uzorak1 <- replicate(100, rnorm(10, mean = 100, sd = 5))6.1 Obrada i prikaz kvantitativnih varijabli
Obrada rezultata kvantitativnih varijabli, o kojima će ovdje biti riječi u analizama, odnosi se na one varijable koje pripadaju intervalnim i omjernim mjernim ljestvicama. Različita mjerenja provodimo koristeći kvantitativne varijable kao predmet istraživanja. No, gotovo uvijek u području humanističkih, društvenih ili biomedicinskih istraživanja, analize provodimo isključivo s varijablama na intervalnoj mjernoj ljestvici.
U većini istraživanja pokušavamo vidjeti razlike u takvoj varijabli između dvije ili tri skupine ispitanika. Tada je riječ o modelu razlika između dva ili tri nezavisna uzorka. Isto vrijedi kada imamo istraživački nacrt sa dva ili tri ponovljena mjerenja. U prvom slučaju govorimo o istraživačkom nacrtu sa dva ili tri nezavisna uzorka dok u drugom slučaju govorimo o istraživačkom nacrtu sa dva ili tri ponovljena mjerenja. No, trebamo biti svjesni i preduvjeta za korištenje navedenih metoda a koje se odnose na normalitet raspodjele, veličinu uzorka, jednakosti raspršenja ili varijance, broj ponovljenih mjerenja ili nezavisnih uzoraka i sl.
Parametrijski testovi su robusne metode za koje treba poznavati ograničenja jer se inače izlažemo riziku od donošenja pogrešnih zaključaka i izlažemo se nekoj od statističkih pogrešaka (tipa I ili II tj. alfa i beta pogreška). Parametrijski testovi (t-test, analiza varijance, regresijska analiza) pretpostavljaju veće uzorke ispitanika (približno N>20 ili bolje N>30, iako treba uzeti u obzir niz čimbenika), normalnu raspodjelu predmeta istraživanja, jednakost varijanci, intervalnu ili omjernu mjernu ljestvicu predmeta istraživanja, približno isti broj ispitanika ako imamo više uzoraka. Korištenje parametrijskih testova pretpostavlja promišljanje i zaključivanje, temeljem rezultata na uzorcima, kakvo je stanje u populaciji. Ukoliko nemamo zadovoljene navedene kriterije, tada upotrebljavamo neki od prikladnih neparametrijskih testova, ovisno o istraživačkom nacrtu u istraživanju.
Razumijevanje odnosa između parametrijske i neparametrijske statistike pretpostavlja znanje i metodologije istraživanja. Analize podataka a posebice one koje se odnose na populaciju i zaključivanje o populaciji, zahtijevaju permanentno promišljanje o pogrešci mjerenja kojoj se izlažemo. Zbog navedenog, prilikom analize i prezentacije rezultata istraživanja trebamo navesti i pripadajuće efekte učinka, snagu istraživanja i izračun veličine uzorka.
6.2 Standardna pogreška i interval pouzdanosti
Za pravilnu uporabu t-testa a i drugih statističkih testova, potrebno je dobro razumijevanje odnosa između uzorka i populacije tj. razumijevanje koncepta pogreške mjerenja, pogreške koja se veže uz pojedinačnu aritmetičku sredinu i standardnu devijaciju ali i pogreške koja se veže uz razliku između dviju aritmetičkih sredina tj. standardna pogreška razlike između dvije aritmetičke sredine.
Iz vrijednosti standardne pogreške i njenog razumijevanja proizlazi izračunavanje intervala pouzdanosti (eng. confidence interval) koji se izražava na razini od 95 ili 99%. Interval pouzdanosti je statistika koja predstavlja raspon unutar kojega se uz određenu vjerojatnost nalazi tražena statistička mjera (aritmetička sredina populacije, standardna devijacija populacije i sl.). Razumijevanja intervala pouzdanosti važno je i kod analize složenijih statističkih postupaka poput linearne regresijske analize i drugih multivarijatnih metoda.
Populaciju čine sve jedinke ili entiteti koji imaju neko zajedničko svojstvo ili svojstva. Uzorak je dio populacije koji može imati različite karakteristike i određeni stupanj reprezentativnosti. Zaključivanje o populaciji, ograničeno je metodologijom uzorkovanja, gdje u pravilu slučajnim uzorkovanjem s popriličnom sigurnosti osiguravamo - reprezentativnost uzorka. Prilikom uzimanja slučajnih uzoraka trebamo uzeti u obzir i slučajne varijacije svojstava predmeta mjerenja među uzorcima. Naravno, što je veći varijabilitet ili raspršenje to će biti i veći varijabilitet među uzorcima.
Uzorak je uvijek procjena populacije i uvijek se uz njega veže određena pogreška. Aritmetička sredina uzorka uvijek je procjena i odstupa u određenoj mjeri od prave (populacijske, označava se sa \(\mu\)) aritmetičke sredine. Jednako tako, standardna devijacija uzorka (populacijska devijacija, označava se sa \(\sigma\)).
Standardna devijacija aritmetičkih sredina uzoraka je manja što je uzorak veći. Jednako tako, što je uzorak veći to smo bliži procjeni prave aritmetičke sredine (\(\mu\)) tj. aritmetička sredina uzorka (\(\overline{x}\)) bliža je pravoj aritmetičkoj sredini.
Raspodjela aritmetičkih sredina ići će prema obliku normalne raspodjele, čak i onda kada predmet mjerenja iz populacije nije normalno raspodjeljen. Tu pojavu nazivamo teorem centralne granice.
Petz et al. (2012) navodi i najkraću definiciju navedenog teorema - distribucija aritmetičkih sredina uzoraka približava se normalnoj kako N uzorka raste.
Iz prethodnog vrijedi, što je uzorak veći i manja varijabilnost pojave u populaciji, to je procjena parametara populacije iz uzorka točnija.
Statistički pokazatelj koji je u ovoj raspravi jako važan jest standardna pogreška aritmetičke sredine a koja služi u procjeni odstupanja aritmetičke sredine uzorka od prave aritmetičke sredine. Formula za izračunavanje uzima u obzir upravo navedeno: varijabilitet i veličinu uzorka.
\[\begin{equation}\label{pogreška aritmetičke sredine} SD_{\overline{x}}=\frac{SD}{\sqrt{N}} \end{equation}\]U slijedećem prikazu nalazi se formula za izračunavanje standardne pogreške između dvije aritmetičke sredine. Ona je u osnovi zbroj pogrešaka koje se ‘vežu’ uz jednu i drugu aritmetičku sredinu. Pravilno razumijevanje standardne pogreške razlike između dvije aritmetičke sredine podrazumijeva simulaciju većeg broj uzorkovanja i većeg broj izračuna vrijednosti standardnih pogrešaka između dvije aritmetičke sredine. Prema tome, treba zamisliti i raspodjelu tih vrijednosti.
\[\begin{equation}\label{pogreška razlika između aritmetičkih sredina} SD_{M_{1}-M_{2}}=\sqrt{SD^{2}_{M_{1}}+SD^{2}_{M_{2}}} \end{equation}\]Pri korištenju statističkih testova i interpretaciji p vrijednosti, moramo voditi računa o pogrešci. Tako, u statističkom zaključivanju poznate su dvije pogreške, \(\alpha\) (alfa) pogreška i \(\beta\) (beta) pogreška. Pogreška tipa I (\(\alpha\)) nastaje kad odbacimo nul-hipotezu, koja pretpostavlja kako u populaciji nema razlike između uzoraka, odnosno pogrešno prihvaćamo značajnu p vrijednost i ujedno prihvaćamo postojanje razlike, između recimo, dva uzorka a koja zapravo u populaciji ne postoji. Navedena pogreška predstavlja lažno pozitivni rezultat. Pogreška tipa II (\(\beta\)) odnosi se i na prethodno spomenutu snagu testa (eng. power) koja je jednaka 1 - \(\beta\). Uobičajeno je prihvaćanje snage od 0.8 (80%) što u tom slučaju znači i prihvaćanje pogreške beta od 0.2 (20%). Drugim riječima, izlažemo se riziku od 20% da donesemo zaključak temeljem rezultata kako u populaciji nema razlika a ona u stvarnosti postoji.
Pokušajmo vidjeti kako izgleda simulacija u R jeziku odnosa između uzorka i populacije u pojmovima standardne pogreške i intervala pouzdanosti.
Pretpostavimo 100 puta uzimanje uzorka veličine 10 ispitanika s aritmetičkom sredinom 100 i devijacijom 5. Takav uzorak pridjelit ćemo objektu uzorak1 te sintaksa izgleda na slijedeći način:
Sada ćemo izračunati aritmetičku sredinu uzoraka. Dakle, imamo 10 uzoraka.
xbar <- apply(uzorak1, 2, mean)Raspodjela aritmetičkih sredina svih uzoraka izgleda ovako:
hist(xbar, nclass = 20, col = "grey",
xlab = "Aritmetičke sredine uzoraka veličine 10",
main = "Aritmetičke sredine uzoraka", xlim = c(90, 110))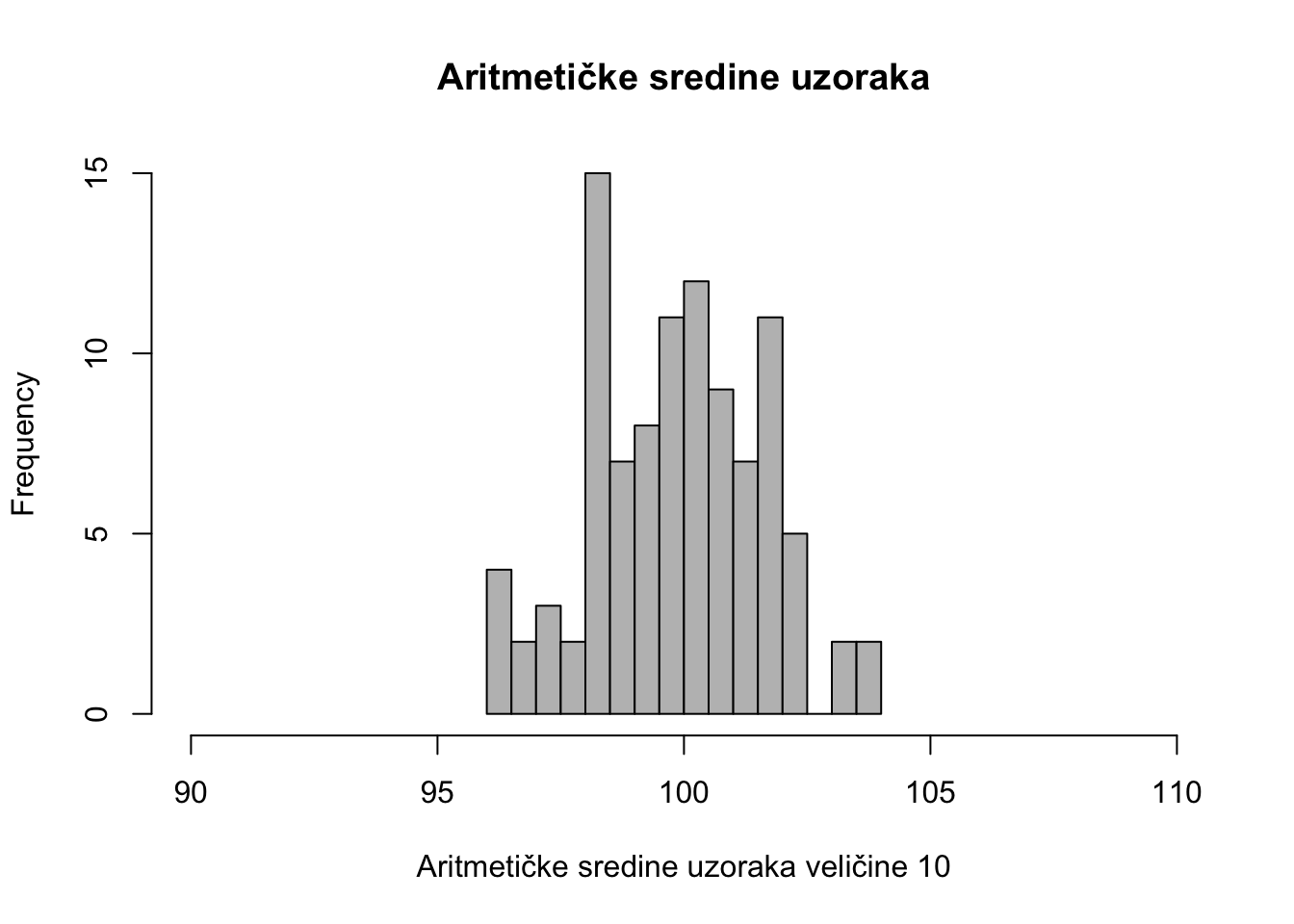
Kao što vidimo aritmetičke sredine uzoraka također opisuju normalnu raspodjelu. Ova pojava je poznata i već spomenuta kao teorem centralne granice.
6.2.0.1 Zadatci: standardna pogreška i raspon pouzdanosti
U carData paketu otvorite skup Blackmore i napravite raspone pouzdanosti oko aritmetičke sredine za varijable dob i excercise, interpretirajte podatke i napravite grafički prikaz za svaku varijablu. Opis skupa se nalazi na sljedećoj poveznici: https://www.rdocumentation.org/packages/carData/versions/3.0-3/topics/Blackmore
U BEPS skupu (https://www.rdocumentation.org/packages/carData/versions/3.0-4/topics/BEPS): Napravite raspone pouzdanosti oko aritmetičke sredine za varijablu Europe, prema varijabli vote. Interpretirajte rezultate i napravite grafički prikaz.
Napravite raspone pouzdanosti oko aritmetičke sredine za varijablu Europe, prema varijabli vote. Komentirajte razlike između raspona pouzdanosti oko medijana i aritmetičke sredine.
U skupu Salaries (https://www.rdocumentation.org/packages/carData/versions/3.0-4/topics/Salaries) odredite tko ima veće plaće prema varijabli discipline, zatim prema spolu i konačno prema varijabli rank.
U carData, odaberite neki skup podataka prema izboru, napravite raspone pouzdanosti prema skupinama prema izboru i interpretirajte podatke.
6.3 Jednostavni t-test ili t-test na jednom uzorku
Jednostavni t-test je provedba t-testa na jednom uzorku gdje se analizira odstupanje aritmetičke sredine uzorka od zamišljene ili hipotetske aritmetičke sredine populacije (\(mu\)). Odstupanje aritmetičke sredine uzorka nekog mjerenja ili istraživačkog nacrta može biti i odstupanje od neke druge referencijalne aritmetičke sredine kao što je aritmetička sredina nekog drugog istraživanja ili aritmetička sredina neke populacije ili uzorka iz literature.
Formula za t-test na jednom uzorku sastoji se od aritmetičke sredine i standardne devijacije uzorka, procijenjene aritmetičke sredine populacije ili referentne vrijednosti nekog mjerenja i broja ispitanika
\[\begin{equation} t=\frac{\overline{X}-\mu}{\frac{s}{\sqrt{N}}} \end{equation}\]Prije primjene t-testa trebamo provjeriti normalitet rasporedjele a što možemo i vizualnom metodom q-q prikazom.
Pretpostavimo mjerenje tjelesne težine na 100 ispitanika koji su postigli aritmetičku sredinu od 80 kg i standardnu devijaciju od 10kg.
uzorak_tezina_1 <- c(rnorm(100, mean = 80, sd = 10))qqnorm(uzorak_tezina_1, pch = 1, frame = FALSE)
qqline(uzorak_tezina_1, col = "steelblue", lwd = 3)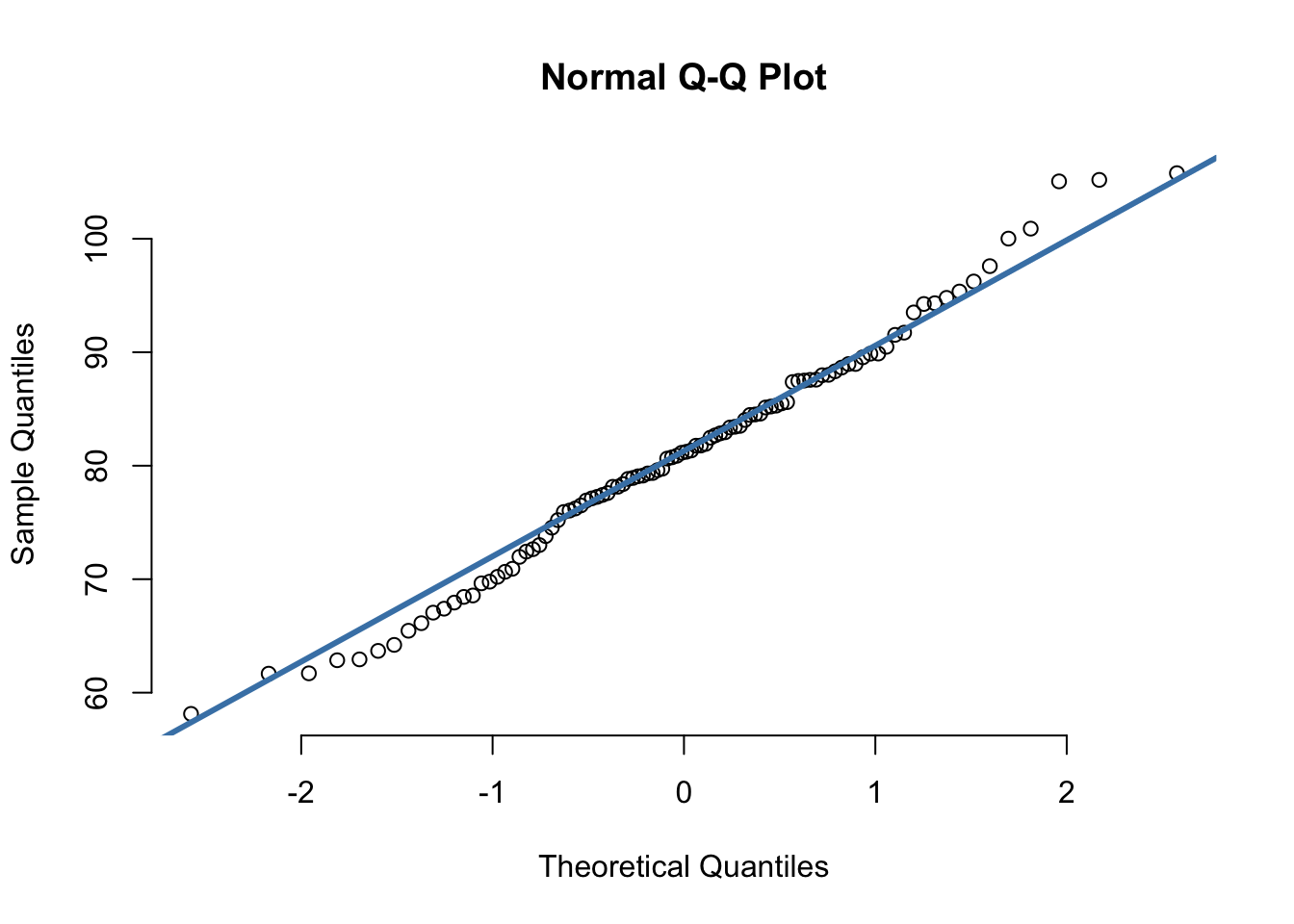
Iz q-q prikaza vidimo kako većina točaka pristaje uz liniju. Uz dodatak raspona, možemo biti još sigurniji.
library(car)Loading required package: carDataqqPlot(uzorak_tezina_1)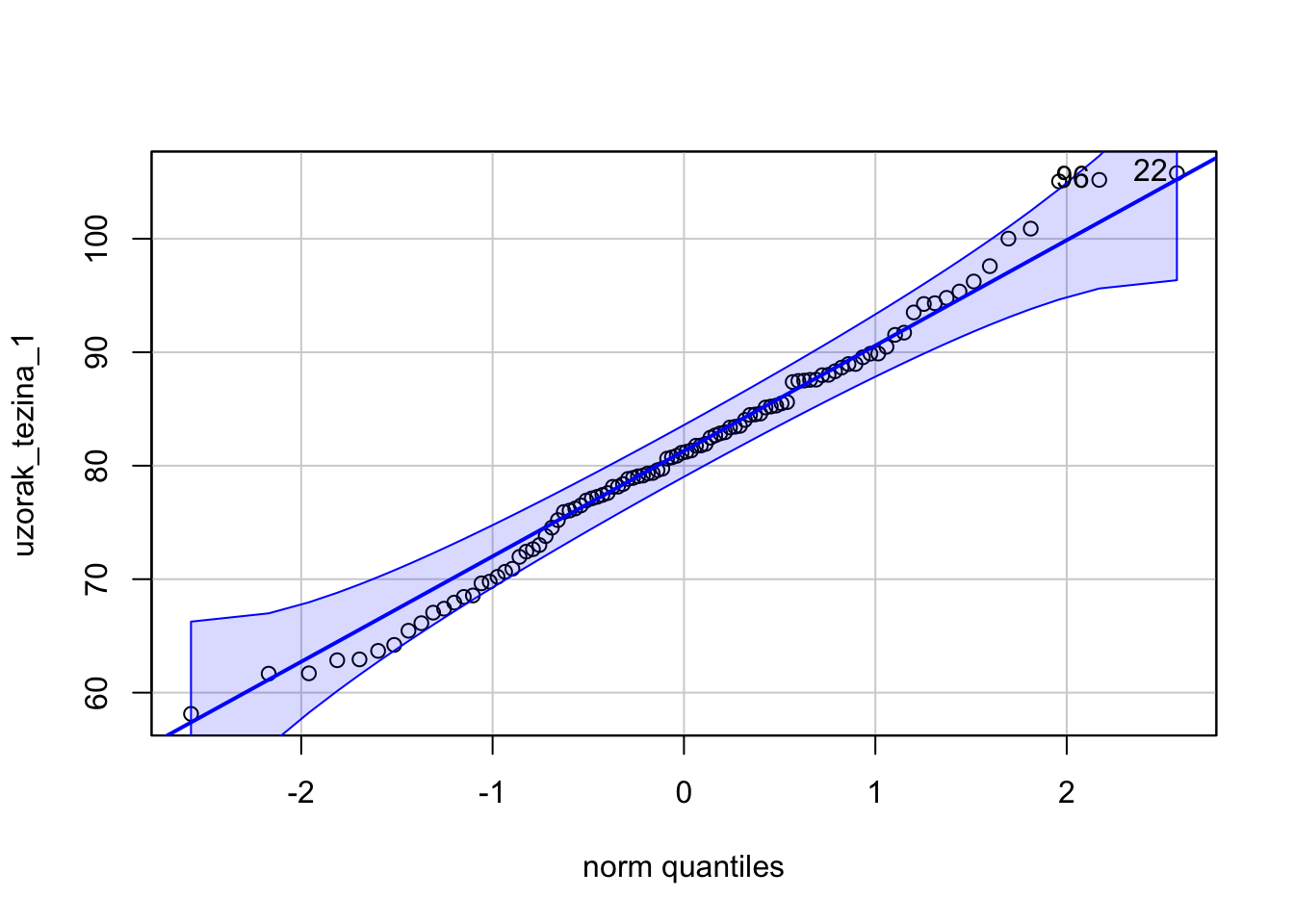
[1] 22 96Ukoliko želimo provjeriti da li navedeni uzorak statistički značajno odstupa od hipotetske vrijednosti od 90.
t.test(uzorak_tezina_1, mu = 90) # Ho: mu = 90
One Sample t-test
data: uzorak_tezina_1
t = -8.8225, df = 99, p-value = 4.028e-14
alternative hypothesis: true mean is not equal to 90
95 percent confidence interval:
79.00060 83.03979
sample estimates:
mean of x
81.0202 6.4 Analiza razlika imeđu dva uzorka (T - test)
T-test je nastao 1908. zahvaljujući kemičaru William Sealy Gossetu koji je radio pod pseudonimom “A Student” u poznatoj pivovari koja proizvodi čuveno pivo Guinness (Boland, 1984).
