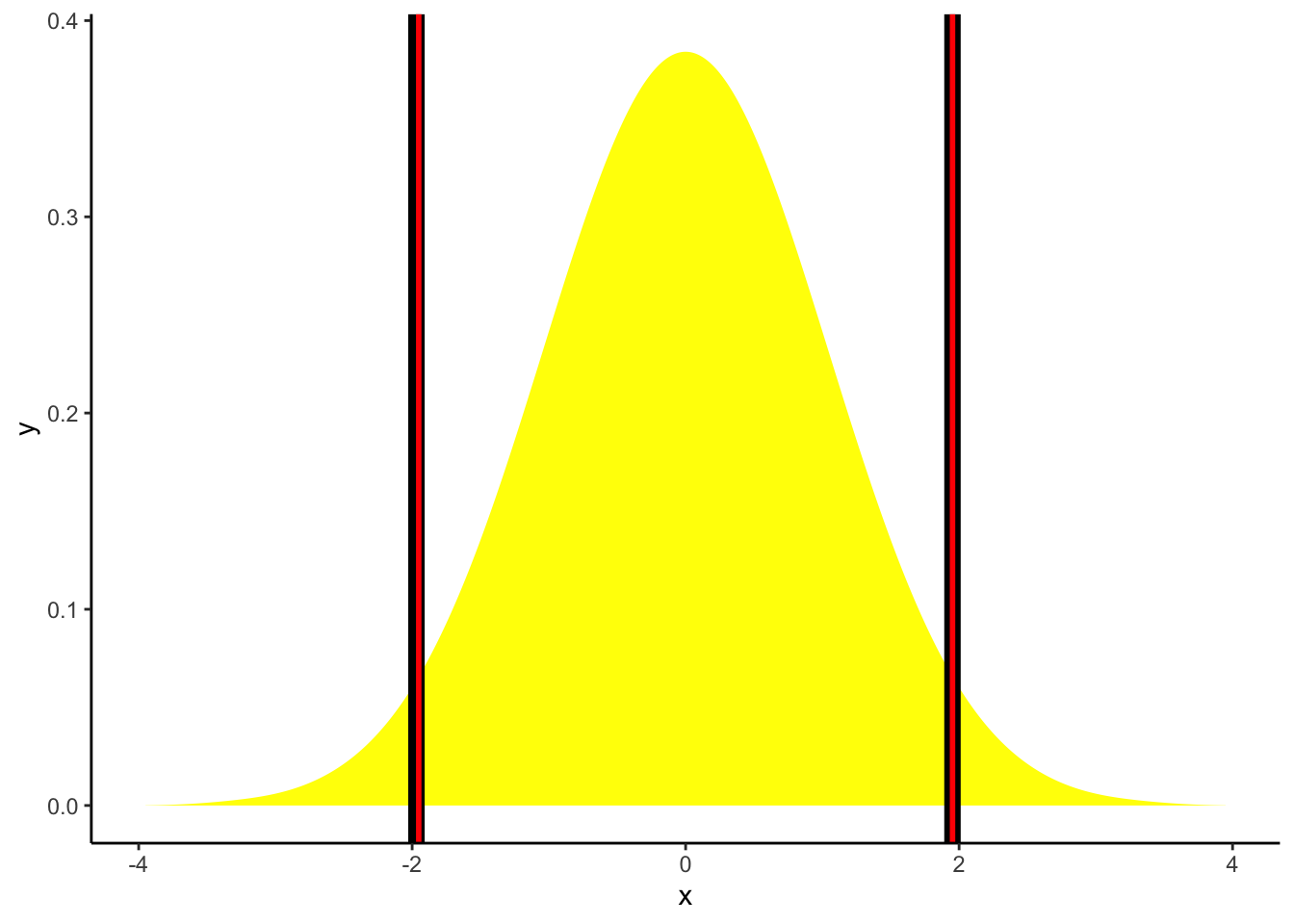
Korištenjem dviju metoda smo dobili identične vrijednosti. S druge strane, ukoliko distribucija značajno odstupa od normalne, rezultati se mogu razlikovati, te je stoga u tim slučajevima preporuka koristiti HDI.