Gosset je bio zaposlen kao kemičar te je u praksi imao problem s kušanjem određene količine piva te je imao potrebu razviti test, temeljem kojeg će moći iz manjih uzoraka piva procijeniti populaciju. Populacija u tom slučaju je cjelokupno pivo iz koje je izvučen uzorak piva. Upotrebu t-testa, Gosset je objavio u časopisu Biometrika pod pseudonimom Student jer je to bio zahtjev tvrtke Guinness koja nije željela da konkurencija zna što sve rade u svojim pogonima.
T–test pripada parametrijskim testovima ili parametrijskoj statistici. Razlika između parametrijskih i neparametrijskih testova ogleda se u više svojstava a neka od njih su veličina uzorka, mjerna ljestvica, zaključivanje na razini populacije, odstupanje od normalne raspodjele i dr. Parametrijski testovi rabe se na većim uzorcima, intervalnoj ili omjernoj mjernoj ljestvici te je u pravilu zaključivanje o populaciji iz parametara uzorka čiji rezultati ne odstupaju od normalne raspodjele.
Neparametrijski testovi su upravo suprotno tj. koriste se na manjim uzorcima (N<20), na varijablama koje su na nominalnoj ili ordinalnoj mjernoj ljestvici te nas u pravilu ne zanima odnos između uzorka i populacije tj. zaključivanje (generalizacija) na populacijskoj razini. Pri primjeni neparametrijskih testova nije važno koliko raspodjela odstupa od normalne ili koliko je i u kojem smjeru izražena asimetričnost raspodjele.
T-test za nezavisne uzorke koristi se u modelu podataka kada želimo dvije različite skupine ispitanika (ili uzoraka) usporediti u nekoj varijabli koja je kvantitativna, kontinuirana. (u pravilu na intervalnoj ili omjernoj mjernoj ljestvici).
Opća formula za t-test za nezavisne uzorke u brojniku ima razliku između dvije aritmetičke sredine a u nazivniku standardnu pogrešku razlika između dvije aritmetičke sredine.
\[\begin{equation} t=\frac{\overline{X_{1}}-\overline{X_{2}}}{\sqrt{SD^{2}_{1}/n1+SD^{2}_{2}/n2}} \end{equation}\]Opći model sintakse za primjenu t-testa za nezavisne uzorke je: t.test(y~x) tj. y varijabla je kontinuirana varijabla, dok je x varijabla grupirajuća varijabla ili nezavisna varijabla. U grupirajućoj, nezavisnoj varijabli su određene vrijednosti ili kodovi koji označavaju dva nezavisna uzorka. No, treba biti oprezan, jer kada je riječ o dvije nezavisne varijable koje su tako i unesene u datoteku, tada je sintaksa t.test(x,y)
Jedna od pretpostavki za korištenje t testa za nezavisne uzorke je i jednakost varijanci. Jednakost varijanci se odnosi na podjednako variranje rezultata oko artimetičke sredine grupe u obje skupine, te ako ta pretpostavka nije zadovoljena onda student t-test može dati pogrešne rezultate. Pretpostavka uporabe t-testa je usporedba dva uzorka koji dolaze iz iste populacije. Nul hipoteza u tom slučaju je - dvije aritmetičke sredine su jednake a alternativna hipoteza kako te dvije aritmetičke sredine nisu jednake.
U praksi se mogu koristiti dvije inačice t - testa: 1) Student t-test 2) Welch t-test. Welch t-test se koristi kada varijance nisu jednake.
Provjeru jednakosti varijance između dva uzorka u R-u možemo napraviti vrlo jednostavno pomoću funkcije var.test.
prvi_uzorak <- rnorm(100,mean=100, sd=10)
drugi_uzorak <- rnorm(200,mean=100,sd=15)
var.test(prvi_uzorak,drugi_uzorak)
F test to compare two variances
data: prvi_uzorak and drugi_uzorak
F = 0.363, num df = 99, denom df = 199, p-value = 6.683e-08
alternative hypothesis: true ratio of variances is not equal to 1
95 percent confidence interval:
0.2603048 0.5163802
sample estimates:
ratio of variances
0.3629959 Iz navedenog primjera vidljiv je značajan F test (p<0.01) i varijance nisu jednake.
Ako varijance nisu jednake, tada trebamo u općoj formuli ili funkciji t.test napisati i argument var.equal = FALSE.
# Opća formula za t-test za nezavisne uzorke
# t.test(x, y, alternative = "two.sided", var.equal = FALSE)
#Primjer: usporedba broja bodova koji su postigli studenti i studentice
#dva nezavisna uzorka
studenti_brb <- c(38,41,52,54,57,45,39,34,39,45,66,56,38,56,45)
studentice_brb <- c(56,78,48,38,39,44,56,58,34,78,69,89,68,89,78)
#primjena t-test za nezavisne uzorke
t.test(studentice_brb,studenti_brb, alternative = "two.sided",var.equal = FALSE)
Welch Two Sample t-test
data: studentice_brb and studenti_brb
t = 2.7047, df = 20.603, p-value = 0.01341
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
3.330439 25.602894
sample estimates:
mean of x mean of y
61.46667 47.00000 Navedene varijable moguće je prebaciti u format data frame tj. redovi ispitanici a stupci varijable. To je moguće pomoću funkcije data.frame.
test_bodovi <- data.frame(
skupina = rep(c("Studentice", "Studenti"), each = 15),
bodovi = c(studentice_brb, studenti_brb)
)
#prikaz rezultata
print(test_bodovi) skupina bodovi
1 Studentice 56
2 Studentice 78
3 Studentice 48
4 Studentice 38
5 Studentice 39
6 Studentice 44
7 Studentice 56
8 Studentice 58
9 Studentice 34
10 Studentice 78
11 Studentice 69
12 Studentice 89
13 Studentice 68
14 Studentice 89
15 Studentice 78
16 Studenti 38
17 Studenti 41
18 Studenti 52
19 Studenti 54
20 Studenti 57
21 Studenti 45
22 Studenti 39
23 Studenti 34
24 Studenti 39
25 Studenti 45
26 Studenti 66
27 Studenti 56
28 Studenti 38
29 Studenti 56
30 Studenti 45Vizualizacija razlika između skupina moguće je na više načina. Najjednostavniji način je pomoću funkcije boxplot.
boxplot(mpg~am,data=mtcars, main="Automobili - prijenos",
xlab="Transmission", ylab="Miles Per Gallon")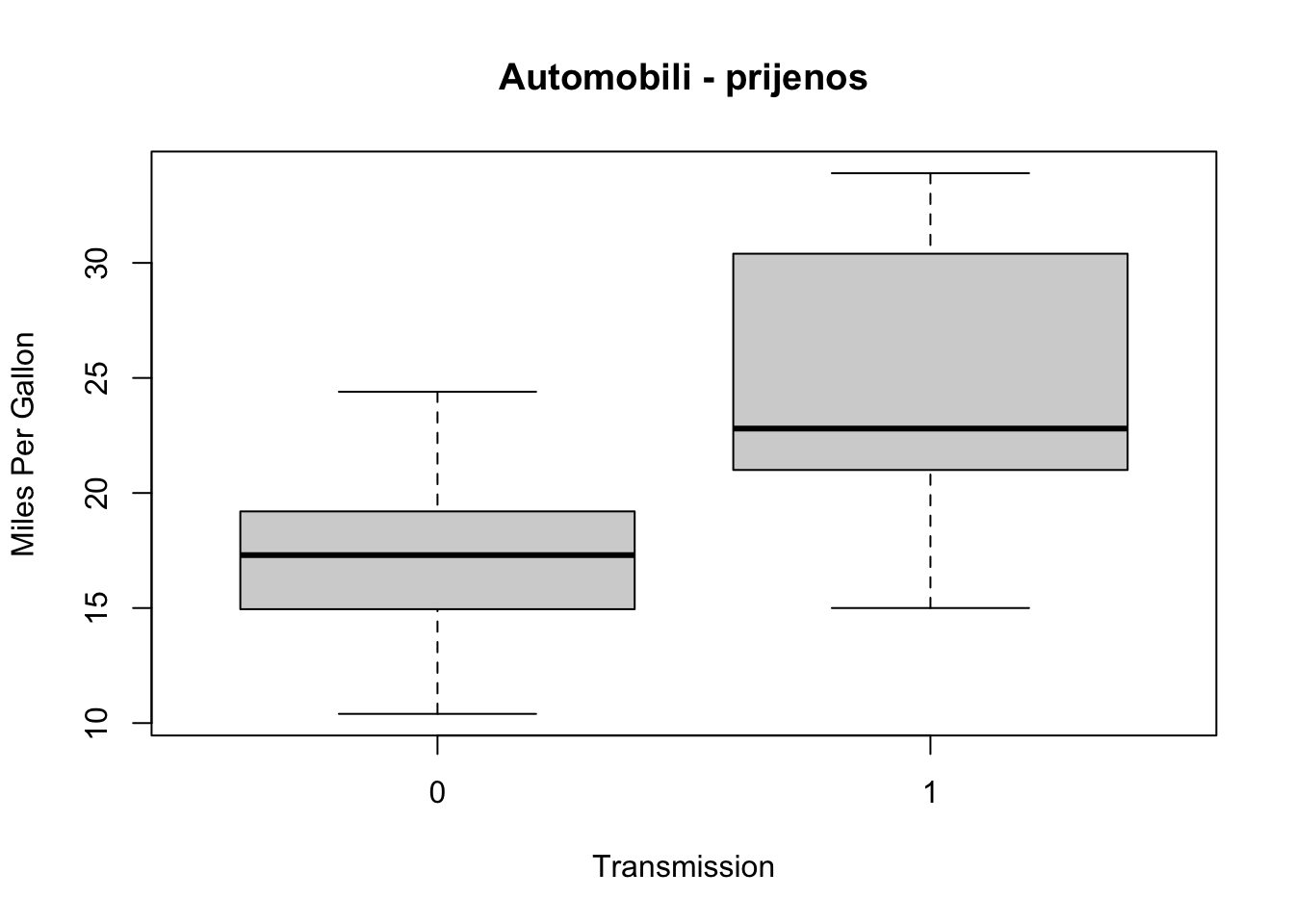
Vizualizacija rezultata pomoću paketa ggpubr koji omogućava prilagođene slikovne prikaze za potrebe znanstvenih publikacija.
library("ggpubr")Loading required package: ggplot2ggboxplot(test_bodovi, x = "skupina", y = "bodovi",
color = "skupina", palette = c("#00AFBB", "#E7B800"),
ylab = "Bodovi", xlab = "Skupina")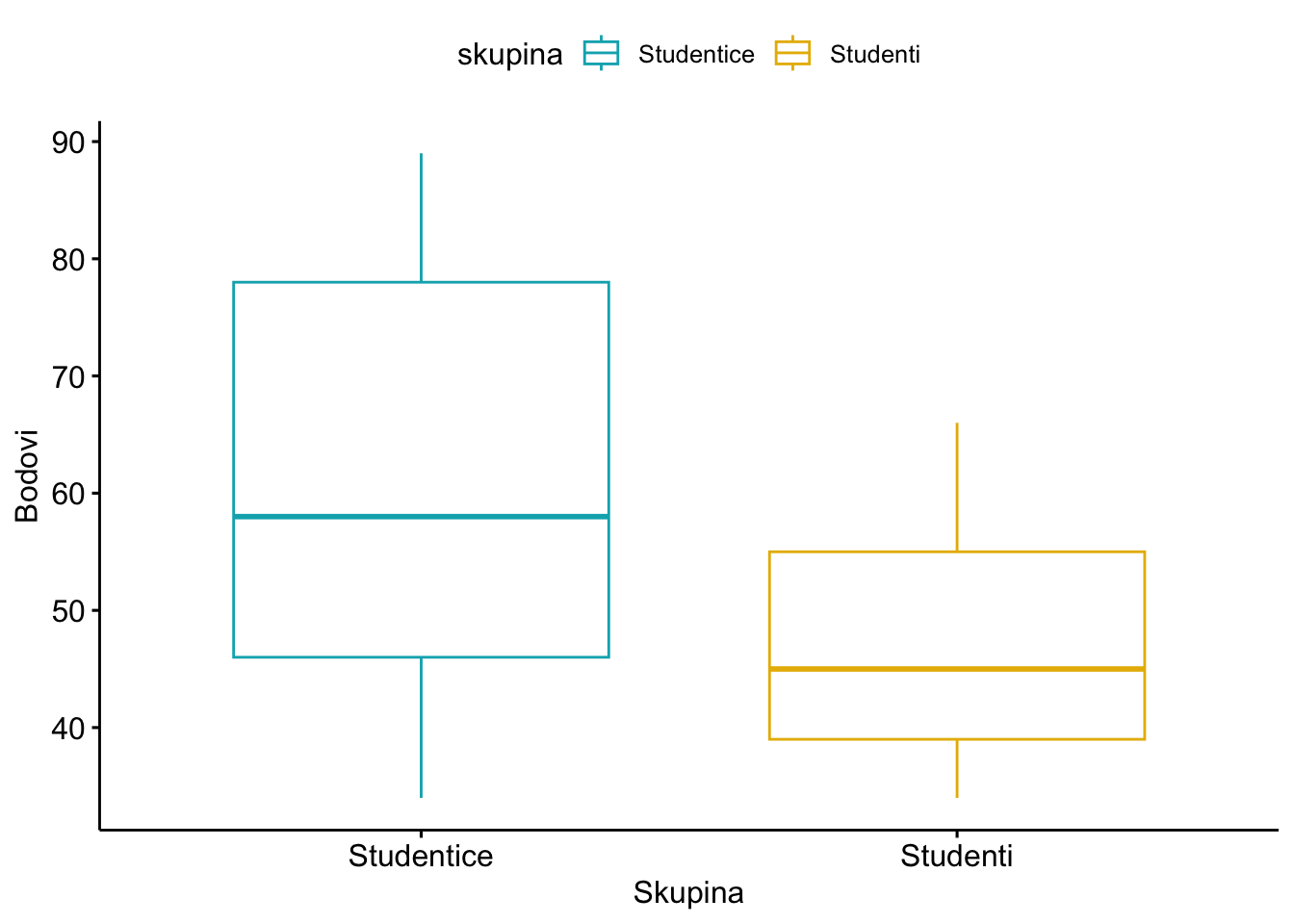
Za provjeru mogućnosti korištenja t-testa možemo napraviti i Shapiro Wilk test normaliteta. U prethodnom slučaju to bi bilo na slijedeći način:
studenti_brb <- c(38,41,52,54,57,45,39,34,39,45,66,56,38,56,45)
shapiro.test(x=studenti_brb)
Shapiro-Wilk normality test
data: studenti_brb
W = 0.92899, p-value = 0.2635Univarijatni i multivarijatni Shapiro Wilk test može se efikasno napraviti i pomoću paketa rstatix (Kassambara, 2023b). O mogućnostima navedenog paketa biti će dalje riječi kroz primjere.
6.5 Analiza razlika imeđu dva zavisna uzorka (T - test)
Dva zavisna uzorka ili ponovljeno mjerenje na istom uzorku ispitanika najčešće se testiraju pomoću t-testa za zavisne uzorke (paired t-test).
Formula koja se koristi za dva zavisna uzorka kada je potrebno izračunati t-vrijednost na malim uzorcima:
\[\begin{equation} t=\frac{M_{D}}{SD_{M_{D}}} \end{equation}\]Opća formula za izračunavanje t testa za zavisne uzorke u R jeziku primjenjuje se na slijedeći način.
#t.test(y1,y2,paired=TRUE) # where y1 & y2 are numeric Uzmimo primjer testiranja lijeka za hipertenziju. Utvrdili smo na 1000 ispitanika tlak od prosječno 155 mmHg a nakon primjene testnog lijeka tlak se na istih 1000 ispitanika spustio na prosječno 145 mmHg. U prvom mjerenju standardna devijacija bila je 12 mmHg a u drugom mjerenju 10 mmHg. Postavlja se pitanje da li je prosječno tlak statistički značajno manji u drugom mjerenju nakon primjene novog lijeka?
prije_lijeka <- c(rnorm(1000, mean = 155, sd = 12))
poslije_lijeka <- c(rnorm(1000, mean = 145, sd = 10))
t.test(prije_lijeka,poslije_lijeka,paired = TRUE)
Paired t-test
data: prije_lijeka and poslije_lijeka
t = 19.55, df = 999, p-value < 2.2e-16
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
8.73583 10.68519
sample estimates:
mean difference
9.710508 Pogledajmo dalje na još jednom primjeru. Možemo uzeti primjer mjerenja tjelesne težine deset ispitanika prije i poslije tretmana dijete.
# Mjere tjelesne težine unesemo u dva vektora
tt_prije <- c(93,95,88,102,98,110,89,92,97,115)
tt_poslije <- c(85,88,80,90,92,99,83,85,90,105)
# navedena dva vektora prebacimo u oblik okvira s podacima
tezina_frame <- data.frame(
skupina = rep(c("prije", "poslije"), each = 10),
tezina = c(tt_prije, tt_poslije)
)
# provjera kako izgleda okvir s podacima (data.frame)
# ili matrica s podacima u dvije varijable i 10 ispitanika
print(tezina_frame) skupina tezina
1 prije 93
2 prije 95
3 prije 88
4 prije 102
5 prije 98
6 prije 110
7 prije 89
8 prije 92
9 prije 97
10 prije 115
11 poslije 85
12 poslije 88
13 poslije 80
14 poslije 90
15 poslije 92
16 poslije 99
17 poslije 83
18 poslije 85
19 poslije 90
20 poslije 105Deskriptivnu statistiku i dio inferencijalne statistike (t-test, odstupanje raspodjele od normalne) možemo dobiti na više načina a za potrebe t-testa ovdje ćemo demonstrirati pakete: pych (William Revelle, 2023), dplyr (Wickham et al., 2022) i rstatix (Kassambara, 2023b).