# Generate a beta distribution
posterior <- distribution_beta(1000, 6, 2)
# Compute HDI and Quantile CI
ci_hdi <- ci(posterior, method = "HDI")
ci_hdi95% HDI: [0.47, 0.99]ci_eti <- ci(posterior, method = "ETI")
ci_eti95% ETI: [0.42, 0.96]# Plot the distribution and add the limits of the two CIs
posterior %>%
estimate_density(extend = TRUE) %>%
ggplot(aes(x = x, y = y)) +
geom_area(fill = "yellow") +
theme_classic() +
# HDI in blue
geom_vline(xintercept = ci_hdi$CI_low, color = "black", size = 3) +
geom_vline(xintercept = ci_hdi$CI_high, color = "black", size = 3) +
# ETI in red
geom_vline(xintercept = ci_eti$CI_low, color = "red", size = 1) +
geom_vline(xintercept = ci_eti$CI_high, color = "red", size = 1)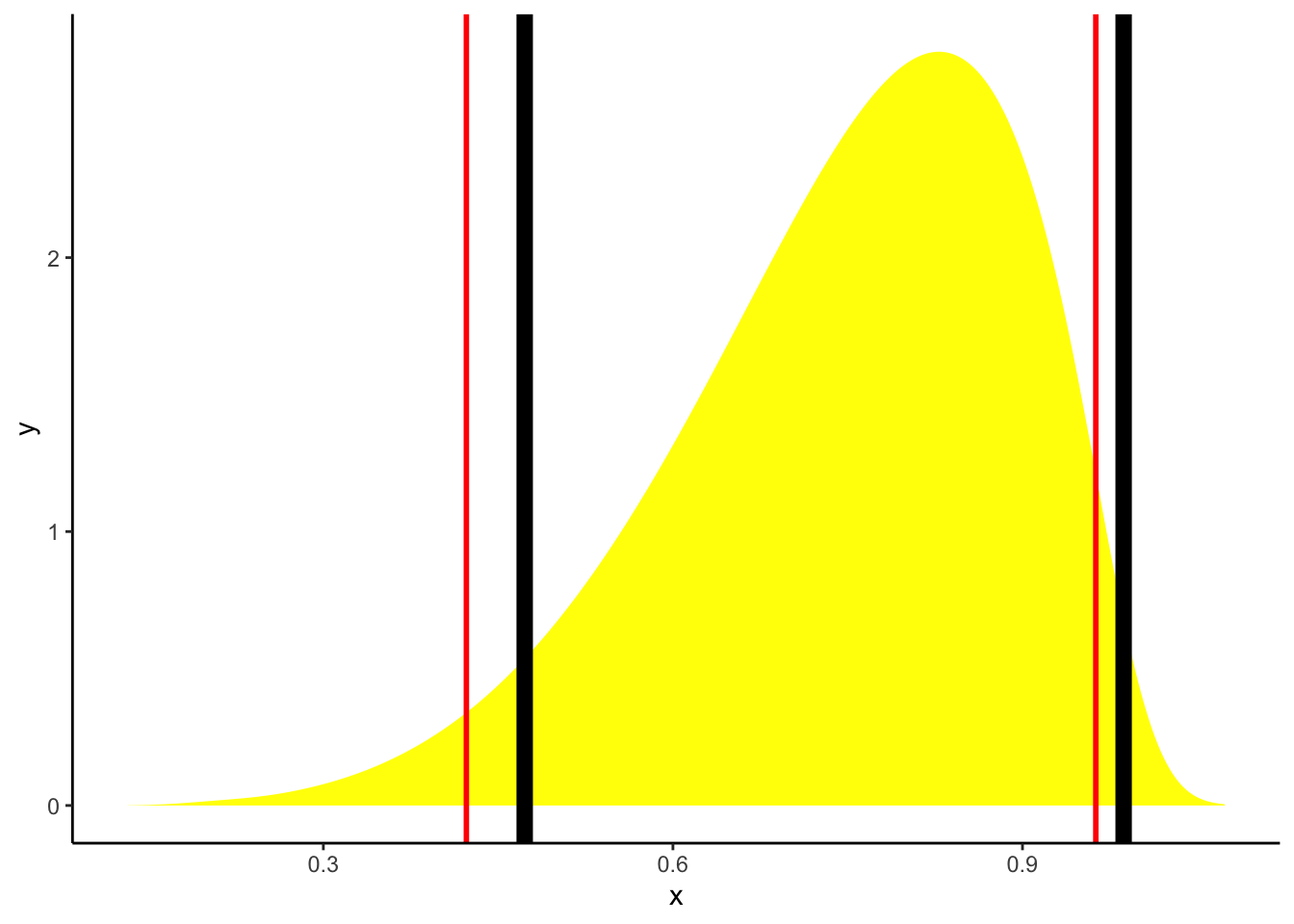
Kod testiranja hipoteza postoje i intervali podržavanja koji ne opisuju samo posteriornu distribuciju, već navode za koji je raspon vrijednosti pronađeno dovoljno dokaza koji bi išli u prilog određenoj hipotezi. Ovaj princip je važan jer daje informaciju o tome koja je hipoteza vjerojatnija. Ukoliko je omjer posteriornih vrijednosti naspram priora 1 ili više, to upućuje da je vjerojatnija alternativna hipoteza, dok vrijednosti ispod 1 upućuju da je vjerojatnija nula hipoteza. Omjeri ovih dviju vjerojatnosti se zovu Bayes faktori, a na sljedećem primjeru ćemo pokazati granične vrijednosti za BF=1 i BF=3 (Bayes faktor od 3 se obično uzima kao snažan dokaz za alternativnu hipotezu).
prior <- distribution_normal(1000, mean = 0, sd = 1)
posterior <- distribution_normal(1000, mean = .5, sd = .3)
si_1 <- si(posterior, prior, BF = 1)Warning: Support intervals might not be precise.
For precise support intervals, sampling at least 40,000 posterior
samples is recommended.si_3 <- si(posterior, prior, BF = 3)Warning: Support intervals might not be precise.