Pomoću psych paketa možemo jednostavno dobiti opisnu statistiku prema dva ponovljena mjerenja.
library(psych)
describeBy(tezina_frame$tezina, group = tezina_frame$skupina)
Descriptive statistics by group
group: poslije
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 10 89.7 7.54 89 89 5.93 80 105 25 0.69 -0.71 2.39
------------------------------------------------------------
group: prije
vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 10 97.9 8.82 96 97 7.41 88 115 27 0.7 -0.94 2.79Sličan prikaz možemo dobiti pomoću dplyr paketa i “pipe” operatora %>%.
library(dplyr)
group_by(tezina_frame,skupina) %>%
summarise(
count = n(),
mean = mean(tezina, na.rm = TRUE),
sd = sd(tezina, na.rm = TRUE)
)# A tibble: 2 × 4
skupina count mean sd
<chr> <int> <dbl> <dbl>
1 poslije 10 89.7 7.54
2 prije 10 97.9 8.82Slično kao i u primjeru t testa za nezavisne uzorke, možemo napraviti pomoću ggpubr (Kassambara, 2023a) koji priređuje slikovne prikaze spremne za objavu u časopisima te tako i u ovom primjeru slijedeći slikovni prikaz:
library(ggpubr)
ggboxplot(tezina_frame, x = "skupina", y = "tezina",
color = "skupina", palette = c("#00AFBB", "#E7B800"),
order = c("prije", "poslije"),
ylab = "Tjelesna težina (kg)", xlab = "Skupina")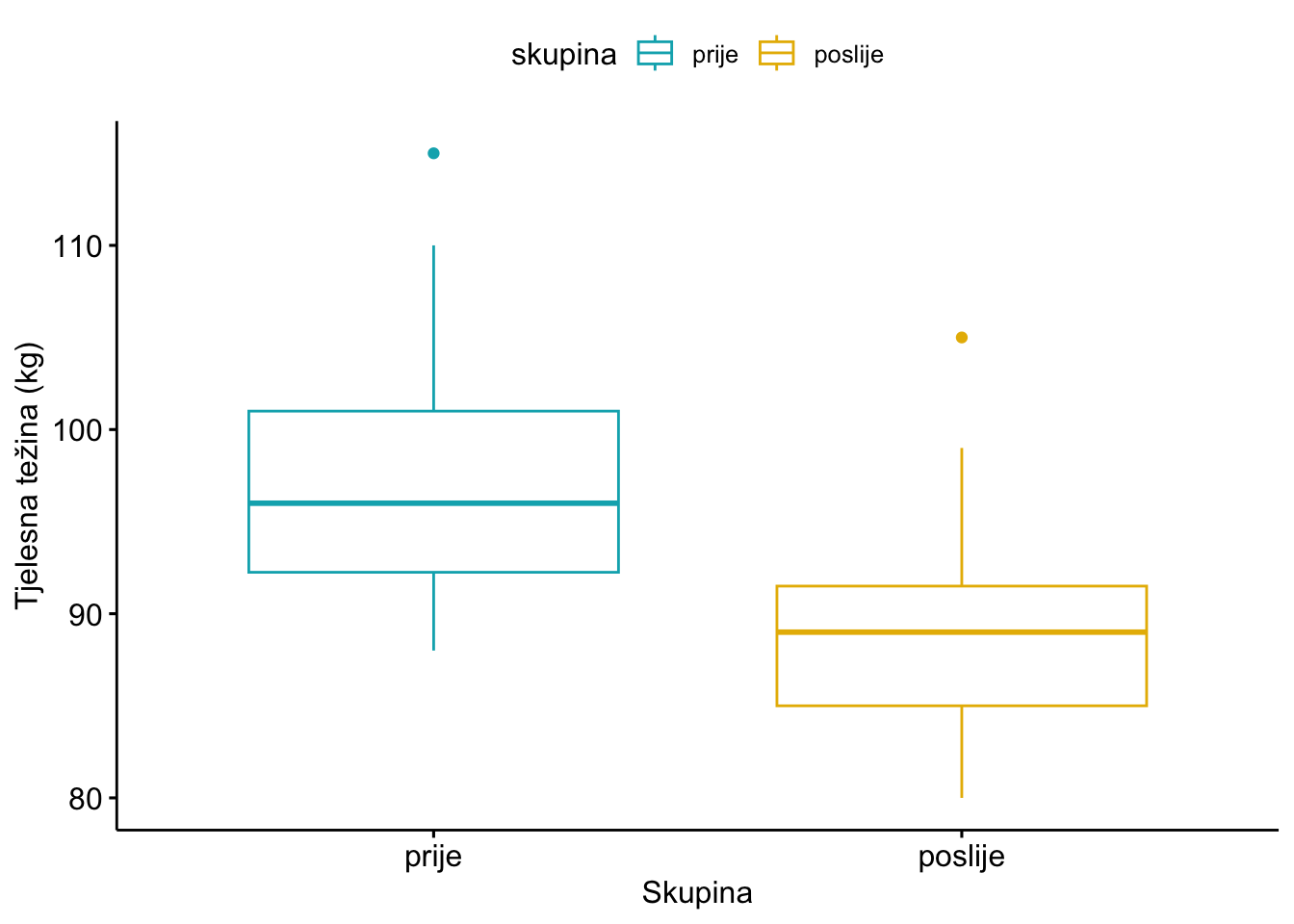
Konačno, pitanje da li je navedena razlika u prosječnim vrijednostima koju vidimo na slikovnom prikazu a i u prethodnom tabličnom prikazu statistički značajna ili ne, trebamo primijeniti t test za zavisne uzorke.
ttest_tezine <- t.test(tt_prije,tt_poslije,paired = TRUE)
ttest_tezine
Paired t-test
data: tt_prije and tt_poslije
t = 12.362, df = 9, p-value = 5.975e-07
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
6.699455 9.700545
sample estimates:
mean difference
8.2 Iz rezultata primjene t testa za zavisne uzorke, razvidno je kako je p vrijednost (p = 5.975e-07) značajna na razini od 99% (p<0.01). T vrijednost je 12.362.
No, prije primjene t testa, poglavito kada se radi o malim uzorcima kao što je ovaj gdje je N<30, treba primjeniti test za provjeru odstupanja navedenih varijabli od normalne raspodjele. Za to se koristi Shapiro-Wilk test. Kako bi to proveli, potrebno je izračunati razliku između težina prvog i drugog mjerenja i na takvoj varijabli provesti Shapiro Wilk test.
d_tezina <- with(tezina_frame,
tezina[skupina == "prije"] - tezina[skupina == "poslije"])
shapiro.test(d_tezina)
Shapiro-Wilk normality test
data: d_tezina
W = 0.87698, p-value = 0.1204Rezultat primjene Shapiro Wilk testa pokazuje kako test nije značajan na razini od 95% (p>0.05) i kako opravdano možemo zaključiti kako varijabla razlika između prvog i drugog mjerenja ne odstupa značajno od normalne raspodjele.
U slijedećem primjeru možemo vidjeti kako se kreativno mogu napraviti analize pomoću paketa rstatix na primjeru podataka iz paketa datarium i to istraživanja glavobolje.
Iz navedenih podataka pokušati ćemo vidjeti kakve su razlike između muškaraca i žena u procjeni glavobolje. Prvo ćemo napraviti opisnu statistiku te zatim i provjeru značajnosti pomoću t-testa.
datarium::headache %>%
group_by(gender) %>%
get_summary_stats(pain_score, type = "mean_sd")# A tibble: 2 × 5
gender variable n mean sd
<fct> <fct> <dbl> <dbl> <dbl>
1 male pain_score 36 79.7 7.95
2 female pain_score 36 75.6 6.49U slijedećem primjeru koda provjeravamo da li je značajna razlika između muškaraca i žena.
library(rstatix)
headache.test <- datarium::headache %>%
t_test(pain_score ~ gender) %>%
add_significance()
headache.test# A tibble: 1 × 9
.y. group1 group2 n1 n2 statistic df p p.signif
<chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
1 pain_score male female 36 36 2.44 67.3 0.0173 * Konačno, to možemo i slikovno prikazati.
library(ggpubr)
bxp <- ggboxplot(
datarium::headache, x = "gender", y = "pain_score",
ylab = "Pain score", xlab = "Gender", add = "jitter"
)
headache.test <- headache.test %>% add_xy_position(x = "gender")
bxp +
stat_pvalue_manual(headache.test, tip.length = 0) +
labs(subtitle = get_test_label(headache.test, detailed = TRUE))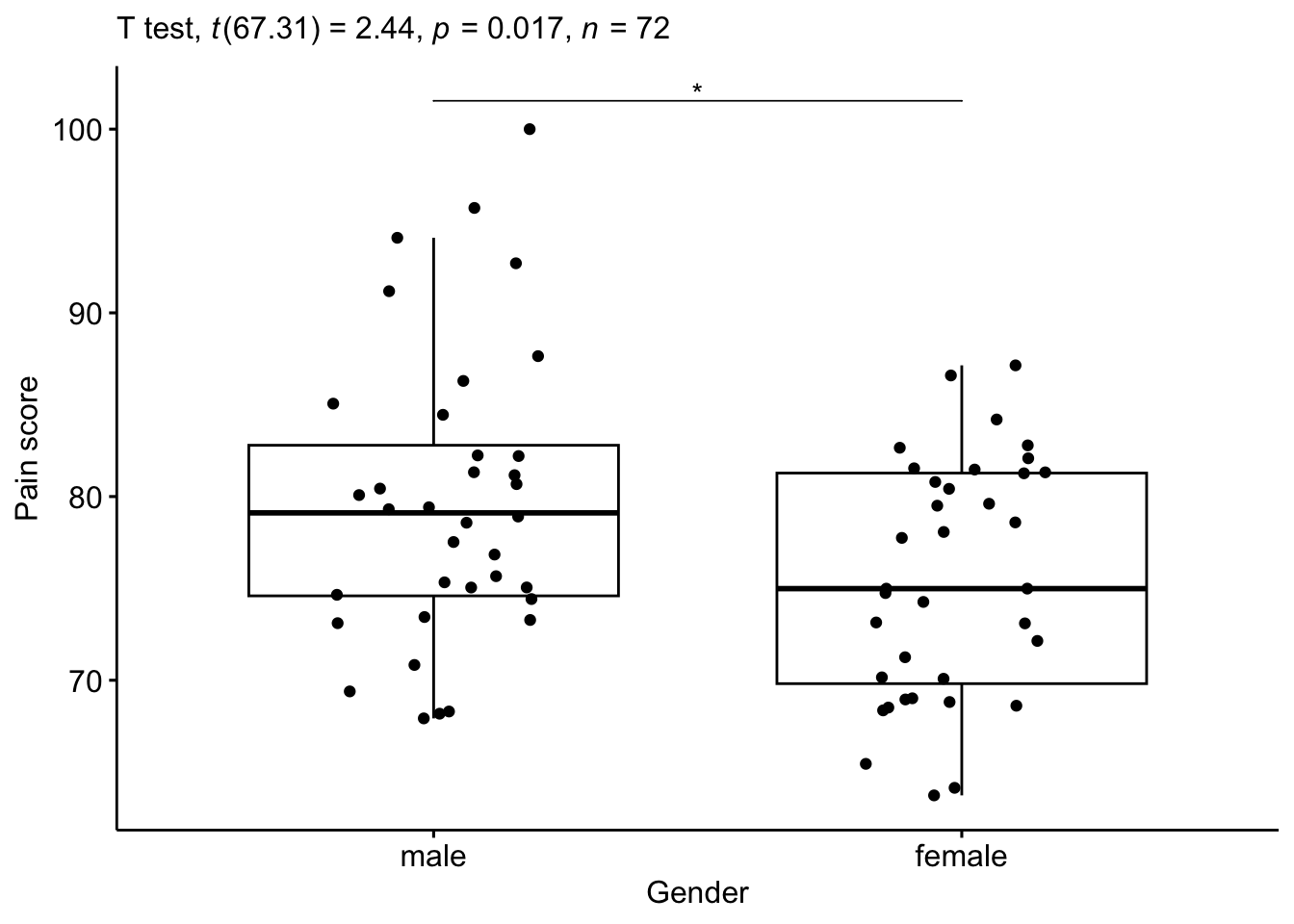
6.6 Veličina učinka
Posebno značajna tema pri pisanju rezultata istraživanja je efekt učinka. Za izražavanje i analizu efekta učinka i pripadajućih p vrijednosti, koristi se Cohen d vrijednost.
Formula za Cohen d vrijednost izražava se kao:
\[\begin{equation} d=\frac{\overline{X_{1}}-\overline{X_{2}}}{\sqrt\frac{var_{1} + var_{2}}{2}} \end{equation}\]No, u slučaju malih uzoraka, koristi se Hedges g. Za naš prethodni primjer, to bi izgledalo ovako…
datarium::headache %>% cohens_d(pain_score ~ gender, var.equal = FALSE)# A tibble: 1 × 7
.y. group1 group2 effsize n1 n2 magnitude
* <chr> <chr> <chr> <dbl> <int> <int> <ord>
1 pain_score male female 0.575 36 36 moderate Dobiveni rezultat pripada u srednji efekt učinka.
Interpretacija Cohen d vrijednosti je jednostavna. Ukoliko dobijemo d=1, to znači da se dvije grupe rezultata razlikuju za jednu standardnu devijaciju te na isti način ukoliko dobijemo d=2, dvije standardne devijacije. Što je veći uzorak, to je primjerenija primjena Cohen d vrijednosti. Ukoliko je Cohen d vrijednost veća od 0.8, sve više smatramo velikim učinkom (large effect).
Kao što je prethodno rečeno, ako je N malen, posebno manji od 30 ili 20, tada je bolje primjeniti Hedge g vrijednost koja proizlazi iz jednostavne formule.
\[\begin{equation} g=\frac{d}{\sqrt{\frac{N}{df}}} \end{equation}\]Iz Cohen d vrijednosti možemo izračunati i koeficijent korelacije, o čemu ćemo nešto više govoriti u poglavlju korelacija.
\[\begin{equation} r=\frac{d}{\sqrt{d^{2} + 4}} \end{equation}\]6.6.0.1 Zadatci: T-test
1.U carData paketu, otvorite skup UN i napravite sljedeće zadatke.
Usporedite razlikuju li se zasebno skupine u varijabli “group” (dakle usporedba jedne po jedne grupe prema prosjeku) i interpretirajte, na varijablama: 1) ppgdp, te zatim 2)lifeExpF.
- U carData paketu pronađite i otvorite skup WeightLoss.
Usporedite i interpretirajte razlike u izgubljenoj težini između prvog i drugog mjeseca, drugog i trećeg te zatim prvog i trećeg na svim sudionicima. Zatim isto napravite za samopoštovanje (se).
Napravite isti postupak, ali samo za osobe koje su u grupi DietEx.
Otvorite skup WVS (opis: https://www.rdocumentation.org/packages/carData/versions/3.0-3/topics/WVS) Napravite deskriptivnu statistiku dobi prema varijabli country. Ispitajte ima li razlike u dobi između visoko i nisko obrazovanih, rezultate interpretirajte i grafički prikažite.
6.7 Analiza varijance (ANOVA)
Začetci analize varijance vežu se uz ime Sir Ronald Aylmer Fisher (1890-1962) koji je bio statističar, genetičar i evolucijski biolog te začetnik neodarvinističke sinteze (neo-Darwinian synthesis) i promotor eugenike (The Genetical Theory) [bodmer_fisher_2021]. Za njega mnogi smatraju kako je najveće ime nakon Darwina a takvom izjavom se posebno ističe Richard Dawkins (“the greatest biologist since Darwin”) i A. Hald (“a genius who almost single-handedly created the foundations for modern statistical science”).
6.7.1 Zašto ANOVA?
Analiza varijance je statistički postupak kojim se uspoređuju različite komponente varijance (kvadrirane standardne devijacije). Primjenjuje se u svim slučajevima kada imamo istraživačke nacrte sa više od dvije nezavisne skupine ispitanika ili više od dva ponovljena mjerenja. Prvotna analiza koju je razvio Fisher, pretpostavljala je jednaki broj ispitanika ili nekih drugih entiteta u tri ili više skupina. O važnosti jednakosti broja ispitanika ili općenito balansiranosti eksperimentalnog nacrta biti će riječi kroz poglavlje o analizi varijance.
Jednostavna analiza varijance (one-way ANOVA) primjenjuje se kada uspoređujemo rezultate jedne zavisne varijable unutar jedne nezavisne varijablom koja ime više razina ili kategorija. Ukoliko imamo primjerice istraživanje, da li između četiri dobne skupine ispitanika (1: 10-19 godina, 2: 20-29, 3: 30-49, 4: 50-59) postoji statistički značajna razlika u razini kolesterola u krvi. U ovom slučaju možemo primijeniti postupak jednostavne analize varijance jer želimo vidjeti da li između većeg broja dobnih skupina (nezavisna varijabla) postoji statistički značajna razlika u razini kolesterola u krvi (zavisna varijabla).
Složena analiza varijance je statistički postupak koji se primjenjuje u onim slučajevima kada uspoređujemo rezultate jedne ili više zavisnih varijabli unutar više nezavisnih varijabli koje imaju različite razine ili kategorije. Za razliku od jednostavne analize varijance, gdje imamo samo jednu zavisnu varijablu, kod složene analize varijance, osim utjecaja većeg broja nezavisnih varijabli na zavisnu, gledamo i međudjelovanje (interakciju) između većeg broja zavisnih varijabli.
Dakle, u slučaju jednostavne analizu varijance, kada želimo utvrditi kako neka nezavisna varijabla utječe na neku zavisnu varijablu potrebno je imati: a) veći broj kategorija nezavisne varijable b) za svaku od kategorija određeni broj ispitanika na kojima su prikupljeni podaci o zavisnoj varijabli c) zavisnu varijablu koja je metrička, kontinuirana varijabla (intervalna ili omjerna mjerna ljestvica).
Općenito logika jednostavne analize varijance počiva na: a) odstupanjima pojedinačnih rezultata od vlastite aritmetičke sredine, i tu imamo variranje ili varijabilitet unutar skupine kojoj pripada ispitanik i na: b) odstupanjima aritmetičkih sredina pojedinih skupina rezultata od zajedničke aritmetičke sredine svih rezultata tj. varijabilitet između skupina.
Dakle, za analizu varijance važan je odnos varijance između i unutar skupina. Izračunava se tzv. F-vrijednost testa:
\[\begin{equation}\label{F omjer} F=\frac{V_{ig}}{V_{ug}} \end{equation}\]Iz izraza za izračun F vrijednosti, proizlazi, što je veće variranje rezultata između skupina ispitanika u odnosu na variranje unutar skupina, to je F omjer veći. Što je veći F-omjer, uz pripadajuće stupnjeve slobode, to je i opravdanije odbacivanje nul-hipoteze i prihvaćanje alternativne hipoteze. Što je veći F-omjer to je za očekivati i manju p-vrijednost koja će pri velikom F-mjeru biti značajna na razlini od 95% (p<0.05) ili 99% (p<0.01).
Na slijedećem slikovnom prikazu je jedan od primjera simulacije raspodjele rezultata zavisne varijable kada imamo tri skupine ispitanika gdje se rezultati značajno preklapaju. Pretpostavimo 100 ispitanika u svakoj skupini gdje je obavljeno mjerenje kvocijenta inteligencije.
set.seed(5)
x <- c(rnorm(100, mean = 110, 5),
rnorm(100, mean = 115, sd = 5),
rnorm(100, mean = 120, 5))
grupa <- c(rep("A", 100), rep("B", 100), rep("C", 100))
df <- data.frame(x, grupa)Slikovni prikaz može se jednostavno napraviti pomoću paketa ggplot.
library(ggplot2)
cols <- c("#F76D5E", "#FFFFBF", "#72D8FF")
# Basic density plot in ggplot2
ggplot(df, aes(x = x, fill = grupa)) +
geom_density(alpha = 0.7) +
scale_fill_manual(values = cols) +
xlab("Kvocijent inteligencije")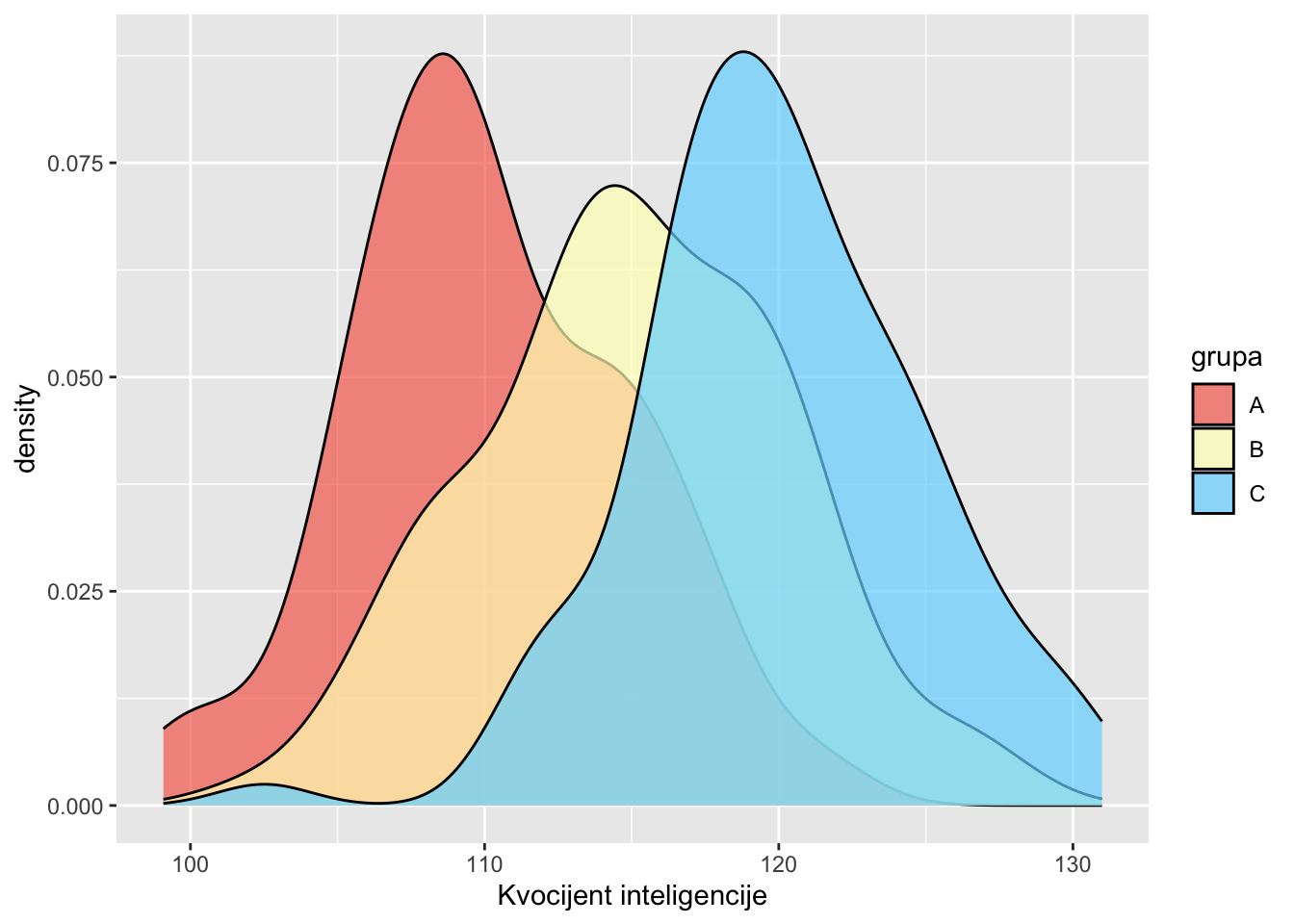
Iz slike je vidljivo značajno preklapanje rezultata pojedinih skupina jer je varijabilitet između skupina ili grupa ispitanika (Vis, Vig) manji od varijabiliteta unutar skupina ili grupa (Vus, Vug). Na sljedećoj je slici vidljiva obrnuta situacija: jasna razlika između skupina očituje se zbog većeg varijabiliteta između skupina (Vis) u odnosu na varijabilitet unutar skupina (Vus). U ovom slučaju je preklapanje manje ili ga uopće nema.