For precise support intervals, sampling at least 40,000 posterior
samples is recommended.ggplot(mapping = aes(x = x, y = y)) +
theme_classic() +
# The posterior
geom_area(fill = "orange",
data = estimate_density(posterior, extend = TRUE)) +
# The prior
geom_area(color = "black", fill = NA, size = 1, linetype = "dashed",
data = estimate_density(prior, extend = TRUE)) +
# BF = 1 SI in blue
geom_vline(xintercept = si_1$CI_low, color = "royalblue", size = 1) +
geom_vline(xintercept = si_1$CI_high, color = "royalblue", size = 1) +
# BF = 3 SI in red
geom_vline(xintercept = si_3$CI_low, color = "red", size = 1) +
geom_vline(xintercept = si_3$CI_high, color = "red", size = 1)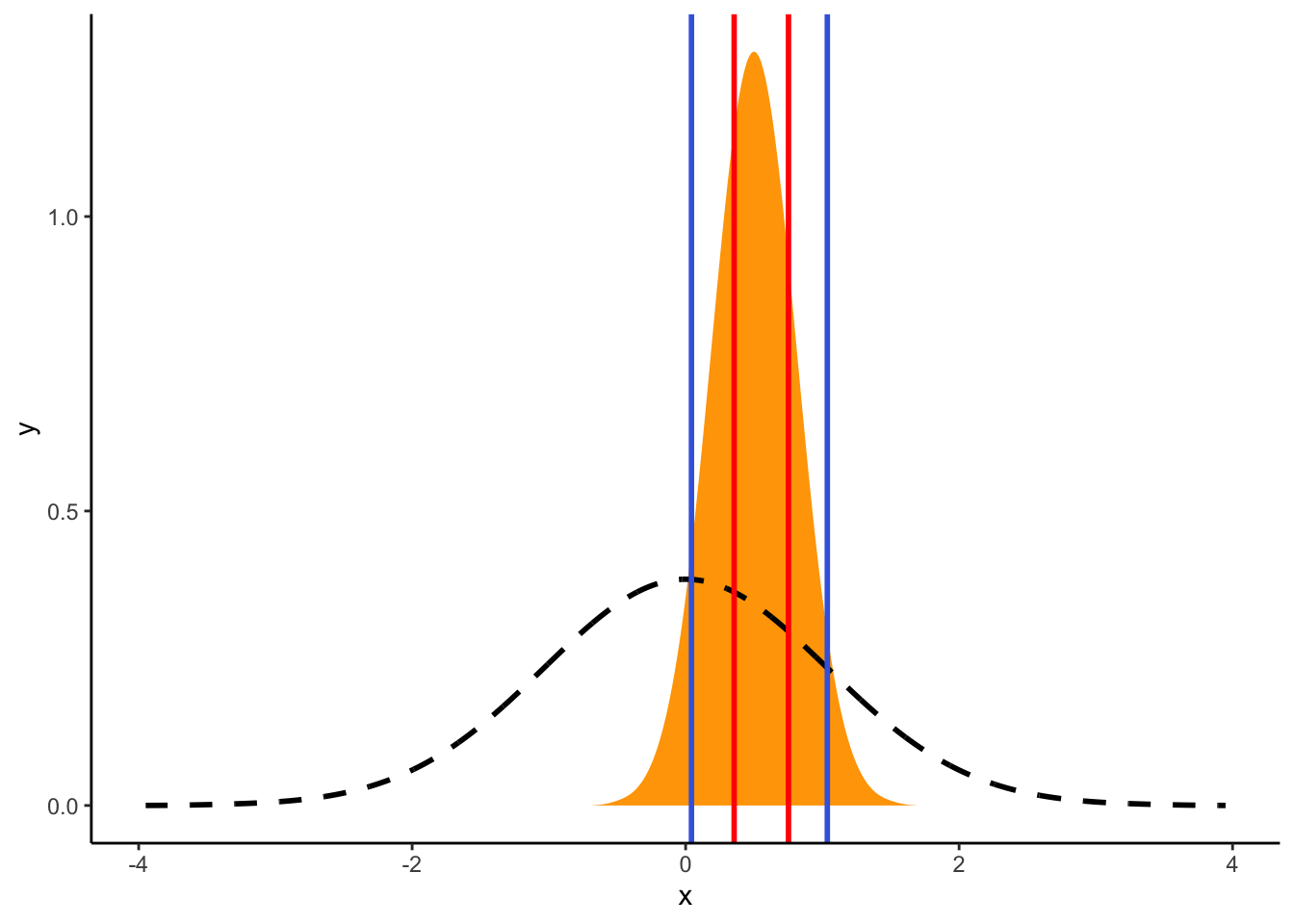
Za razliku od raspona pouzdanosti, kod kojih vrijedi da što je širi raspon, to smo precizniji u procjeni (npr. raspon pouzdanosti od 99% je uvijek širi od raspona pouzdanosti od 95%), u slučajevima podržavajućih raspona vrijedi da, što rezultati bolje podržavaju alternativnu hipotezu, to su intervali uži. Na slici se može vidjeti da je skup vrijednosti za BF=3 (crvene boje) puno uži u odnosu na skup koji podržava BF=1.
To bi bili svi koncepti povezani sa osnovama Bayesove statistike. Sljedeći korak je da napravimo direktnu usporedbu statističkih postupaka između klasičnog i Bayesovog pristupa. Za primjere koristimo podatke i postupke iz drugih poglavlja.
Prvi korak je napraviti usporedbu klasičnim t-testom. Koristit ćemo uzorke mjerenja studenata i studentica iz poglavlja o usporedbi dviju skupina.
studenti_brb <- c(38,41,52,54,57,45,39,34,39,45,66,56,38,56,45)
studentice_brb <- c(56,78,48,38,39,44,56,58,34,78,69,89,68,89,78)
t.test(studentice_brb,studenti_brb, alternative = "two.sided",var.equal = FALSE)
Welch Two Sample t-test
data: studentice_brb and studenti_brb
t = 2.7047, df = 20.603, p-value = 0.01341
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
3.330439 25.602894
sample estimates:
mean of x mean of y
61.46667 47.00000 Rezultati pokazuju kako je razlika između skupina statistički značajna (P=0.013), a 95% raspon pouzdanosti razlike se kreće od 3.3 do 25.6. Dakle, studenti su postigli značajno više rezultate u odnosu na studentice.
Prije provođenja Bayesovog t-testa za nezavisne uzorke, možemo pogledati grafički prikaz za obje skupine.
test_bodovi <- data.frame(skupina = rep(c("Studentice", "Studenti"), each = 15),
bodovi = c(studentice_brb,studenti_brb))
test_bodovi<-fortify(test_bodovi)
attach(test_bodovi)
require(ggplot2)
require(see)Warning: package 'see' was built under R version 4.4.1ggplot(test_bodovi, aes(x = skupina, y =bodovi, fill=skupina))+
geom_violindot(fill_dots = "black", size_dots = 1)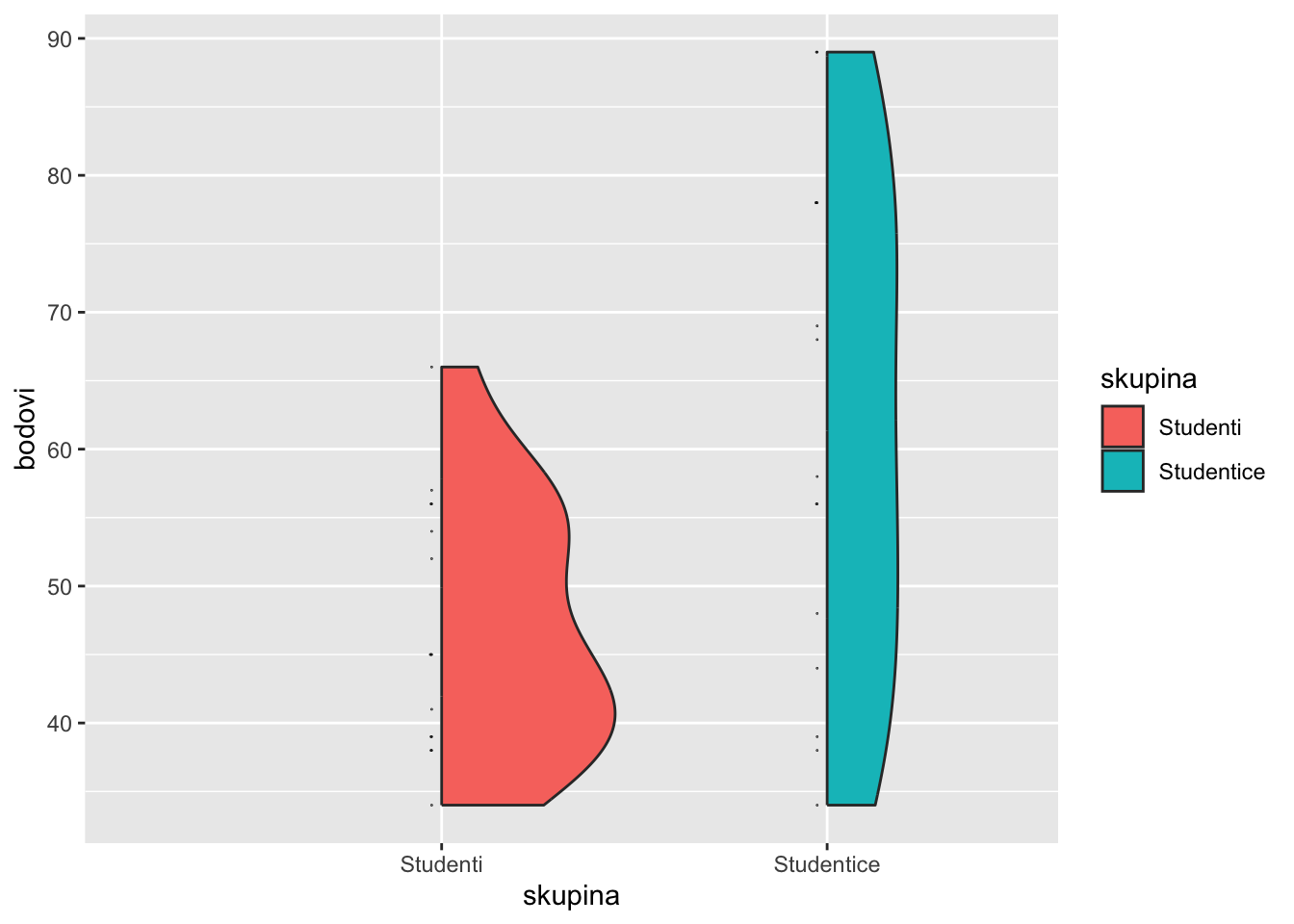
Između skupina postoji značajno preklapanje, ali su distribucije i jako razvučene. Možemo vidjeti kako bi izgledao rezultat s Bayes testom kombinacijom korištenja paketa “BayesFactor” i “bayestestR” Međutim, u ovom slučaju nemamo prior vrijednost. U tim slučajevima zadana vrijednost je ne-informativna prior vrijednost koja smatra da je razlika između skupina 0. (r=0.707) R=0.707 je oznaka raspona u distribuciji vjerojatnosti da će očekivani efekt biti između -2 do +2. Ta vrijednost nije potpuno neinformativna jer ipak postavlja neke granice.