set.seed(5)
x <- c(rnorm(100, mean = 110, 3),
rnorm(100, mean = 120, sd = 3),
rnorm(100, mean = 130, 3))
grupa <- c(rep("A", 100), rep("B", 100), rep("C", 100))
df <- data.frame(x, grupa)Prethodno napravljen eksperiment sa tri skupine gdje su prosječne vrijednosti 110, 120 i 130 a standardne devijacije tih skupina vrlo male i iznose 3. Slike triju raspodjela izgledaju na slijedeči način:
library(ggplot2)
cols <- c("#F76D5E", "#FFFFBF", "#72D8FF")
# Basic density plot in ggplot2
ggplot(df, aes(x = x, fill = grupa)) +
geom_density(alpha = 0.7) +
scale_fill_manual(values = cols) +
xlab("Kvocijent inteligencije")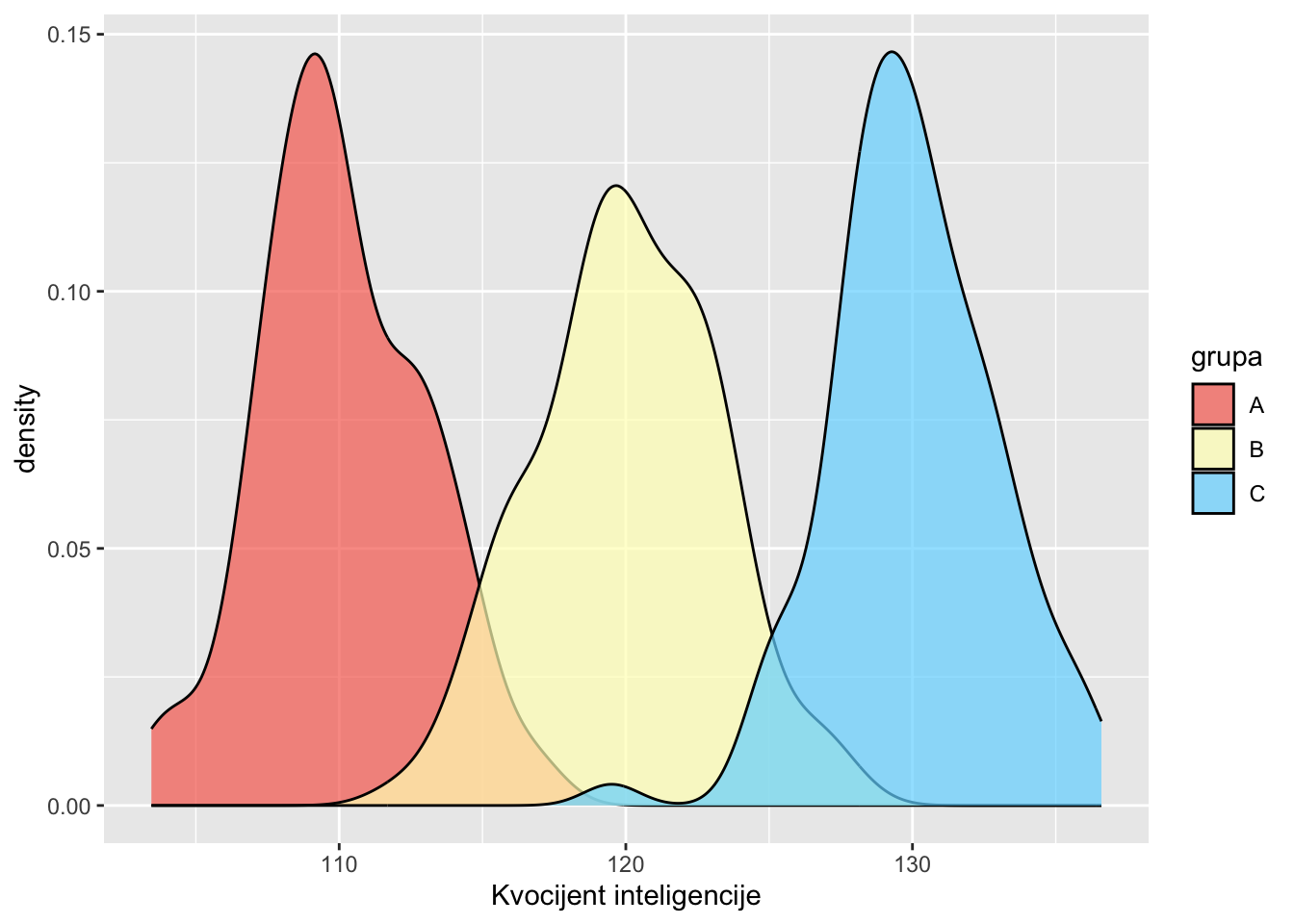
Za pretpostaviti je kako ćemo na prethodnoj slici kada primijenimo analizu varijance dobiti značajan F-omjer tj. vjerojatno ćemo odbaciti nul-hipotezu i prihvatiti alternativnu hipotezu te donijeti zaključak kako postoje značajne razlike između tri skupine ispitanika u predmetu mjerenja tj. u zavisnoj varijabli.
Osnovna mjera koju dobijemo nakon provedene analize varijance je omjer varijance među skupinama i varijance unutar skupina. Slično smo imali i kod t-testa. U svakom slučaju logika je ista: dobije se određena vrijednost F-omjera, pripadajući stupnjevi slobode (df) i p-vrijednost (koja se tumači na isti način kao i kod svih ostalih statističkih testova).
Primjer: Provedeno je istraživanje u kojem se želi vidjeti postoji li razlika u vrijednostima dijastoličkog krvnog tlaka između ispitanika koji su primali 1, 2 ili 3 antihipertenziva. U istraživanju je ukupno sudjelovalo 150 ispitanika, gdje je po 50 ispitanika uzimalo kontinuirano 1, 2 ili 3 antihipertenziva. Znači, u ovom se slučaju mijenja situacija u odnosu na t-test, gdje smo imali razliku između dva uzorka ili dva mjerenja. S jedne strane imamo kontinuiranu, metričku varijablu, te s druge strane kvalitativnu, trihotomnu varijablu. Dakle, želimo vidjeti da li između ispitanika/pacijenata koji pripadaju određenoj skupini (1, 2 ili 3 antihipertenziva) postoji razlika u jednoj metričkoj, kontinuiranoj varijabli (dijastolički tlak). Naime, u ovakvim slučajevima ne koristimo t-testove za svaki pojedini par skupina, jer povećavanjem broja t-testova povećavamo vjerojatnost slučajnog pozitivnog nalaza. Tako na primjer, u 20 usporedbi skupina gdje razlike između populacija nema (stvarna razlika jednaka nuli), prosječno će jedno testiranje proglasiti uočene razlike statistički značajnim uz 95% graničnu razinu značajnosti.
Ako izneseno povežemo sa prije iznesenim primjerom koncentracije kolesterola u krvi možemo reći slijedeće: a) ako imamo ispitanika koji ima 35 godina onda njegova koncentracija kolesterola odstupa za neku vrijednost od aritmetičke sredine njegove skupine ispitanika od 30-49 godina b) aritmetička sredina koncentracije kolesterola skupine od 30-49 godina odstupa za neku vrijednost od zajedničke aritmetičke sredine sve četiri skupine ispitanika
Analiza varijance nije jednostavna metoda i uključuje niz modela:
• jednosmjerna (one-way) analiza varijance (ANOVA) za nezavisne uzorke
• analiza varijance za zavisne uzorke (repeated measures ANOVA)
• analiza varijance s kontrolom kovarijabli (ANCOVA ili MANCOVA)
• faktorijalna analiza varijance
• višesmjerna (multi-way) analiza varijance
• multifaktorska analiza varijance (MANOVA)
6.7.2 Uvjeti za primjenu analize varijance
Neki od uvjeta za primjenu analize varijance su:
normalitet raspodjele: varijabla koja se mjeri ne bi smjela značajno odstupati od normalne,
broj ispitanika po skupinama bi trebao biti minimalno 20,
metrijske karakteristike varijabli: potrebna je minimalno intervalna mjerna ljestvica,
homogenost varijanci: odnosi se na varijacije unutar svake od pojedinih skupina ispitanika, te između različitih grupa ne bi smjelo biti značajnih razlika u varijacijama,
sfericitet – važan za analizu varijance u zavisnim uzorcima, a odnosi se na varijance razlika između različitih vremenskih točaka, koje bi trebale biti podjednake.
Ukoliko homogenost varijanci značajno odstupa tada se koristi jedan od testova za provjeru homogenosti varijanci poput Levene testa. Ukoliko je malen broj ispitanika po skupinama tada treba napraviti reviziju modela prije primjene analize varijance ili povećati broj ispitanika po pojedinim skupinama.
Predmet mjerenja po metrijskim svojstvima je važan kriterij, jer ako zavisna varijabla ili predmet mjerenja nije na intervalnoj ili omjernoj mjernoj ljestvici, tada je to ozbiljno ograničenje za uopće korištenje analize varijance. Predmet mjerenja treba odgovarati intervalnoj ili omjernoj mjernoj ljestvici te također i uvjetima normaliteta raspodjele.
U novije vrijeme, razvijeni su paketi u R-u koji omogućavaju korištenje tzv. robusnih statističkih metoda, koje bi kompenzirale navedena ograničenja (Mair & Wilcox, 2020).
Za provjeru nekih od kriterija prikladnosti ili zadovoljenja uvjeta upotrebe analize varijance, posebno je praktičan paket afex (Singmann et al., 2022) u suradnji s performance (Lüdecke et al., 2021) paketom jer u kombinaciji značajno nadilaze mogućnosti standardnih funkcija.
U slijedećih nekoliko primjera razmotrit ćemo primjenu pomoću navedena dva paketa.
U prvom primjeru je zamišljena studija iz paketa car gdje imamo 32 ispitanika (16 muškaraca i 16 žena) koji su prišli tri intervencije (prije testa, nakon testa, i nakon nekog vremena). U svakom od tih mjerenja bilo je 5 ponovljenih mjerenja.
library(afex)Warning: package 'afex' was built under R version 4.4.1Loading required package: lme4Loading required package: Matrix************
Welcome to afex. For support visit: http://afex.singmann.science/- Functions for ANOVAs: aov_car(), aov_ez(), and aov_4()
- Methods for calculating p-values with mixed(): 'S', 'KR', 'LRT', and 'PB'
- 'afex_aov' and 'mixed' objects can be passed to emmeans() for follow-up tests
- Get and set global package options with: afex_options()
- Set sum-to-zero contrasts globally: set_sum_contrasts()
- For example analyses see: browseVignettes("afex")
************
Attaching package: 'afex'The following object is masked from 'package:lme4':
lmerlibrary(performance) Warning: package 'performance' was built under R version 4.4.1# učitavanje podataka iz afex paketa
data(obk.long, package = "afex")
o1 <- aov_ez("id", "value", obk.long,
between = c("treatment", "gender"))Warning: More than one observation per design cell, aggregating data using `fun_aggregate = mean`.
To turn off this warning, pass `fun_aggregate = mean` explicitly.Contrasts set to contr.sum for the following variables: treatment, gender# provjera homogenosti
check_homogeneity(o1)OK: There is not clear evidence for different variances across groups (Levene's Test, p = 0.350).U prethodnom primjeru vidimo kako navedeni model zadovoljava uvjet homogenosti.
U slijedećem primjeru koristi ćemo podatke o spavanju kod sisavaca. Podatci (msleep) su pohranjeni u ggplot2 paketu (Wickham, 2016). Prosječna duljina spavanja kod sisavaca razlikuje se s obzirom na način prehrane. U ovom primjeru nije zadovoljen uvjet homogenosti, Levene test je značajan.
library(dplyr)
library(ggplot2)
library(afex)
library(performance)
msleep %>%
group_by(vore) %>%
summarise(avg_sleep = mean(sleep_total),
min_sleep = min(sleep_total),
max_sleep = max(sleep_total),
total = n())# A tibble: 5 × 5
vore avg_sleep min_sleep max_sleep total
<chr> <dbl> <dbl> <dbl> <int>
1 carni 10.4 2.7 19.4 19
2 herbi 9.51 1.9 16.6 32
3 insecti 14.9 8.4 19.9 5
4 omni 10.9 8 18 20
5 <NA> 10.2 5.4 13.7 7aov_msleep <- aov_ez("name", "sleep_total", msleep,
between = c("vore"))Converting to factor: voreWarning: Missing values for 7 ID(s), which were removed before analysis:
Deer mouse, Desert hedgehog, Mole rat, Musk shrew, Phalanger, Rock hyrax, Vesper mouse
Below the first few rows (in wide format) of the removed cases with missing data.
name vore .
# 18 Deer mouse <NA> 11.5
# 20 Desert hedgehog <NA> 10.3
# 49 Mole rat <NA> 10.6
# 53 Musk shrew <NA> 12.8
# 59 Phalanger <NA> 13.7
# 66 Rock hyrax <NA> 5.4Contrasts set to contr.sum for the following variables: vore# provjera homogenosti
check_homogeneity(aov_msleep)Warning: Variances differ between groups (Levene's Test, p = 0.003).Osim homogenosti varijance, možemo provjeriti sfericitet i normalitet reziduala. Paket performance (Lüdecke et al., 2021) ima jako puno ugrađenih funkcija za provjeru uvjeta korištenja testova te je pogodan za rad s afex paketom. U slijedećem primjeru dostupnom sa službenih stranica afex paketa, možemo vidjeti kako se jednostavno može provjeriti sfericitet.
library(afex)
library(performance)
data("fhch2010", package = "afex")
a1 <- aov_ez("id", "log_rt", fhch2010,
between = "task",
within = c("density", "frequency", "length", "stimulus"))Warning: More than one observation per design cell, aggregating data using `fun_aggregate = mean`.
To turn off this warning, pass `fun_aggregate = mean` explicitly.Contrasts set to contr.sum for the following variables: taskcheck_sphericity(a1)Warning in summary.Anova.mlm(object$Anova, multivariate = FALSE): HF eps > 1
treated as 1Warning: Sphericity violated for:
- length:stimulus (p = 0.021)
- task:length:stimulus (p = 0.021).U navedenom primjeru vidimo kako nije zadovoljen uvjet sfericiteta.
U slijedećem primjeru, dostupnom u službenoj dokumentaciji afex paketa, možemo vidjeti kako se pomoću testa Shapiro-Wilk može provjeriti normalitet reziduala a što je često pojava u korištenju analize varijance. Ovdje treba posebno obratiti pozornost na tri slikovna prikaza. U prvom se vidi odstupanje od normalne raspodjele, dok u slijedeća dva slikovna prikaza, vidi se kako odstupaju rezultati u qq prikazu.
library(afex)
library(performance)
data("stroop", package = "afex")
stroop1 <- subset(stroop, study == 1)
stroop1 <- na.omit(stroop1)
s1 <- aov_ez("pno", "rt", stroop1,
within = c("condition", "congruency"))Warning: More than one observation per design cell, aggregating data using `fun_aggregate = mean`.