require(BayesFactor)
require(bayestestR)
xx<-ttestBF(studentice_brb, studenti_brb)
summary(xx)Bayes factor analysis
--------------
[1] Alt., r=0.707 : 4.581756 ±0%
Against denominator:
Null, mu1-mu2 = 0
---
Bayes factor type: BFindepSample, JZSbayestestR::describe_posterior(xx)Summary of Posterior Distribution
Parameter | Median | 95% CI | pd | ROPE | % in ROPE | BF | Prior
----------------------------------------------------------------------------------------------------
Difference | 11.97 | [1.60, 22.97] | 98.60% | [-1.62, 1.62] | 0.05% | 4.58 | Cauchy (0 +- 0.71)U ovom slučaju rezultat, Bayes Factor, iznosi BF=4.58. To znači da je 4.58 puta vjerojatnija alternativna hipoteza (da skupine nisu jednake) naspram ništične hipoteze (da nema razlike između skupinama). Dakle, u ovom slučaju možemo reći kako se frekvencijski i Bayesijanski rezultati poklapaju. Oba pristupa usmjeravaju kako postoji razlika između skupina. Također, 95% interval vjerodostojnosti navodi kako je medijan stvarne razlike oko 12 s 95% intervalom vjerodostojnosti (HDI metoda) od 1.6 do oko 22, što je zapravo vrlo širok raspon. Ovdje nailazimo na još dva pojma koja do sada nismo bili spominjali. Prvi se odnosi na vjerojatnost smjera (pd), odnosno je li smjer rezultata negativan ili pozitivan, a kreće se od 50% do 100%
Možemo zaključiti da je smjer rezultata pozitivan s 99%, dakle vrlo visoka vjerojatnost za alternativnu hipotezu.
Drugi koncept se odnosi na ROPE (engl. Region of practical equivalence), a koji označava raspon u kojem se vrijednosti izjednačavaju s nulom, odnosno raspon u kojem nema učinka. U našem slučaju, taj raspon se kreće od -1.62 do 1.62, i može se izračunati koliki je postotak rezultata u tom rasponu. Unutar tog raspona se nalazi 0.37% podataka, što je jako malo i može se zaključiti da razlika između skupina stvarno postoji.
Opet ćemo koristiti primjer iz poglavlja o usporedbama dviju skupina. Mjere tjelesne težine unesemo u dva vektora, a zatim radimo Bayesov t test.
tt_prije <- c(93,95,88,102,98,110,89,92,97,115)
tt_poslije <- c(85,88,80,90,92,99,83,85,90,105)
tezina<-data.frame(cbind(tt_prije, tt_poslije))
tezina tt_prije tt_poslije
1 93 85
2 95 88
3 88 80
4 102 90
5 98 92
6 110 99
7 89 83
8 92 85
9 97 90
10 115 105ttest_tezine <- t.test(tt_prije,tt_poslije,paired = TRUE)
ttest_tezine
Paired t-test
data: tt_prije and tt_poslije
t = 12.362, df = 9, p-value = 5.975e-07
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
6.699455 9.700545
sample estimates:
mean difference
8.2 require(ggplot2)
require(see)
ggplot(tezina, aes(x = tt_prije, y = tt_poslije)) +
geom_violindot(fill_dots = "black", size_dots = 1)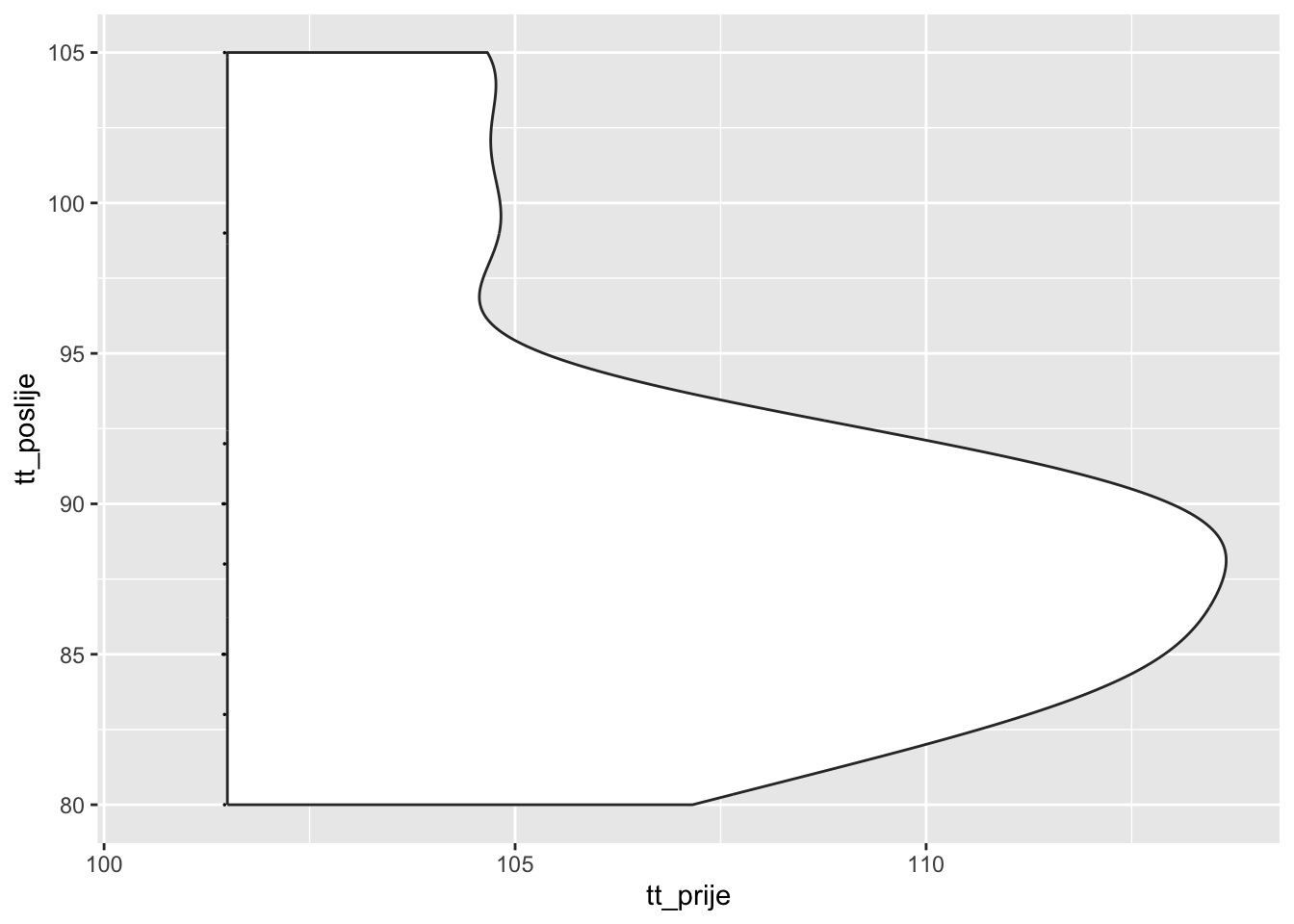
Dakle, prema frekvencijskom pristupu, tjelesna težina se značajno smanjila i to u prosjeku za 8.2 kilograma (od 6.7 do 9.7).
Korištenjem ttestBF naredbe možemo pogledati kako će rezultati izgledati ako primjenimo Bayes t-test za zavisne uzorke.
y<-ttestBF(x=tt_prije,y=tt_poslije, paired=TRUE)
summary(y)Bayes factor analysis
--------------
[1] Alt., r=0.707 : 24159.54 ±0%
Against denominator:
Null, mu = 0
---
Bayes factor type: BFoneSample, JZS bayestestR::describe_posterior(y)Summary of Posterior Distribution
Parameter | Median | 95% CI | pd | ROPE | % in ROPE
---------------------------------------------------------------------
Difference | 8.04 | [6.38, 9.51] | 100% | [-0.21, 0.21] | 0%
Parameter | BF | Prior
------------------------------------------
Difference | 2.42e+04 | Cauchy (0 +- 0.71)Rezultati su slični. Vjerojatnost da je alternativna hipoteza točna iznosi 24159.5 puta u odnosu na nul hipotezu te je razlika oko 8 kilograma s intervalom vjerodostojnosti od 6.4 do 9.6.
To je izračun koji smo dobili na jednom uzorku. Ali, u Bayesijanskoj statistici možemo napraviti i simulaciju na 1000 uzoraka, koji nam mogu odgovoriti na pitanje o tome je li navedena razlika stabilna.