To turn off this warning, pass `fun_aggregate = mean` explicitly.is_norm <- check_normality(s1)
plot(is_norm)For confidence bands, please install `qqplotr`.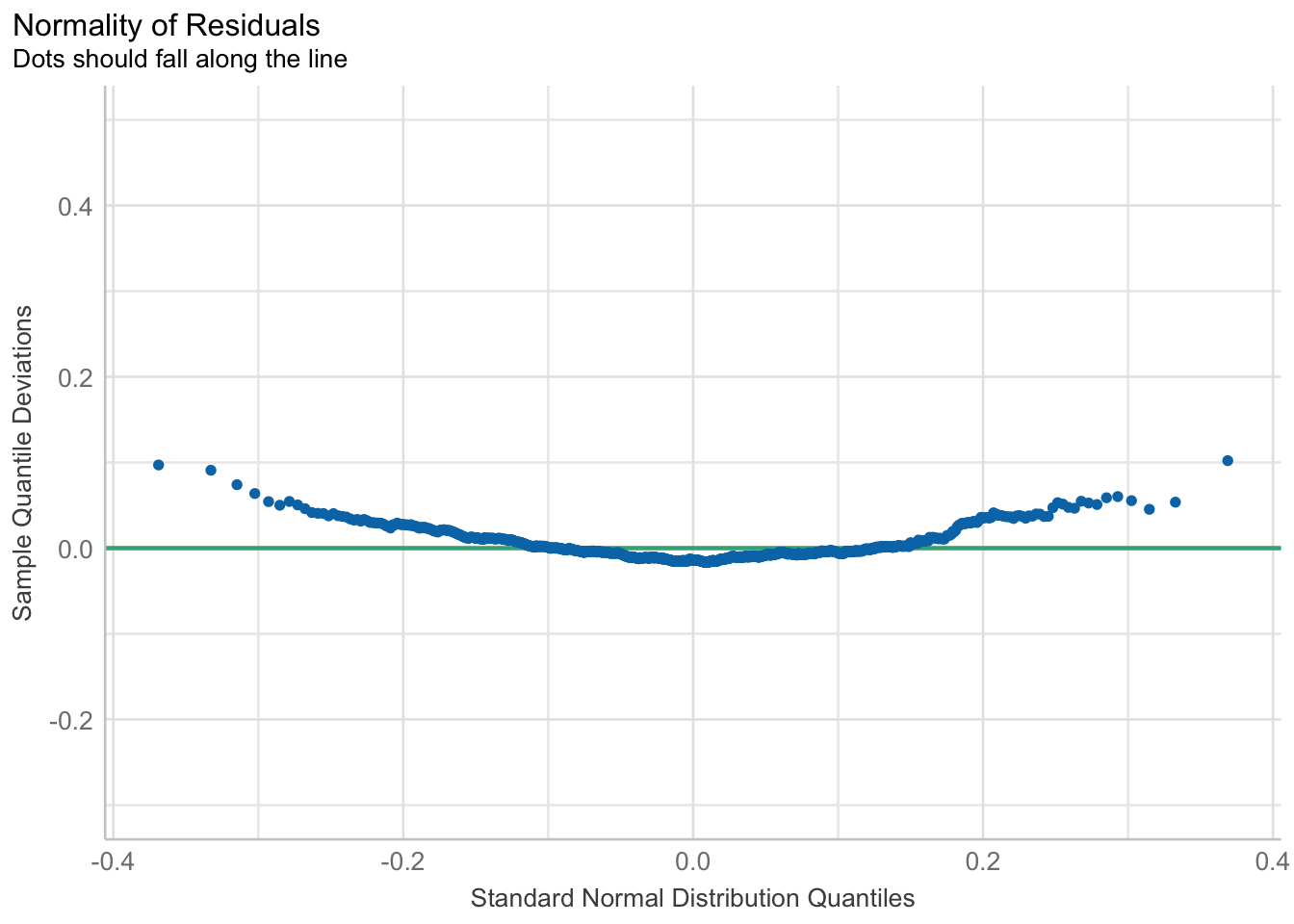
plot(is_norm, type = "qq")For confidence bands, please install `qqplotr`.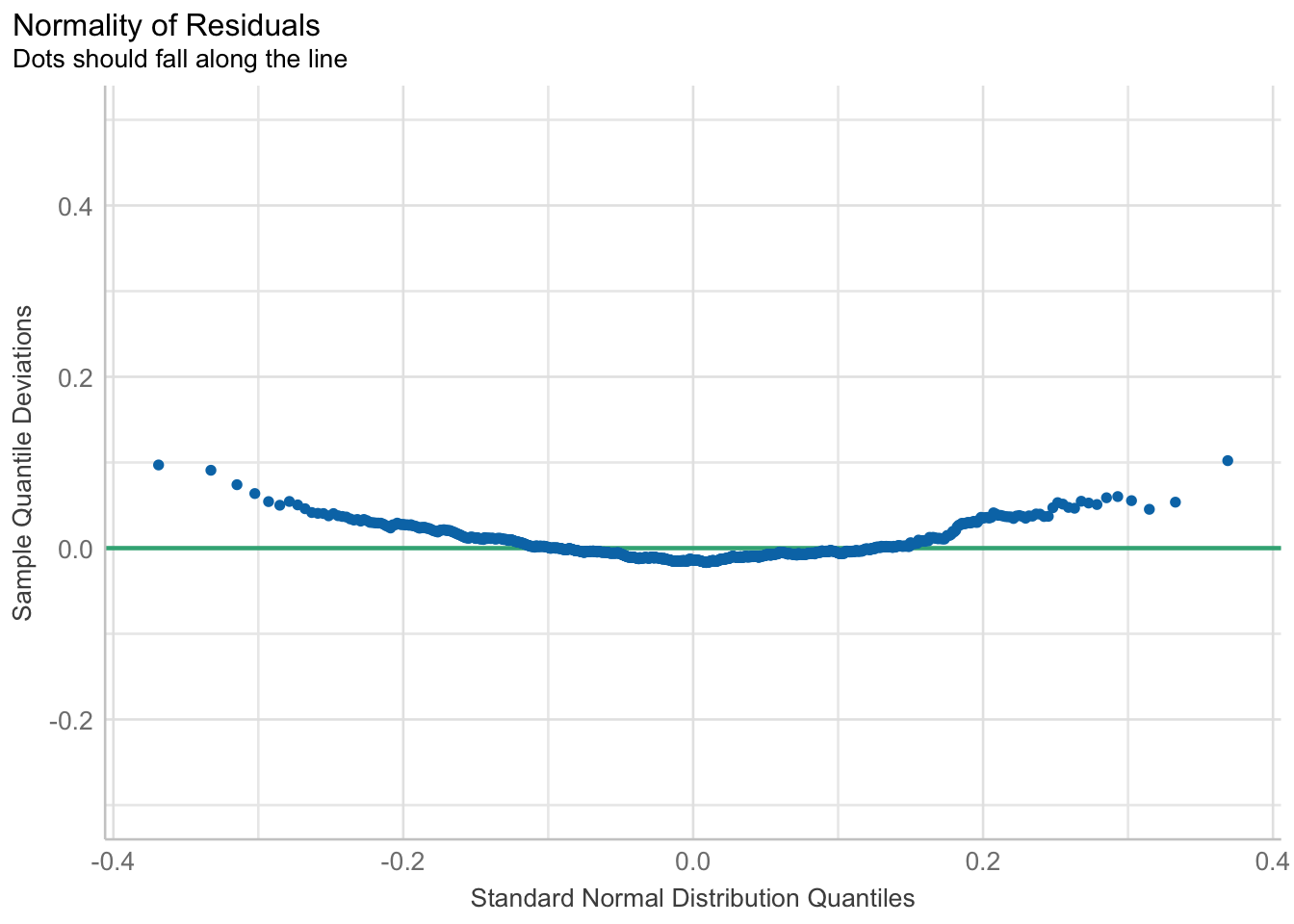
plot(is_norm, type = "qq", detrend = TRUE)For confidence bands, please install `qqplotr`.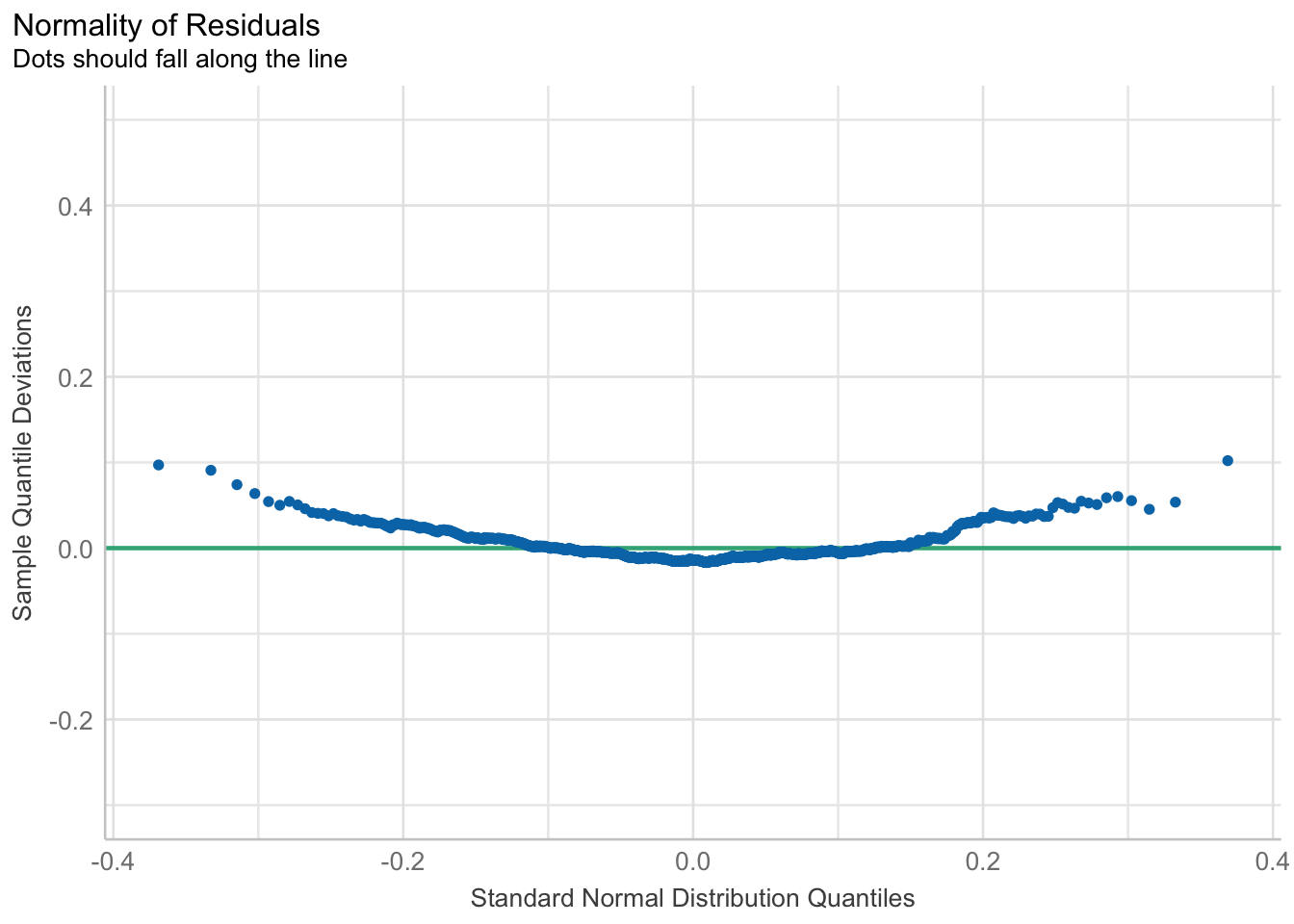
6.7.3 Anova - nezavisni uzorci
Analiza varijance je počela primjenu u rješavanju praktičnih zadataka još od 1925. godine kada je opisao po prvi puta R.A. Fisher, ali je važno naglasiti za uravnoteženi nacrt ili uravnoteženi broj ispitanika koji je jednak u svim skupinama. Kada je broj ispitanika u svim skupinama jednak, dakle tzv. balansirani model, tada će ANOVA tip izračuna i redoslijeda sume kvadrata I, II i III (Type I, II, III) dati jednak rezultat. U ostalim slučajevima, rezultati će biti različiti.
U literaturi se navode i imena za tri različita tipa analize varijance s obzirom na izračun i redoslijed sume kvadrata: sekvencijalni (Type I), hijerarhijski (Type II) i jedinstveni (Type III) model sume kvadrata.
Cilj dvosmjerne analize varijance jest analizirati ukupno variranje zavisna varijable mogućim utjecajem dviju varijabli tj. objasniti koji dio variranja pripada jednoj a koji dio variranja pripada drugoj nezavisnoj varijabli. Zbog toga, postoje tri načina na koji se računa podijeljena ukupna varijanca (Type I, II, III).
Tip I se naziva i sekvencijalni model te primjenjuje model izračuna utjecaja nezavisne varijable na zajedničku varijancu na način da uzima prvu navedenu varijablu (npr. varijabla A). Dakle, prvo nastoji postići interpretaciju najveće moguće varijance variranjem vrijednosti utjecaja nezavisne varijable A. Nakon toga, onaj dio varijance koji ostaje pridjeljuje variranju varijable B. Ostatak nakon utjecaja varijable A i B, pridjeljuje interakcijskom efektu i rezidualnoj varijanci.
Zato, u praksi treba pripaziti, jer R jezik podrazumijevano izračunava Tip I (Type I) koristeći funkcije aov() i anova().
Tip II se naziva i hijerarhijski jer prvo izračunava utjecaj A te zatim B i onda obrnuto, koji dio variranja B je pod utjecajem A. Konačno, ne računa interakcijski učinak.
Tip III se naziva i parcijalni, jer neovisno od načina pisanja formule ili redoslijeda navođenja nezavisnih varijabli, izračunava utjecaj varijable A i B te konačno i interakcijskog efekta A,B. U R jeziku to je moguće uporabom paketa car (Fox & Weisberg, 2019) i njegove funkcije Anova() te jednako tako pomoću funkcije ez_aov u paketu afex.
U ovom poglavlju ćemo vidjeti primjenu analize varijance za nezavisne uzorke i to jednostavnu ili jednosmjernu (one-way ANOVA) te sa dvije nezavisne varijable (two-way ANOVA). Uz primjenu analize varijance, komentirati ćemo i primjenu post-hoc analiza, izračun najboljeg modela i procjenu efekta učinka i objašnjene varijance.
Za demonstraciju jednostavne analize varijance, poslužit ćemo se podatcima Moore koji se nalaze u paketu car. Podatci se odnose na jednostavno istraživanje iz područja socijalne psihologije.
Koristeći paket car možemo odabrati koji ćemo koristiti model ekstrakcije sume kvadrata (Type I, II, III).
library(car)
anova_moore <- lm(conformity ~ partner.status + fcategory + partner.status*fcategory, data=Moore)
Anova(anova_moore, type="III")Anova Table (Type III tests)
Response: conformity
Sum Sq Df F value Pr(>F)
(Intercept) 984.14 1 46.9348 3.436e-08 ***
partner.status 2.20 1 0.1050 0.74767
fcategory 89.67 2 2.1383 0.13147
partner.status:fcategory 175.49 2 4.1846 0.02257 *
Residuals 817.76 39
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Pomoću paketa afex (Singmann et al., 2022) dobit ćemo puno sadržajniju tablicu, koja uključuje efekt učinka za svaku pojedinu nezavisnu varijablu tj. glavni učinak i interakciju. Prije primjene afex paketa, nužno je potrebno, ukoliko nemamo identifikacijsku varijablu za svakoga ispitanika, tu istu treba i ubaciti. Poslužit ćemo se drugim podatcima iz baze podataka obk.long koja dolazi također u car paketu.
library(afex)
afex_anova <- aov_ez(id="id", dv = "value", between = c("treatment"), data=obk.long)Warning: More than one observation per design cell, aggregating data using `fun_aggregate = mean`.
To turn off this warning, pass `fun_aggregate = mean` explicitly.Contrasts set to contr.sum for the following variables: treatmentsummary(afex_anova)Anova Table (Type 3 tests)
Response: value
num Df den Df MSE F ges Pr(>F)
treatment 2 13 2.1363 2.9139 0.30953 0.09004 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Ukoliko želimo provesti dvosmjernu analizu varijance, uključujemo još jednu varijablu.
library(afex)
library(car)
afex_anova <- aov_ez(id="id", dv = "value", between = c("treatment", "gender"), data=obk.long)Warning: More than one observation per design cell, aggregating data using `fun_aggregate = mean`.
To turn off this warning, pass `fun_aggregate = mean` explicitly.Contrasts set to contr.sum for the following variables: treatment, gendersummary(afex_anova)Anova Table (Type 3 tests)
Response: value
num Df den Df MSE F ges Pr(>F)
treatment 2 10 1.5204 3.9405 0.44075 0.05471 .
gender 1 10 1.5204 3.6591 0.26789 0.08480 .
treatment:gender 2 10 1.5204 2.8555 0.36350 0.10447
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Za potrebe izrade rezultata istraživanja koji će se objaviti u nekom od časopisa, tada je potrebno navedenu tablicu prirediti sukladno standardima (kao što je APA stil).
To možemo izvesti jednostavno koristeći ugrađenu funkciju nice() u afex paketu.
knitr::kable(nice(afex_anova))| Effect | df | MSE | F | ges | p.value |
|---|---|---|---|---|---|
| treatment | 2, 10 | 1.52 | 3.94 + | .441 | .055 |
| gender | 1, 10 | 1.52 | 3.66 + | .268 | .085 |
| treatment:gender | 2, 10 | 1.52 | 2.86 | .364 | .104 |
Za primjenu analize varijance i tumačenje značajnosti razlika važno je napomenuti i tzv. post hoc testiranja. Naime, ako dobijemo F-omjer koji je značajan, to znači da se promatrane skupine statistički značajno razlikuju u istraživanoj varijabli. No, još ne možemo tvrditi između kojih parova je razlika značajna!
Kako bi provjerili između kojih parova postoji razlika, poželjno je primijeniti jedan od naknadih testova (post hoc) koji slijede nakon analize varijance. U praksi se koriste različiti testovi (Scheffe, Tuckey, Bonferroni, Duncan, Newman-Keuls…), a od najčešće korištenih post hoc testova su Scheffeov i HSD Tuckey test. Scheffeov post hoc test dosta strog ili ‘konzervativan’ za razliku od HSD Tuckey testa koji je podosta liberalan (izbor ovisi koju statističku pogrešku više želimo izbjeći: tipa 1 ili tipa 2).
U gornjim se definicijama smjerovi odnose na nezavisnu varijablu (više smjerova znači više načina kategorizacije), a faktori na zavisnu varijablu (više faktora znači više zavisnih varijabli). Kako smo već definirali, složena analiza varijance uključuje i višesmjernu i multifaktorsku ANOVA-u. Kovarijabla u analizi varijance je metrička varijabla koja može imati utjecaja na rezultata analize jer nije podjednako distribuirana po nezavisnim varijablama. U ANCOVI (MANCOVI) se njen utjecaj matematički odračunava. U višesmjernoj ANOVA-i postoji mogućnost istraživanja međudjelovanja (interakcije) između nezavisnih varijabli, kao u primjeru koji slijedi.
Funkcionalnost R sustava u primjeni različitih modela analize varijance može se vidjeti uporabom dva paketa: car [car] i afex [afex]. Osim navedenih u primjerima će se koristiti još neki paketi koji doprinose olakšavanju primjene i interpretacije analize varijance.
Vrlo koristan paket za provjeru značajnosti u post-hoc testiranju je emmeans (Lenth, 2023). Osim klasičnih prikaza p vrijednosti post hoc testova (Scheffe, HSD-Tuckey, LSD, Bonferroni i dr.), funkcije emmeans paketa uz suradnju s drugim paketima, može koristiti i alternativne i kreativne prikaze kao što je uporaba slovnih oznaka ili CLD metode (Compact Letter Display) (Piepho, 2004). U nekim znanstvenim i stručnim radovima iz područja agronomije, uvriježeni je prikaz post hoc analiza pomoću slovnih oznaka. U slijedećem primjeru, vidjet ćemo elegantnu uporabu u tabličnom i slikovnom prikazu.
library(emmeans)Warning: package 'emmeans' was built under R version 4.4.1Welcome to emmeans.
Caution: You lose important information if you filter this package's results.
See '? untidy'library(multcomp)Loading required package: mvtnormLoading required package: survivalLoading required package: TH.dataLoading required package: MASS
Attaching package: 'MASS'The following object is masked from 'package:rstatix':
selectThe following object is masked from 'package:dplyr':
select
Attaching package: 'TH.data'The following object is masked from 'package:MASS':
geyserlibrary(multcompView)
# set up model
model <- lm(weight ~ group, data = PlantGrowth)
# get (adjusted) weight means per group
model_means <- emmeans(object = model,
specs = "group")
# add letters to each mean
model_means_cld <- cld(object = model_means,
adjust = "Tukey",
Letters = letters,
alpha = 0.05)Note: adjust = "tukey" was changed to "sidak"
because "tukey" is only appropriate for one set of pairwise comparisons# show output
model_means_cld group emmean SE df lower.CL upper.CL .group
trt1 4.66 0.197 27 4.16 5.16 a
ctrl 5.03 0.197 27 4.53 5.53 ab
trt2 5.53 0.197 27 5.02 6.03 b
Confidence level used: 0.95
Conf-level adjustment: sidak method for 3 estimates
P value adjustment: tukey method for comparing a family of 3 estimates
significance level used: alpha = 0.05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
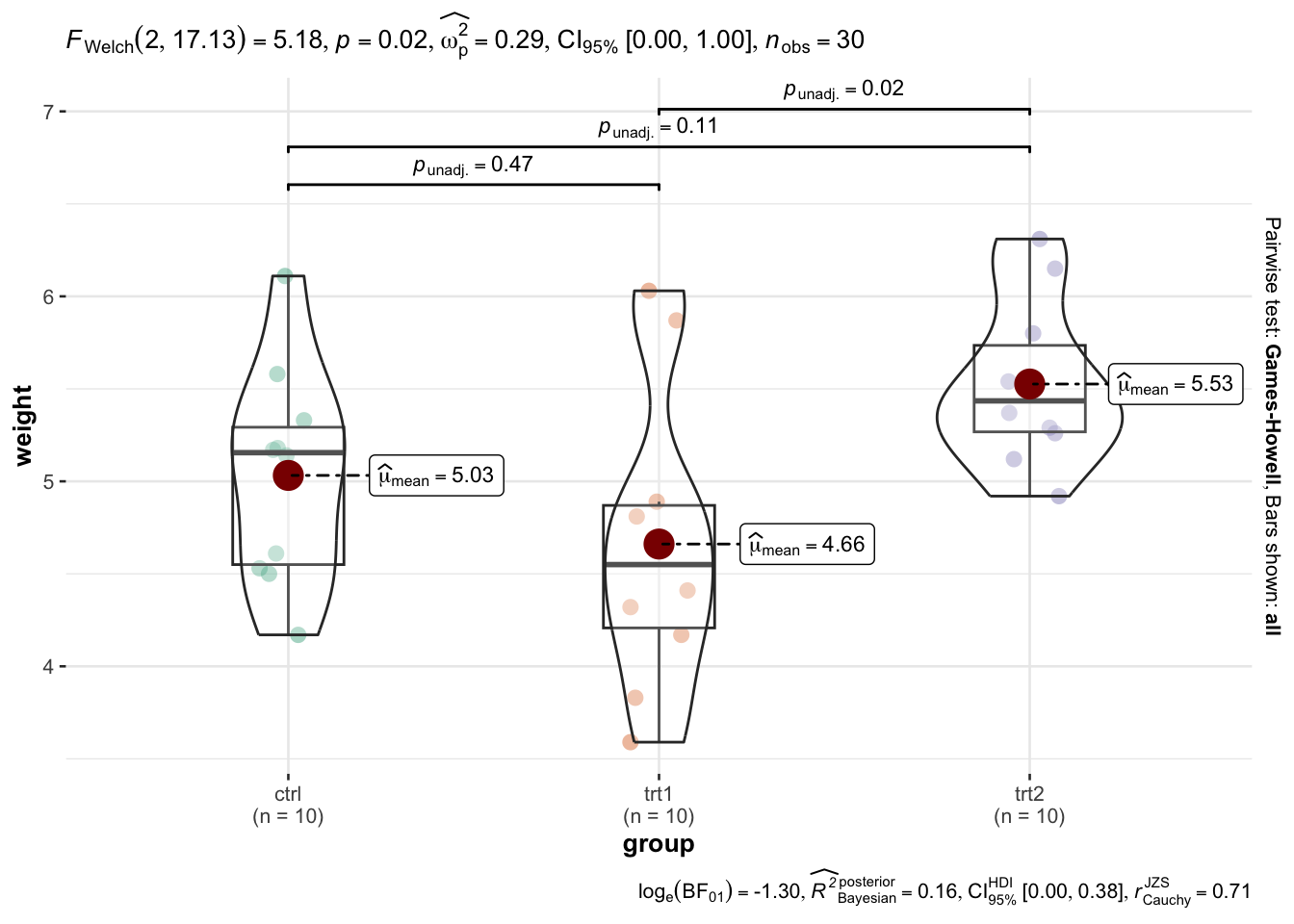
But we also did not show them to be the same. Kako tumačiti navedene rezultate? U posljednjoj tablici vidimo usporedbu između dva tretmana i kontrolne skupine. U posljednjem stupcu su slova, u prvom retku a, u drugom ab i trećem b. Retci koji dijele bilo koje slovo, tu nema statistički značajne razlike. Dva retka sa različitim slovima - između te dvije grupe postoji značajna razlika. Navedeni primjer, preuzet je s paketa emmeans (Lenth, 2023), multcomp (Hothorn et al., 2008) i multcompView (Graves et al., 2023) te mrežnih stranica dsfair (https://schmidtpaul.github.io/dsfair_quarto/) uporabe u agronomiji. Kreativnost je posebno istaknuta primjenom slikovnih prikaza, dostupnih preko drugih paketa koji omogućavaju gotove slikovne prikaze za znanstveni rad u časopisu.
library(PMCMRplus)Warning: package 'PMCMRplus' was built under R version 4.4.1library(rstantools)This is rstantools version 2.4.0library(ggstatsplot)Warning: package 'ggstatsplot' was built under R version 4.4.1You can cite this package as:
Patil, I. (2021). Visualizations with statistical details: The 'ggstatsplot' approach.
Journal of Open Source Software, 6(61), 3167, doi:10.21105/joss.03167# "since the confidence intervals for the effect sizes are computed using
# bootstrapping, important to set a seed for reproducibility"
set.seed(42)
ggstatsplot::ggbetweenstats(
data = PlantGrowth,
x = group,
y = weight,
pairwise.comparisons = TRUE,
pairwise.display = "all",
p.adjust.method = "none"
)
6.7.3.1 Zadatci: ANOVA
1 Otvorite dataset Burt (opis paketa: https://www.rdocumentation.org/packages/carData/versions/3.0-3/topics/Burt) iz carData Paketa te analizirajte postoji li razlika između skupina class na varijablama IQbio i IQ foster. Interpretirajte razlike ukoliko postoje.
Otvorite dataset Adler (opis paketa: https://www.rdocumentation.org/packages/carData/versions/3.0-3/topics/Adler) iz carData Paketa te analizirajte postoji li razlika između skupina instruction i expectation na varijabli rating. Interpretirajte razlike ukoliko postoje.
Usporedite postoji li statistički značajna razlika između skupina na varijabli correct. Rezultate prikažite i vizualno. Interpretirajte rezultate.
6.7.4 ANOVA - zavisni uzorci, miješani modeli
Rezultati primjene analize varijance usložnjavaju se sa složenosti modela. Tako, vrlo jednostavno možemo dodati varijable i napraviti model sa isključivo ponovljenim mjerenjem (ANOVA za zavisne uzorke, repeated measures ANOVA) ili složeniji miješani model koji uključuje variranje između skupina (between) i unutar skupine (within) tj. eng. mixed models.
Tablični prikaz opisne statistike i analize varijance može se izvesti i s drugim vrlo korisnim paketima koji imaju mogućnost prikaza tablice koja je pogodna za znanstvene članke. Jedan od takvih paketa je gtsummary (Sjoberg et al., 2021), rstatix (Kassambara, 2023b), zatim afex (Singmann et al., 2022) i apatables. Za potrebe simulacije koristit ćemo ugrađene podatke iz baze podataka trial.
Rstatix je odlična biblioteka, paket funkcija koji omogućava jednostavno korištenje modela analize varijance, bilo da je riječ o jednostavnoj ili složenoj analizi s ponovljenim mjerenjima. U slijedećm primjeru, malo prerađen prema isrpnoj dokumentaciji i sa javnog servisa Rpubs (https://rpubs.com/), autora Jedrzeja Alickog (https://rpubs.com/jedrzej_alicki/).
U primjeru su korištene varijable iz datoteke selfesteem a koja se nalazi u paketu datarium (Kassambara, 2019). Za potrebe ovog primjera, potrebno je napraviti rotiranje matrice.
library(datarium)
library(kableExtra)
library(rstatix)
# okretanje podataka iz wide u long format
table_long <- gather(selfesteem, time, score, t1:t3, factor_key=TRUE)
# tablica deskriptivne statistike
table <- table_long %>%
group_by(time) %>%
get_summary_stats(score, type = "full",
show = c("n","mean","sd","max","min","se","q1","q3","median"))
# uređena tablica
kbl(table)| time | variable | n | mean | sd | max | min | se | q1 | q3 | median |
|---|---|---|---|---|---|---|---|---|---|---|
| t1 | score | 10 | 3.140 | 0.552 | 4.005 | 2.046 | 0.174 | 2.914 | 3.486 | 3.212 |
| t2 | score | 10 | 4.934 | 0.863 | 6.913 | 3.908 | 0.273 | 4.411 | 5.301 | 4.601 |
| t3 | score | 10 | 7.636 | 1.143 | 9.778 | 6.308 | 0.361 | 6.700 | 8.440 | 7.463 |
Možemo provjeriti uvjete za korištenje analize varijance za ponovljena mjerenja.
table <- table_long %>%
group_by(time) %>%
shapiro_test(score)
kbl(table)| time | variable | statistic | p |
|---|---|---|---|
| t1 | score | 0.9666901 | 0.8585757 |
| t2 | score | 0.8758846 | 0.1169956 |
| t3 | score | 0.9227150 | 0.3801563 |
Uvjet normaliteta je zadovoljen. Slikovno to izgleda na slijedeći način.
library(ggpubr)
ggqqplot(table_long, "score", ggtheme = theme_bw(),facet.by="time") 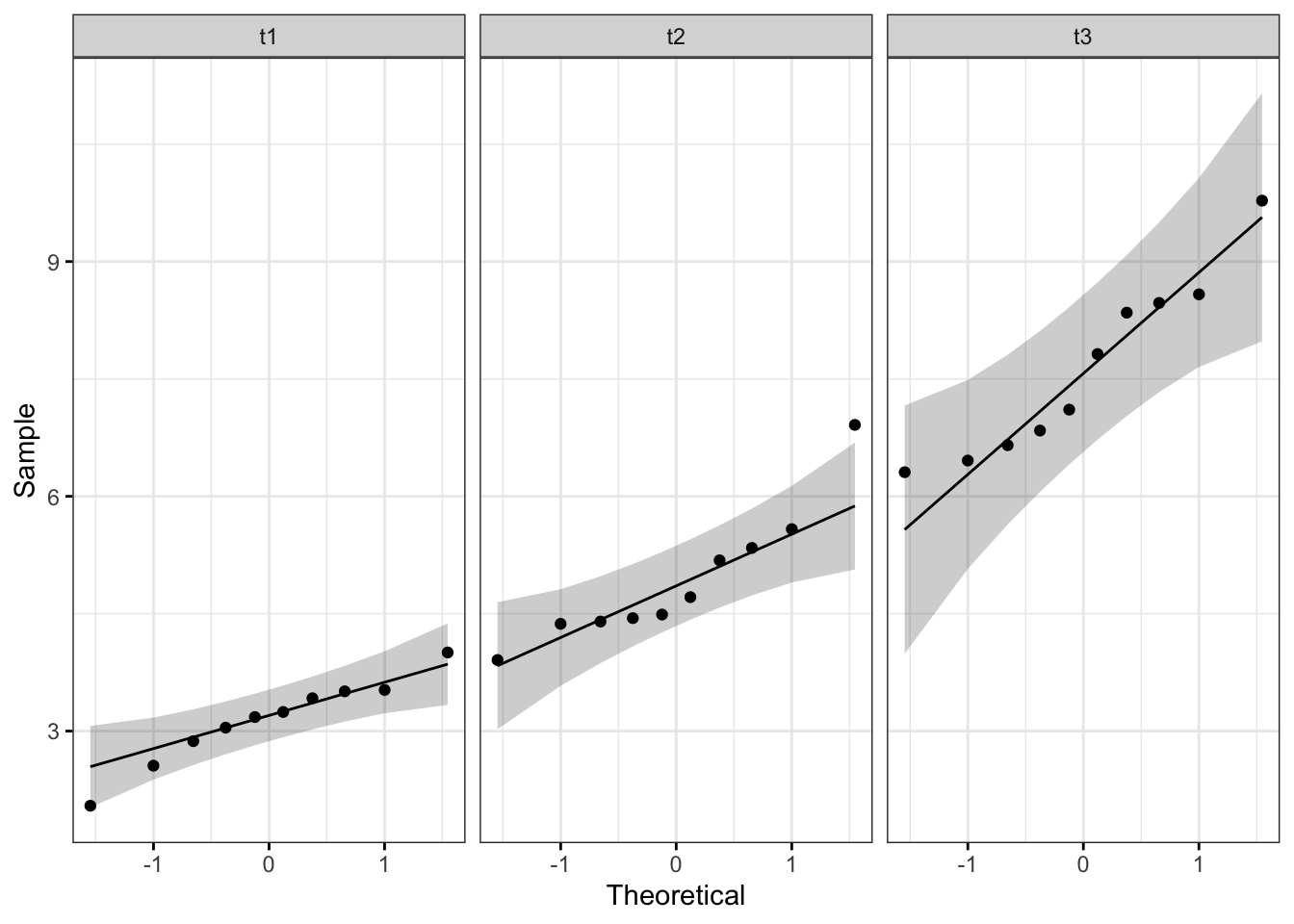
Konačno, analiza varijance s ponovljenim mjerenjima se izvede jednostano na slijedeći način.
library(rstatix)
res.aov<-anova_test(table_long,dv = score, wid = id, within = time)
kbl(res.aov)
|
|
|
Iz rezultata je vidljiva značajnost F omjera, dok je uvjet sfericiteta zadovoljen. Dakle, potrebno je napraviti post hoc test.
pwc <- table_long %>%
pairwise_t_test(score~time, paired = TRUE)
kbl(pwc)| .y. | group1 | group2 | n1 | n2 | statistic | df | p | p.adj | p.adj.signif |
|---|---|---|---|---|---|---|---|---|---|
| score | t1 | t2 | 10 | 10 | -4.967618 | 9 | 7.72e-04 | 2e-03 | ** |
| score | t1 | t3 | 10 | 10 | -13.228148 | 9 | 3.00e-07 | 1e-06 | **** |
| score | t2 | t3 | 10 | 10 | -4.867816 | 9 | 8.86e-04 | 2e-03 | ** |
Objedinjeni slikovni prikaz, prikladan za različite znanstvene publikacije, može se jednostavno napraviti u ggstatsplot paketu (Patil, 2021).
library(ggstatsplot)
ggwithinstats(table_long,time,score)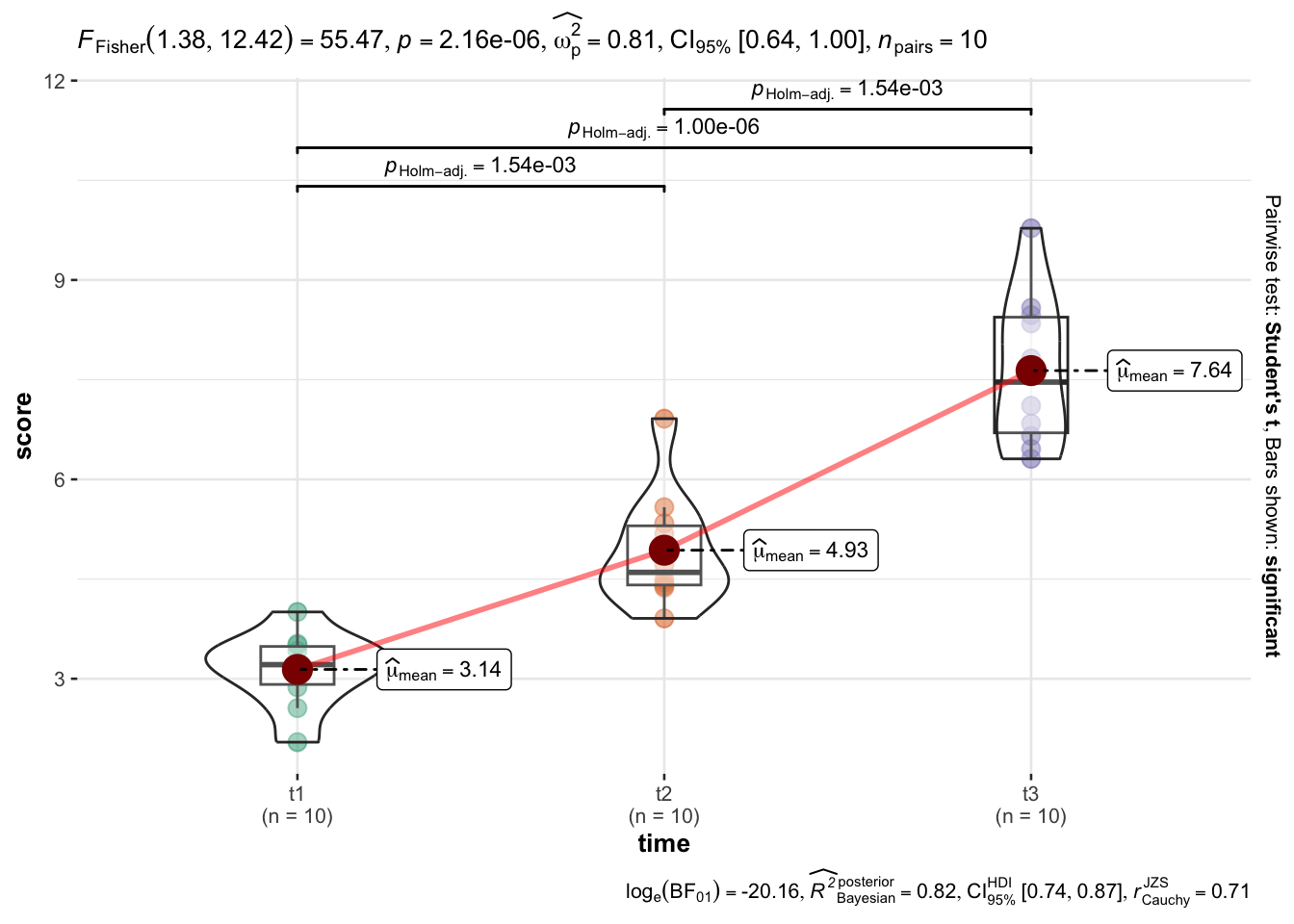
U slijedećem primjeru, možemo demonstrirati miješani model, analiza varijance s ponovljenim mjerenjem ali i analizom između dviju skupina. Za demonstraciju koristit ćemo podatke selfesteem2 koji su dostupni u datarium paketu. Prvo ćemo, kao i u prvotnom slučaju, rotirati matricu s podatcima iz tzv. wide formata u long format.
library(datarium)
library(kableExtra)
library(rstatix)
# okretanje podataka iz wide u long format
table_long2 <- gather(selfesteem2, time, score, t1:t3, factor_key=TRUE)
# tablica deskriptivne statistike
table2 <- table_long2 %>%
group_by(treatment, time) %>%
get_summary_stats(score, type = "full",
show = c("n","mean","sd","max","min","se","q1","q3","median"))
# uređena tablica
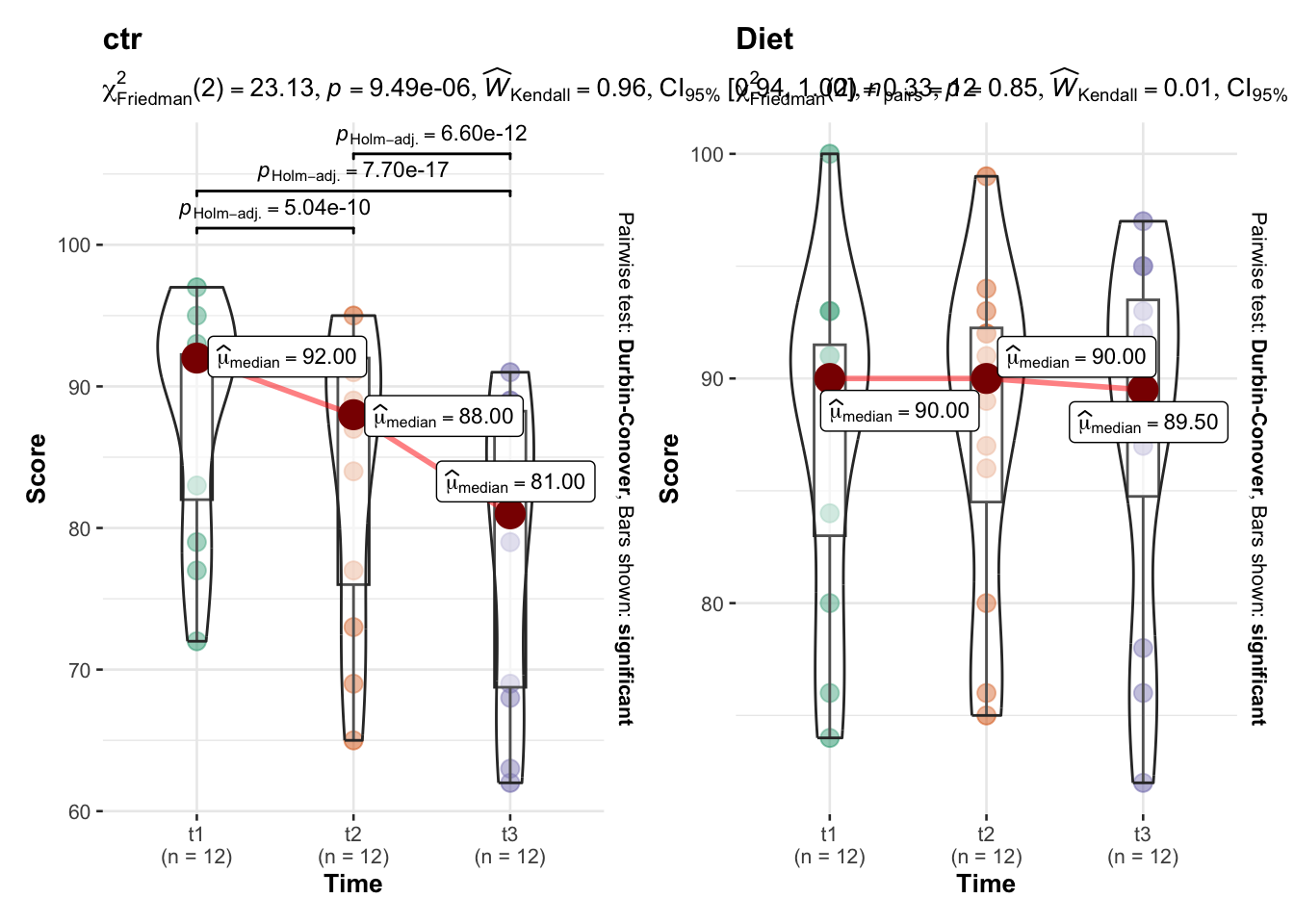
kbl(table2)| treatment | time | variable | n | mean | sd | max | min | se | q1 | q3 | median |
|---|---|---|---|---|---|---|---|---|---|---|---|
| ctr | t1 | score | 12 | 88.000 | 8.079 | 97 | 72 | 2.332 | 82.00 | 92.25 | 92.0 |
| ctr | t2 | score | 12 | 83.833 | 10.232 | 95 | 65 | 2.954 | 76.00 | 92.00 | 88.0 |
| ctr | t3 | score | 12 | 78.667 | 10.543 | 91 | 62 | 3.043 | 68.75 | 88.25 | 81.0 |
| Diet | t1 | score | 12 | 87.583 | 7.621 | 100 | 74 | 2.200 | 83.00 | 91.50 | 90.0 |
| Diet | t2 | score | 12 | 87.833 | 7.420 | 99 | 75 | 2.142 | 84.50 | 92.25 | 90.0 |
| Diet | t3 | score | 12 | 87.667 | 8.139 | 97 | 72 | 2.350 | 84.75 | 93.50 | 89.5 |
Analiza varijance izgleda na slijedeći način.
res.aov2 <- anova_test(table_long2,dv = score, wid = id, within = time, between = treatment)Warning: The 'wid' column contains duplicate ids across between-subjects
variables. Automatic unique id will be createdkbl(res.aov)
|
|
|
Konačno, kreativni slikovni prikaz za publikacije.
library(ggstatsplot)
grouped_ggwithinstats(
data = dplyr::filter(table_long2, treatment %in% c("Diet", "ctr"), time %in% c("t1", "t2", "t3")),
x = time,
y = score,
type = "np",
xlab = "Time",
ylab = "Score",
grouping.var = treatment
)
Jedan od prikladnih načina izvještavanja o rezultatima analize varijance može se dobiti pomoću afex paketa i funkcije nice. Prednost funkcije nice ogleda se u mogućnosti prikaza i dodatnih pokazatelja primjene analize varijance kao što je izračun efekta učinka.
Kod višestrukih usporedbi u modelu analize varijance potrebno je koristiti korigiranu p vrijednost (p-adjusted) te se na taj način izbjegava umnažanje pogreške tipa I. U te svrhe koristi se procedura aov (car paket) i anova tablica (anova_table).
Koristeći tri paketa, u slijedećem primjeru demostrirati ćemo način na koji se može provesti analiza varijance s ponovljenim mjerenjima (within subject) a koja uključuje i varijablu neovisnih uzoraka (between subject). Prikazati ćemo primjer sa službenih stranica paketa apaTables, koristeći ez (Lawrence, 2016) paket uz već postojeće apaTables i tidyverse.