samples = ttestBF(x = tt_prije,
y = tt_poslije, paired=TRUE,
posterior = TRUE, iterations = 1000)
plot(samples[,"mu"])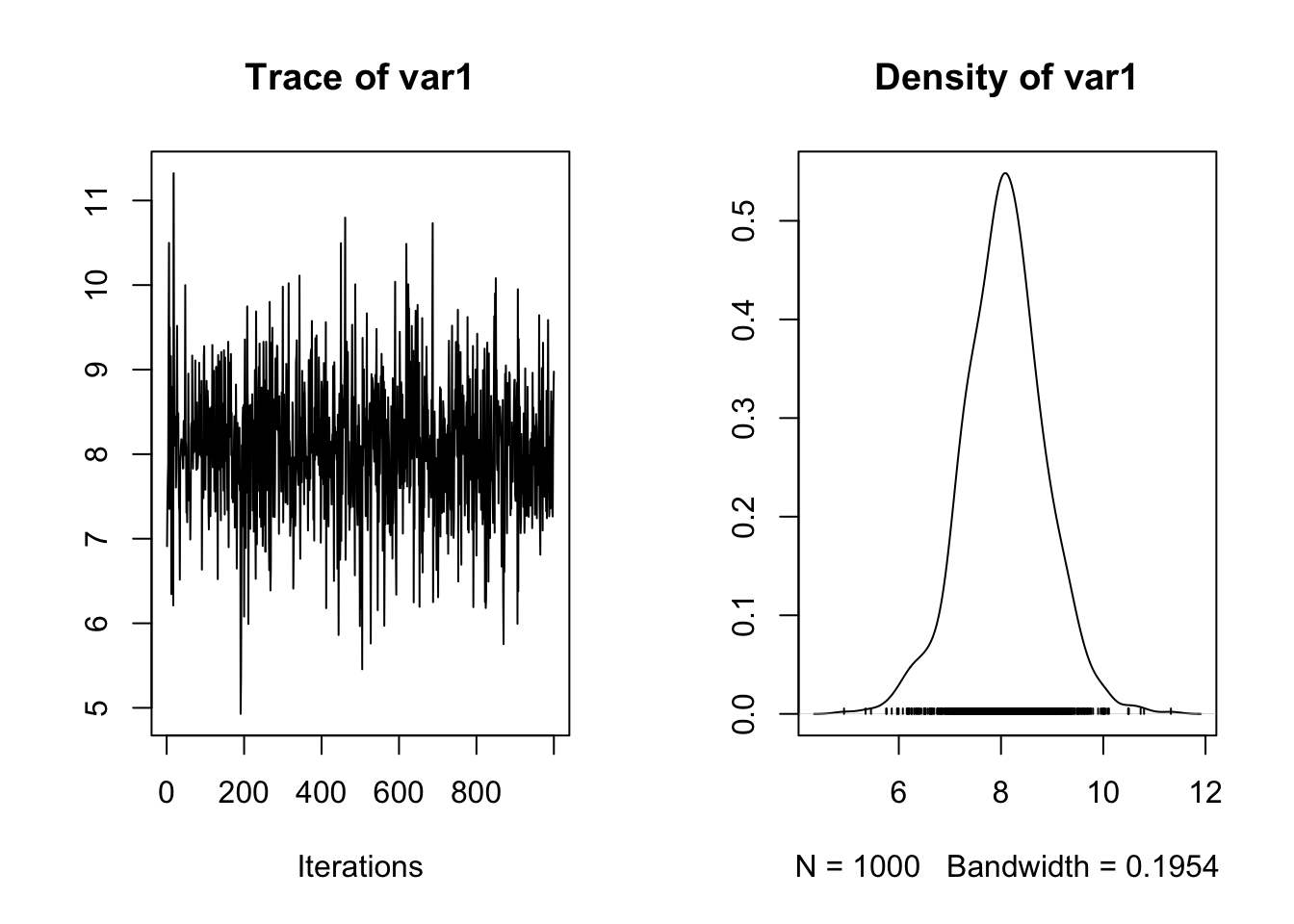
Na prvom grafu možemo isčitati da se velik broj razlika u iteracijama nalazi oko 8 kilograma, iako postoje manja odstupanja. Sljedeći graf prikazuje distribuciju vjerojatnosti za različite veličine razlika. I prema njemu možemo vidjeti da je najveća vjerojatnost za razliku oko 8 kilograma između dva mjerenja.
Za demonstraciju izračuna korelacije posužit ćemo se primjerom iz dataseta “mtcars”. Napravit ćemo (frekvencijsku) analizu povezanosti između varijabli “mpg”- broj milja koji auto može prijeći po galonu goriva i “qsec”- broj sekundi potreban za prijeći četvrtinu milje.