U prvih par koraka treba pripremiti varijable tj. prebaciti iz tzv. širog formata datoteke u uski format datoteke.
library(apaTables)
library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ lubridate 1.9.3 ✔ tibble 3.2.1
✔ purrr 1.0.2 ✔ tidyr 1.3.1
✔ readr 2.1.5
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ psych::%+%() masks ggplot2::%+%()
✖ psych::alpha() masks ggplot2::alpha()
✖ tidyr::expand() masks Matrix::expand()
✖ rstatix::filter() masks dplyr::filter(), stats::filter()
✖ kableExtra::group_rows() masks dplyr::group_rows()
✖ dplyr::lag() masks stats::lag()
✖ tidyr::pack() masks Matrix::pack()
✖ dplyr::recode() masks car::recode()
✖ MASS::select() masks rstatix::select(), dplyr::select()
✖ purrr::some() masks car::some()
✖ tidyr::unpack() masks Matrix::unpack()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(ez)
# prebacivanje iz širog u uski format
drink_attitude_long <- tidyr::pivot_longer(drink_attitude_wide,
cols = beer_positive:water_neutral,
names_to = c("drink", "imagery"),
names_sep = "_",
values_to = "attitude")
drink_attitude_long$drink <- as_factor(drink_attitude_long$drink)
drink_attitude_long$imagery <- as_factor(drink_attitude_long$imagery)U drugom koraku pozivamo funkciju ezANOVA iz paketa ez kojim provodimo analizu varijance nad varijablama iz ‘dugog’ formata.
options(digits = 10)
drink_attitude_results <- ezANOVA(data = drink_attitude_long,
dv = .(attitude),
wid = .(participant),
within = .(drink, imagery),
type = 3,
detailed = TRUE)
table11 <- apa.ezANOVA.table(drink_attitude_results,
table.number = 11)
table11
Table 11
ANOVA results
Predictor df_num df_den Epsilon SS_num SS_den F p ges
(Intercept) 1.00 19.00 11218.01 1920.11 111.01 .000 .41
drink 1.15 21.93 0.58 2092.34 7785.88 5.11 .030 .12
imagery 1.49 28.40 0.75 21628.68 3352.88 122.56 .000 .58
drink x imagery 3.19 60.68 0.80 2624.42 2906.69 17.15 .000 .14
Note. df_num indicates degrees of freedom numerator. df_den indicates degrees of freedom denominator.
Epsilon indicates Greenhouse-Geisser multiplier for degrees of freedom,
p-values and degrees of freedom in the table incorporate this correction.
SS_num indicates sum of squares numerator. SS_den indicates sum of squares denominator.
ges indicates generalized eta-squared.
# tablicu možemo spremiti u odvojenu datoteku, npr. u doc format (Word)
# apa.save(filename = "table11.doc",
# table11)Kod primjene modela analize varijance, važno je obratiti pozornost na ujednačenost ili ‘balansiranost’ modela. Ujednačeni model pretpostavlja jednaki broj ispitanika u svakoj podskupini nezavisne varijable koja je predmet analize tj. ako imamo tri ili više skupina ispitanika koje uspoređujemo po rezultatima zavisne varijable.
Zašto je to važno u primjeni u R jeziku? Funkcije u R jeziku koriste jedan od tzv. tri modela izračuna ukupne varijance (SS-I, SS-II, SS-III). Primjerice, funkcija aov() je prilagođena za balansirane, ujednačene modele gdje je jednak broj ispitanika u svakoj skupini. U slučaju korištenja navedene funkcije u neujednačenim modelima, velika je vjerojatnost krive interpretacije rezultata i dobivanja vrlo neobičnih zaključaka. Za druge (SS-II, i SS-III) potrebno je posegnuti za funkcijama koje smo prošli u ovom tekstu u okviru npr. car paketa. Neki paketi, poput lmerTest su napravljeni s ciljem provedbe tipa I, II i III za jednostavne i složene modele analize varijance (Kuznetsova et al., 2017).
6.8 Povezanosti, korelacije
Korelaciju u statistiku je uveo Karl Pearson (1857-1936) (porter1988?). K. Pearson je bio promotor eugenike, bavio se različitim područjima filozofije i iznimno je utjecao na ogroman značaj kvantitativnih metoda u društvenim znanostima. Sir Francis Galton (1822-1911), rođak od Charles Darwina, je također jedan od prvih zagovaratelja uporabe korelacija, prvenstveno u medicini i biologiji a kasnije i šire u područje psihologije i antropologije.
Što je to uopće korelacija? Riječ i pojam korelacija dolazi od latinskog korijena, lat. con-sa i relatio-odnos. Korelacija istražuje suodnos ili povezanost dviju varijabli gdje se taj odnos pokušava što bolje razumjeti kvantitativnim i slikovnim izražavanjem. Povezanost pojava može biti funkcionalna i statistička. Drugim riječima, veza između dviju varijabli može biti takva gdje je jedna vrijednost varijable (x) povezana s jednom vrijednosti druge varijable (y). No, može biti i takva povezanost gdje jednoj vrijednosti varijable (x) odgovara više vrijednosti varijable (y). U stvarnim životnim pitanjima i problemima, gotovo nikada nije slučaj gdje je jedna varijabla povezana s isključivo drugom varijablom. Gotovo uvijek je riječ po povezanosti više varijabli i njihovoj međusobnoj složenoj interakciji i odnosu. Korelacija je povezanost a ne uzročno posljedična veza.
Korelacija i regresijska analiza omogućavaju rješavanje problema gdje iz poznavanja vrijednosti jedne varijable, s određenom vjerojatnošću možemo procijeniti vrijednost druge varijable. Korelacija se tumači kao dvosmjerna povezanost tj. ne znači nužno i samo gdje je x povezan s y, već i tada govorimo o poveznosti y sa x. Takvih primjera u praksi ima bezbroj, od povezanosti visine i težine, zatim duljine učenja i ocjena, ocjena i uspješnosti na poslu, količina soli u hrani i velične kolesterola u krvi, visina prihoda i potrošnje itd.
Koeficijent korelacije (r) pokazuje snagu i smjer odnosa između dvije varijable ili događaja ili mjerenja. Može poprimiti vrijednost od -1 do +1 a to znači od negativne korelacije do potpune negativne ili pozitivne korelacije Što je vrijednost korelacije bliže – 1 ili +1 to je snažnija povezanost. Vrijednosti koeficijenta korelacija (r) od 0 – 0.25 ili 0 - -0.25 upućuju kako nema povezanosti ili je jako slaba povezanost, od 0.25 – 0.5 ili -0.25 - -0.5 na slabu ili približno srednju povezanost, od 0.5 – 0.75 ili -0.5 do -0.75 je umjerena ili dobra povezanost, dok koeficijent korelacije s vrijednostima od 0.75 – 1 ili -0.75 - -1 možemo tumačiti kao izvrsnu ili jaku povezanost. Uz veličinu koeficijenta korelacija (r), navodi se i značajnost (p) i veličina uzorka (N) na kojemu je dobivena vrijednost navedenog koeficijenta.
Kakav je odnos vrijednosti dviju varijabli gdje analiziramo povezanost ili visinu koeficijenta korelacija? Kada manja vrijednost jedne varijable odgovara brojčano manjoj vrijednosti druge varijable, riječ je o pozitivnoj korelaciji. Također, kada više ili visoke vrijednosti jedne varijable odgovaraju visokoj ili velikoj vrijednosti druge varijable, tada je naravno riječ o pozitivnoj korelaciji. Mala ili niža vrijednost jedne varijable odgovara višoj ili velikoj vrijednosti druge varijable, tada je riječ o negativnoj korelaciji. Linearan porast jedne varijable odgovara linearno opadanje druge varijable.
Osim navedenih odnosa, imamo i drugačije, nepravilnije odnose. Kada vrijednost jedne varijable u nekim intervalima odgovara maloj vrijednosti druge varijable, a u drugim intervalima velikoj ili višoj vrijednosti, riječ je o nemonotonoj korelaciji. Ukoliko se korelacija više nego jednom mijenja od pozitivne prema negativnoj, takva korelacija naziva se ciklička korelacija. Konačno, kada se na temelju vrijednosti jedne varijable ne može zaključiti ništa o vrijednosti druge varijable, tada korelacija, povezanost ne postoji tj. približno je jednaka nuli.
Oblik povezanosti koji u pravilu vidimo iz slikovnog prikaza te također i vrijednosti opisne statistike, određuje i korištenje različitih koeficijenata korelacija:
Linearni odnos između dvije varijable (Pearson koeficijent korelacija, Pearson’s product-moment coefficient)
Nelinearni odnos ili varijable koje su na ordinalnoj mjernoj ljestvici (Spearman koeficijent korelacije)
Nelinearni odnos ili varijable koje su na nominalnoj i ordinalnoj mjernoj ljestvici (neparametrijski koeficijent korelacije, Kendall tau rang koeficijent korelacije)
Nelinearni i zakrivljeni odnosi među varijablama, prikladni koeficijenti zakrivljene korelacije
Veći broj varijabli (veći od 2) tada je riječ o jednostavnoj i višestrukoj regresijskoj analizi.
Korelacije u R jeziku je moguće napraviti pomoću jednostavne funkcije cor() a tako i analize kovarijance cov().
Kada razmatramo korelaciju i regresijsku analizu, tada su važni kvantitativni pokazatelji povezanosti (koeficijenti povezanosti, značajnosti) i kvalitativni, slikovni pokazatelji (koji su istovremeno i kvantitativni i kvalitativni).
Najjednostavniji odnos, je odnos dviju varijabli (x,y) koji, zbog metodoloških razloga, nije ‘čist’, već je opterećen različitim pogreškama mjerenja. To je u znanstvenim istraživanjima iznimno važno, jer nastojimo analizirati odnos između dviju varijabli bez šuma. Takva vrsta korelacija naziva se korelacija s korekcijom zbog atenuacije. Naravno, kvantitativni pokazatelj povezanosti (r) je u tom slučaju, naravno - manji.
Korelacijski koeficijenti su brojni, ovisno o prirodi odnosa između dviju varijabli:
Linearni koeficijent korelacije (Pearson)
Rang koeficijent korelacije (Spearman)
Rang i kategorijski koeficijent (Kendall tau)
Nelinearni, zakrivljeni koeficijent (Eta)
Interpretacija kvantitativnog pokazatelja povezanosti (r) je na način;
ako je r=-1, što je rijetko ili gotovo nikada, primjerice u području društvenih i biomedicinskih znanosti - znači savršenu negativnu povezanost. Kako raste vrijednost varijable x, pada vrijednost varijable y.
ako je r=0, to znači kako između varijable x i y nema odnosa i povezanosti. Što je vrijednost bliža nuli, to u većoj mjeri znači kako nema povezanosti.
r=1, znači potpunu povezanost. Iz varijable x se točno može predvidjeti vrijednost varijable y. U slučaju, linearne povezanosti (Pearson), to znači potpunu pozitivnu povezanost. Kako raste vrijednost varijable x, raste i vrijednost varijable y.
Formula za izračunavanje Pearson linearnog koeficijenta korelacija glasi na slijedeći način.
\[ r = \frac{{}\sum_{i=1}^{n} (x_i - \overline{x})(y_i - \overline{y})} {\sqrt{\sum_{i=1}^{n} (x_i - \overline{x})^2 \sum_{i=1}^{n}(y_i - \overline{y})^2}} \]
U slučaju Spearman koeficijenta, formula se mijenja i izgleda na slijedeći način:
\[ \rho = 1- {\frac {6 \sum d_i^2}{n(n^2 - 1)}} \]
Jedan od najčešće korištenih koeficijenata korelacija je Pearsonov linearni koeficijent a za koji postoje određene pretpostavke za korištenje;
dvije varijable trebaju zadovoljiti normalnu raspodjelu a što možemo testirati pomoću Shapiro-Wilk testa i slikovno provjeriti pomoću histograma s interpolacijom normalne krivulje i Q-Q prikazom
odnos između dvije varijable treba biti linearan. Ukoliko nije linearan tada treba pribjeći korištenju nekog drugog koeficijenta korelacija. Slikovno treba prikazati odnos između dvije varijable pomoću točkastog slikovnog prikaza i pravca regresije.
uzorak bi trebao biti barem veći od 30
Značajnost povezanosti možete se provjeriti pomoću funkcije cor.test()
cor.test(mtcars$wt, mtcars$mpg, method = "pearson", conf.level = 0.9)
Pearson's product-moment correlation
data: mtcars$wt and mtcars$mpg
t = -9.5590441, df = 30, p-value = 1.293959e-10
alternative hypothesis: true correlation is not equal to 0
90 percent confidence interval:
-0.9259151499 -0.7690872079
sample estimates:
cor
-0.8676593765 Što znači testiranje hipoteze pri korištenju testa koeficijenta korelacija;
Ho (nema povezanosti između varijable x i y)
Ha - (ima povezanosti između varijable x i y)
U praksi često koristimo koeficijente korelacija i regresijske analize. No, u čemu je razlika?
Regresijska analiza prvenstveno je usmjerena na model i predikciju. Prediktor ili prediktori (nezavisne varijable) su u određenom odnosu s kriterijem (zavisna varijabla). Prediktori se označavaju s \(x_1\), \(x_2\), \(x_3\) … \(x_i\), dok se u modelu regresijske analize kriterij, zavisna varijabla označava s \(y\) a u složenim multivarijatnim modelima \(y_i\).
Korelacije su prvenstveno usmjerene za opisivanje smjera i snage odnosa između dviju varijabli ili opisivanja odnosa između dviju varijabli u kontekstu matrice korelacija (većeg broja varijabli)
Regresijska analiza je usmjerena na utjecaj i objašnjavanje ‘težine’ pojedinog prediktora te kakva je regresijska linija. Opis regresijskog oblaka i pravca regresije dodatno objašnjava u kakvom su odnosu varijable ili konstrukti.
U osnovnom paketu (R-base), najjednostavnije korištenje ili kvantitativno izražavanje korelacije je pomoću funkcije cor(). U toj funkciji imamo niz argumenata a među ostalim, što je prethodno rečeno i vrsta koeficijenta (Pearson, Spearman, Kendall tau).
cor(x, y = NULL, use = "everything", method = c("pearson", "kendall", "spearman"))
Uz funkciju koja se nalazi u R-base, korelacije možemo napraviti u brojnim drugim bibliotekama, paketima. Jedan od vrlo korisnih je apaTables koji omogućava pripremu tablice za objavljivanje u znanstvenom časopisu.
Means, standard deviations, and correlations with confidence intervals
Variable M SD 1 2 3 4
1. rating 64.63 12.17
2. complaints 66.60 13.31 .83**
[.66, .91]
3. privileges 53.13 12.24 .43* .56**
[.08, .68] [.25, .76]
4. learning 56.37 11.74 .62** .60** .49**
[.34, .80] [.30, .79] [.16, .72]
5. raises 64.63 10.40 .59** .67** .45* .64**
[.29, .78] [.41, .83] [.10, .69] [.36, .81]
6. critical 74.77 9.89 .16 .19 .15 .12
[-.22, .49] [-.19, .51] [-.22, .48] [-.25, .46]
7. advance 42.93 10.29 .16 .22 .34 .53**
[-.22, .49] [-.15, .54] [-.02, .63] [.21, .75]
5 6
.38*
[.02, .65]
.57** .28
[.27, .77] [-.09, .58]
Note. M and SD are used to represent mean and standard deviation, respectively.
Values in square brackets indicate the 95% confidence interval.
The confidence interval is a plausible range of population correlations
that could have caused the sample correlation (Cumming, 2014).
* indicates p < .05. ** indicates p < .01.
Istu tablicu, možemo napraviti za pdf format.
library(apaTables)
ApaTablePrimjer <- apa.cor.table(attitude)
# apa.knit.table.for.pdf(ApaTablePrimjer)
6.8.1 Točkasti slikovni prikazi
Pri korištenju korelacija u istraživanjima, moramo uvijek koristiti slikovne prikaze. Bez slikovnih prikaza izlažemo se značajnom riziku od metodoloških pogrešaka koje nas mogu dovesti do pogrešnih zaključaka. Uz kvantitativni pokazatelj povezanosti, slikovni prikaz donosi informacije koje ne možemo vidjeti iz koeficijenta korelacija, poput odnosa između dviju varijabli duž pravca regresije ili uočavanje vrijednosti koje mijenjaju vrijednost koeficijenta korelacije. Prema tome, velika je važnost slikovnog prikaza a slučaju koeficijenta korelacija i R omogućava vrlo kreativne i informativne načine točkastih slikovnih prikaza (scatterplot). Točke (pojedinačne vrijednosti) tvore tzv. oblak vrijednosti kojeg u regresijskoj analizi zovemo oblak regresije gdje se vrijednosti nalaze oko pravca kojeg nazivamo pravac regresije, regresijski pravac ili linija regresije. Što su točke bliže pravcu, oblak je manji i tada je numerički veća vrijednost koeficijenta korelacija (r). U linearnoj korelaciji, točke se grupiraju oko pravca a kod nelinearne korelacije oko neke druge krivulje.
Pojava koja opisuje jednoliko raspršenje oko pravca regresije naziva se homoscedascitet tj. jednakost ili jednolikost raspšenosti točaka oko pravca regresije. Slikovni točkasti prikazi su iznimno značajni jer omogućavaju uočavanje odstupajućih vrijednosti (outliere) koji značajno mogu promijeniti korelaciju i tumačenje.
Iz točkastog slikovnog prikaza je vidljiv: smjer, jačina, oblik i postojanje odstupajućih vrijednosti (outliera). U R jeziku mogući su različiti točkasti slikovni prikazi ovisno o paketu koji se koristi i pripadajućim funkcijama. Tako, s portala www.r-graph-gallery.com možemo vidjeti primjere različitih točkastih slikovnih prikaza. Ovdje ćemo prikazati dva primjera, jedan koristeći ugrađene funkcije u R jeziku i drugi koristeći neki od paketa, biblioteka.
U slijedećem primjeru možemo jednostavno prikazati točkasti prikaz koristeći postojeće, ugrađene funkcije u R-u.
# pokretanje paketa
library(ggplot2)
# Točkasti slikovni prikaz - odvojeni prikaz ovisan o vrsti (varijabla Species)
ggplot(iris, aes(x=Sepal.Length, y=Sepal.Width, color=Species)) +
geom_point(size=6) 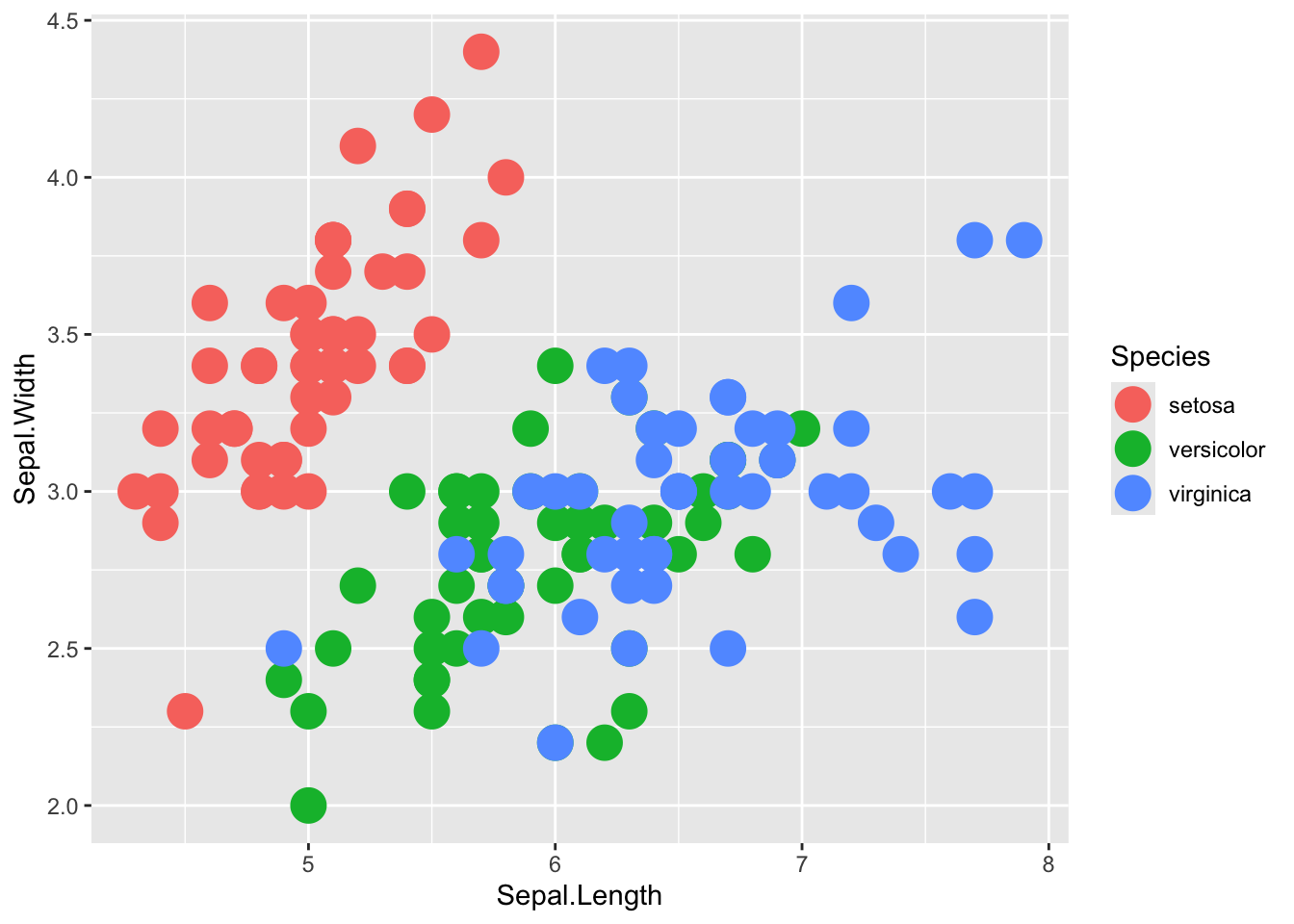
U R jeziku i paketima postoji izvanredan broj mogućnosti vizualizacije analize podataka. Među češće korištenim paketima svakako spadaju funkcije ggplot2 paketa (za detaljnije vidjeti ranije poglavlje Vizualizacija) i posebno za publikacije značajan ggpubr (Kassambara, 2023a).