data<-mtcars
attach(data)
cor.test(mpg, qsec)
Pearson's product-moment correlation
data: mpg and qsec
t = 2.5252, df = 30, p-value = 0.01708
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.08195487 0.66961864
sample estimates:
cor
0.418684 plot(qsec, mpg, main="",
xlab="1/4 mile time", ylab="Miles Per Gallon ", pch=19)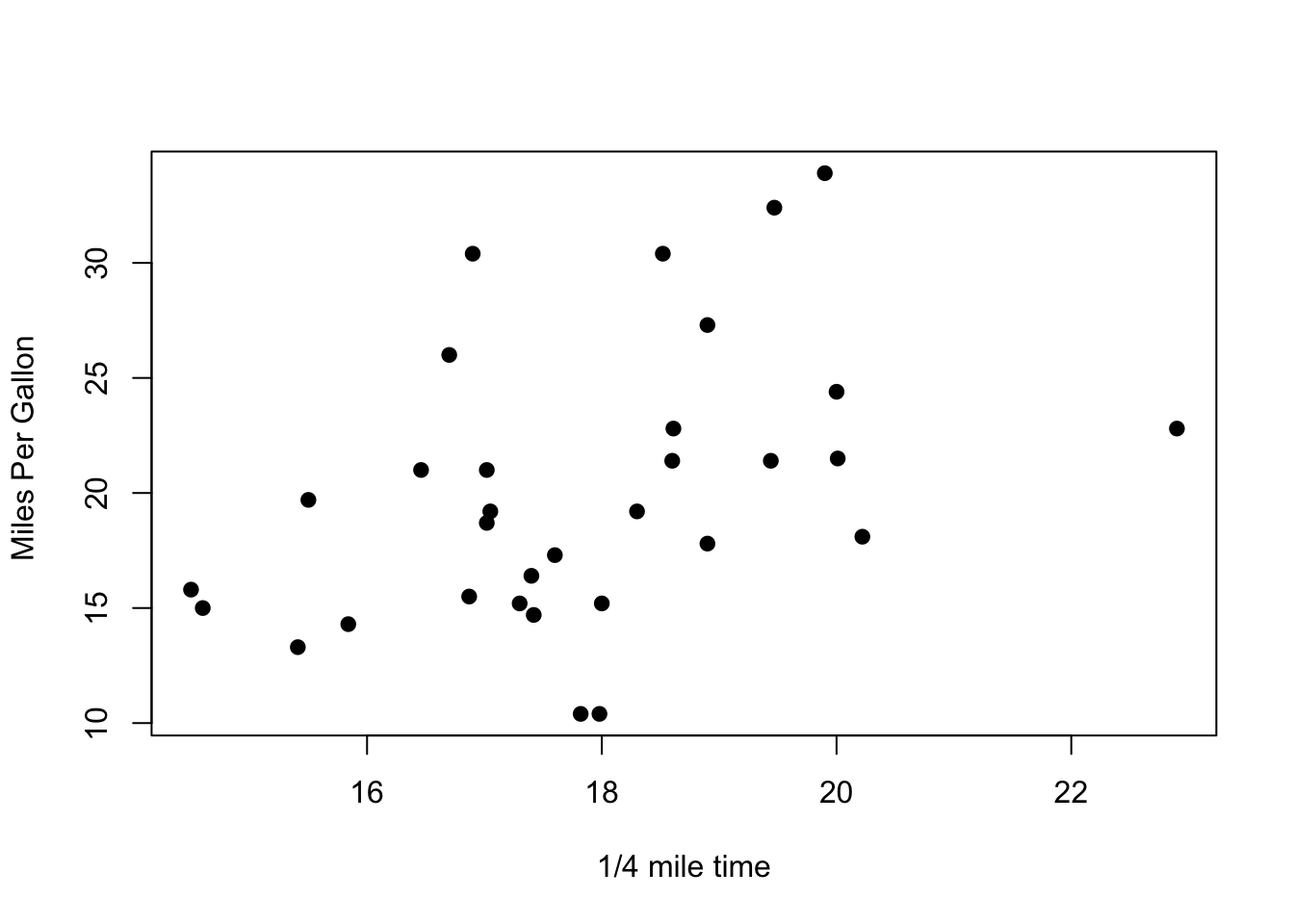
Povezanost je statistički značajna i umjerena. U načelu, što autu treba više vremena da prijeđe četvrtinu milje, to i više milja prijeđe po galonu goriva. U Bayesijanskom pristupu se koristi naredba correlationBF iz Bayesfactor paketa.
Bayescorrelation<-correlationBF(mpg, qsec)
describe_posterior(Bayescorrelation)Summary of Posterior Distribution
Parameter | Median | 95% CI | pd | ROPE | % in ROPE | BF | Prior
---------------------------------------------------------------------------------------------
rho | 0.36 | [0.03, 0.61] | 98.22% | [-0.05, 0.05] | 0.34% | 4.42 | Beta (3 +- 3)U slučaju Bayesijanske statistike korelacija iznosi oko 0.36, što je vrlo blizu koeficijentu korelacije 0.42, koliko je iznosio koeficijent korelacije korištenjem frekvencijskog pristupa. Interval vjerodostojnosti se kreće od oko 0.1 do 0.6, što može značiti malu, ali i gotovo visoku korelaciju, te stoga nismo u potpunosti sigurni je li alternativna hipoteza vjerojatna u odnosu na ništičnu. Sljedeći korak je provjeriti koliko iznosi omjer vjerojatnosti da je alternativna hipoteza vjerojatnija u odnosu na ništičnu, korištenjem Bayes faktora.
bayesfactor(Bayescorrelation)Bayes Factors for Model Comparison
Model BF
[2] (rho != 0) 4.42
* Against Denominator: [1] (rho = 0)
* Bayes Factor Type: JZS (BayesFactor)Dobili smo Bayes faktor od 4.42, što znači da je prema ovim podatcima 4.42 puta vjerojatnija alternativna hipoteza u odnosu na ništičnu hipotezu. Može se primjetiti kako smo u nizu postupaka dobili slične rezultate korištenjem frekvencijske i Bayesijanske statistike. Bayesijanska statistika će u većini slučajeva dati slične rezultate kao i frekvencijski postupci. Oni slučajevi u kojima će postojati značajne razlike će uključivati i različite priore postavljene prema iskustvu te u slučajevima kada želimo dobiti izračune vjerojatnosti događaja za pojedinačne slučajeve.