Točkasti slikovni prikaz s regresijskim pravcem.
Warning: Using `size` aesthetic for lines was deprecated in ggplot2 3.4.0.
ℹ Please use `linewidth` instead.`geom_smooth()` using formula = 'y ~ x'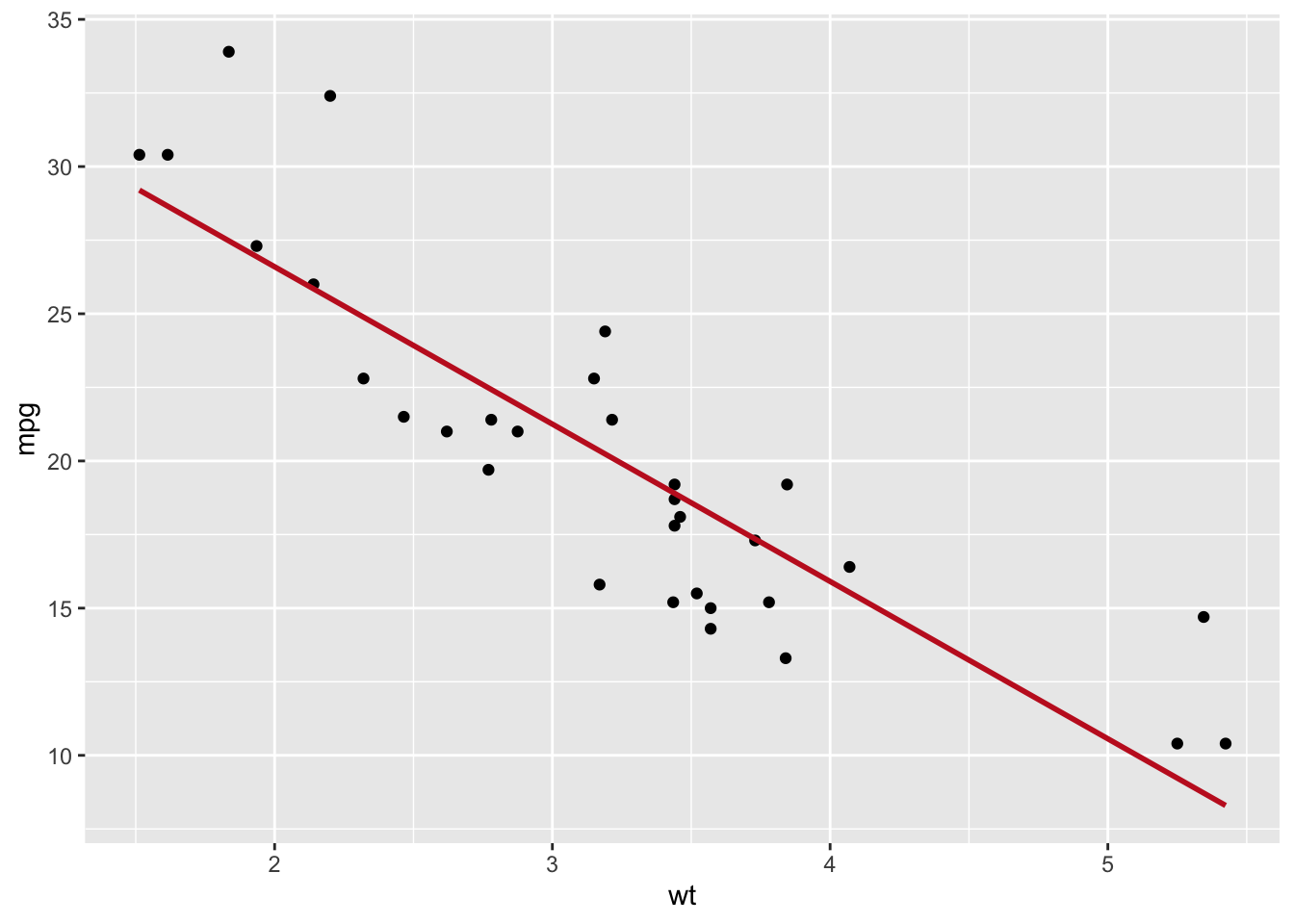
Točkasti slikovni prikaz u matrici s više varijabli.
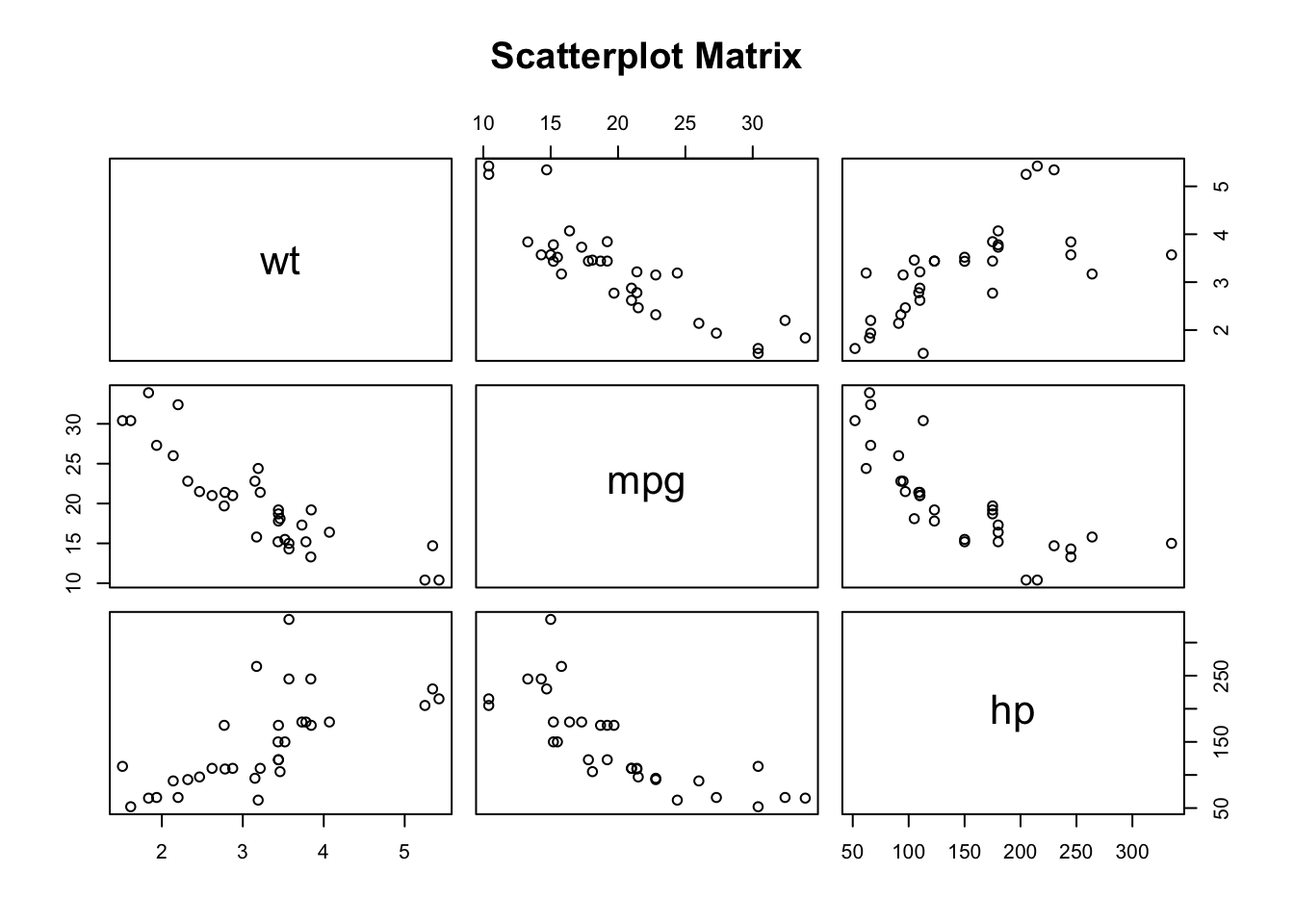
Točkasti slikovni prikaz za određene publikacije gdje je potreban interval pouzdanosti i kvantitativni pokazatelji u okviru slikovnog prikaza.
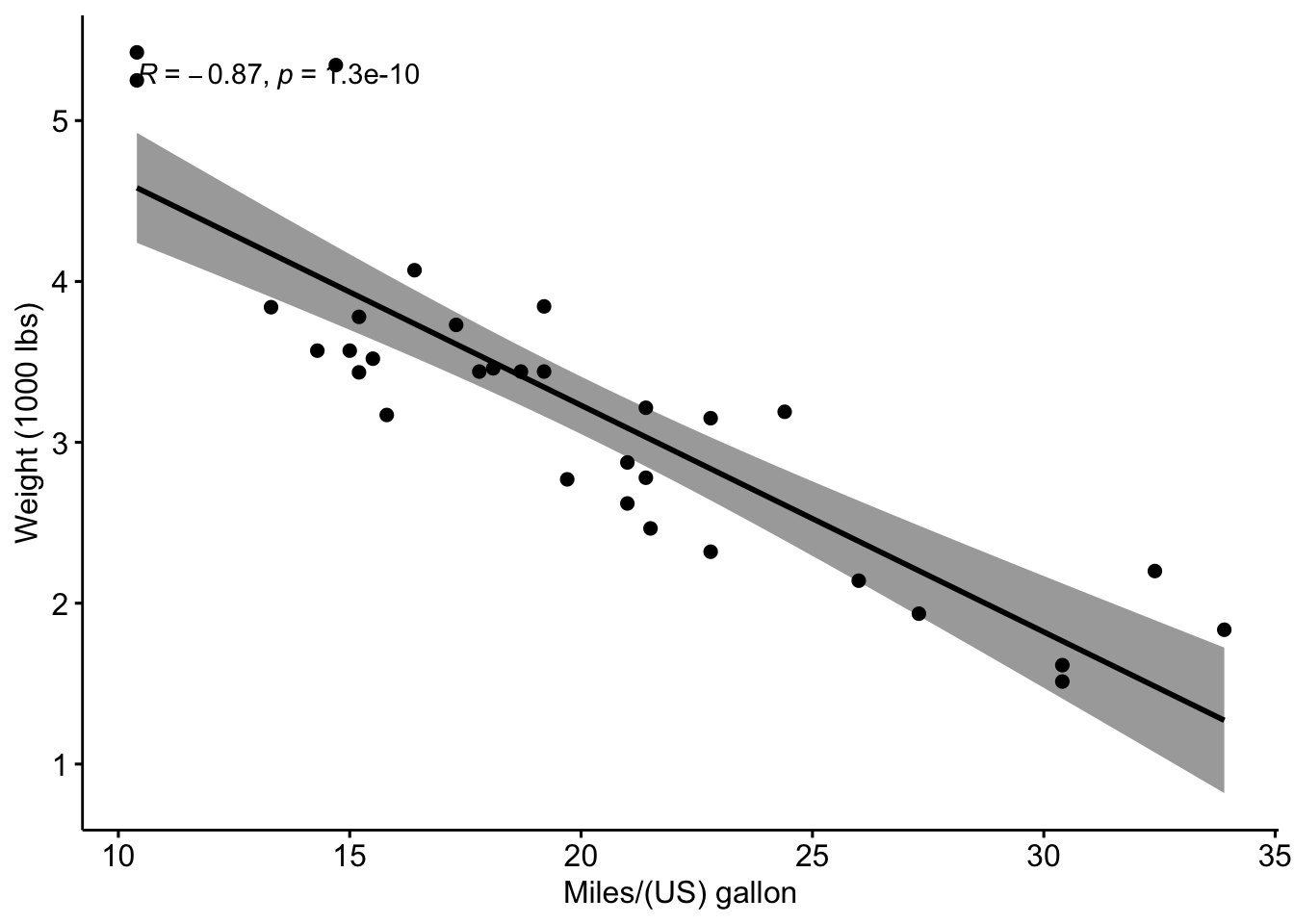
Osim točkastog slikovnog prikaza, korelacije se prikazuju i pomoću korelograma, što možemo jako lijepo i jednostavno napraviti pomoću funkcije corrplot() i paketa corrplot. Korelogram vizualizira matricu koeficijenata korelacija ukazujući na značajne povezanosti između pojedinih varijabli.
library(corrplot)corrplot 0.92 loadedmatrica_kor <- cor(mtcars)
corrplot(matrica_kor, method = "number")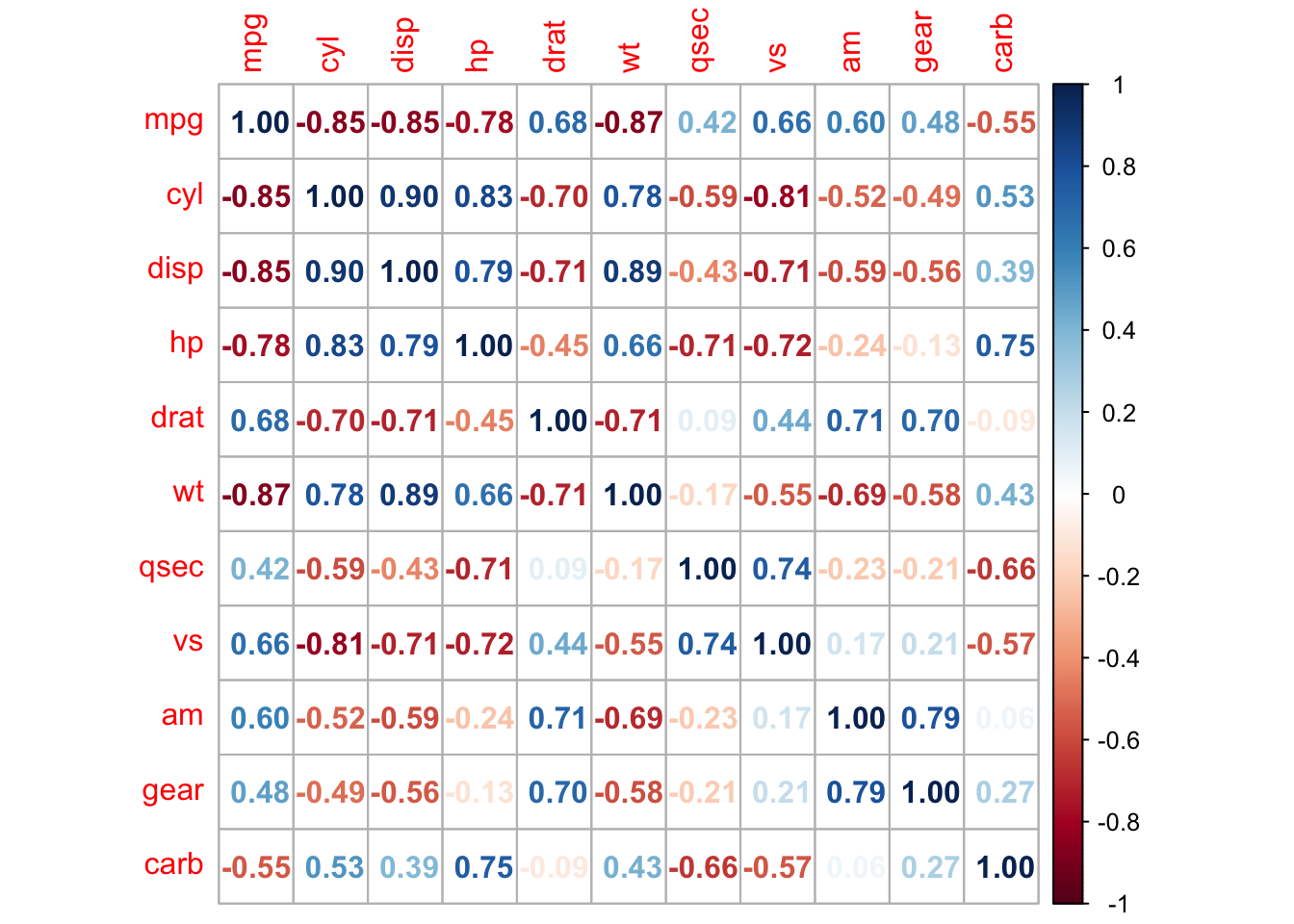
Osim korelograma, u R jeziku i paketima možemo biti vrlo kreativni te vizualno prikazati odnose među varijablama a što može biti značajna pomoć pri interpretaciji i usporedbi modela. Jedan od takvih paketa svakako je corrr (Kuhn et al., 2022). Corrr paket, za razliku od drugih, radi izračun koeficijenata korelacija koristeći data frames dok ostali koriste matrice. Koja je prednost? Omogućava analizu pomoću suvremenih paketa dplyr i tidyverse pomoću kojih se jednostavno može napraviti filtriranje, selekcija i bilo koja druga manipulacija dobivenim koeficijentima. No, što je također zanimljivo, pruža informativne slikovne prikaze, kao što je ovaj koji omogućava analizu odnosa među varijablama.
library(corrr)
datasets::airquality %>%
correlate() %>%
network_plot(min_cor = .2)Correlation computed with
• Method: 'pearson'
• Missing treated using: 'pairwise.complete.obs'
Zašto kvantitativni pokazatelj korelacija nije dovoljan i zašto je nužan slikovni prikaz? To je najbolje izrazio poznati statističar Francis Anscombe 1973., kako određene vrijednosti (outliers) i linearnost / nelinearnost mogu kvantitativno izgledati isto a u slikovnom prikazu sasvim različito (Anscombe, 1973). Anscombe je pokazao kako četri različite varijable koje imaju iste kvantitativne pokazatelje, mogu imati sasvim različite slikovne prikaze i odnose između dviju varijabli! Slijedeći kvantitativni pokazatelji za navedene četri varijable su isti:
broj ispitanika (n=11)
prosječna vrijednost x i y varijable
regresijski koeficijent (b)
jednadžba regresije
suma kvadrata
regresija sume kvadrata
reziduali sume kvadrata
procijenjena standardna pogreška b koeficijenta
kvadrirani R (\[R^2\])
| x1 | x2 | x3 | x4 | y1 | y2 | y3 |
|---|---|---|---|---|---|---|
| 10 | 10 | 10 | 8 | 8.04 | 9.14 | 7.46 |
| 8 | 8 | 8 | 8 | 6.95 | 8.14 | 6.77 |
| 13 | 13 | 13 | 8 | 7.58 | 8.74 | 12.74 |
| 9 | 9 | 9 | 8 | 8.81 | 8.77 | 7.11 |
| 11 | 11 | 11 | 8 | 8.33 | 9.26 | 7.81 |
| 14 | 14 | 14 | 8 | 9.96 | 8.10 | 8.84 |
U paketu dataset, ugrađeni su podatci anscombe koji nam omogućavaju simuliranje navedenog.
cor(anscombe$x1, anscombe$y1)[1] 0.8164205163cor(anscombe$x2, anscombe$y2)[1] 0.816236506Prosječna vrijednost i standardna devijacija su gotovo identitični.
| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| x1 | 1 | 11 | 9.000000000 | 3.316624790 | 9.00 | 9.000000000 | 4.447800 | 4.00 | 14.00 | 10.00 | 0.0000000000 | -1.5289256198 | 1.0000000000 |
| x2 | 2 | 11 | 9.000000000 | 3.316624790 | 9.00 | 9.000000000 | 4.447800 | 4.00 | 14.00 | 10.00 | 0.0000000000 | -1.5289256198 | 1.0000000000 |
| x3 | 3 | 11 | 9.000000000 | 3.316624790 | 9.00 | 9.000000000 | 4.447800 | 4.00 | 14.00 | 10.00 | 0.0000000000 | -1.5289256198 | 1.0000000000 |
| x4 | 4 | 11 | 9.000000000 | 3.316624790 | 8.00 | 8.000000000 | 0.000000 | 8.00 | 19.00 | 11.00 | 2.4669110011 | 4.5206611570 | 1.0000000000 |
| y1 | 5 | 11 | 7.500909091 | 2.031568136 | 7.58 | 7.490000000 | 1.823598 | 4.26 | 10.84 | 6.58 | -0.0483735482 | -1.1991228435 | 0.6125408403 |
| y2 | 6 | 11 | 7.500909091 | 2.031656735 | 8.14 | 7.794444444 | 1.467774 | 3.10 | 9.26 | 6.16 | -0.9786929444 | -0.5143190581 | 0.6125675540 |
| y3 | 7 | 11 | 7.500000000 | 2.030423601 | 7.11 | 7.152222222 | 1.527078 | 5.39 | 12.74 | 7.35 | 1.3801204000 | 1.2400439404 | 0.6121957500 |
| y4 | 8 | 11 | 7.500909091 | 2.030578511 | 7.04 | 7.195555556 | 1.897728 | 5.25 | 12.50 | 7.25 | 1.1207738551 | 0.6287512015 | 0.6122424572 |
Anscombe kvartet - numerički i slikovno.
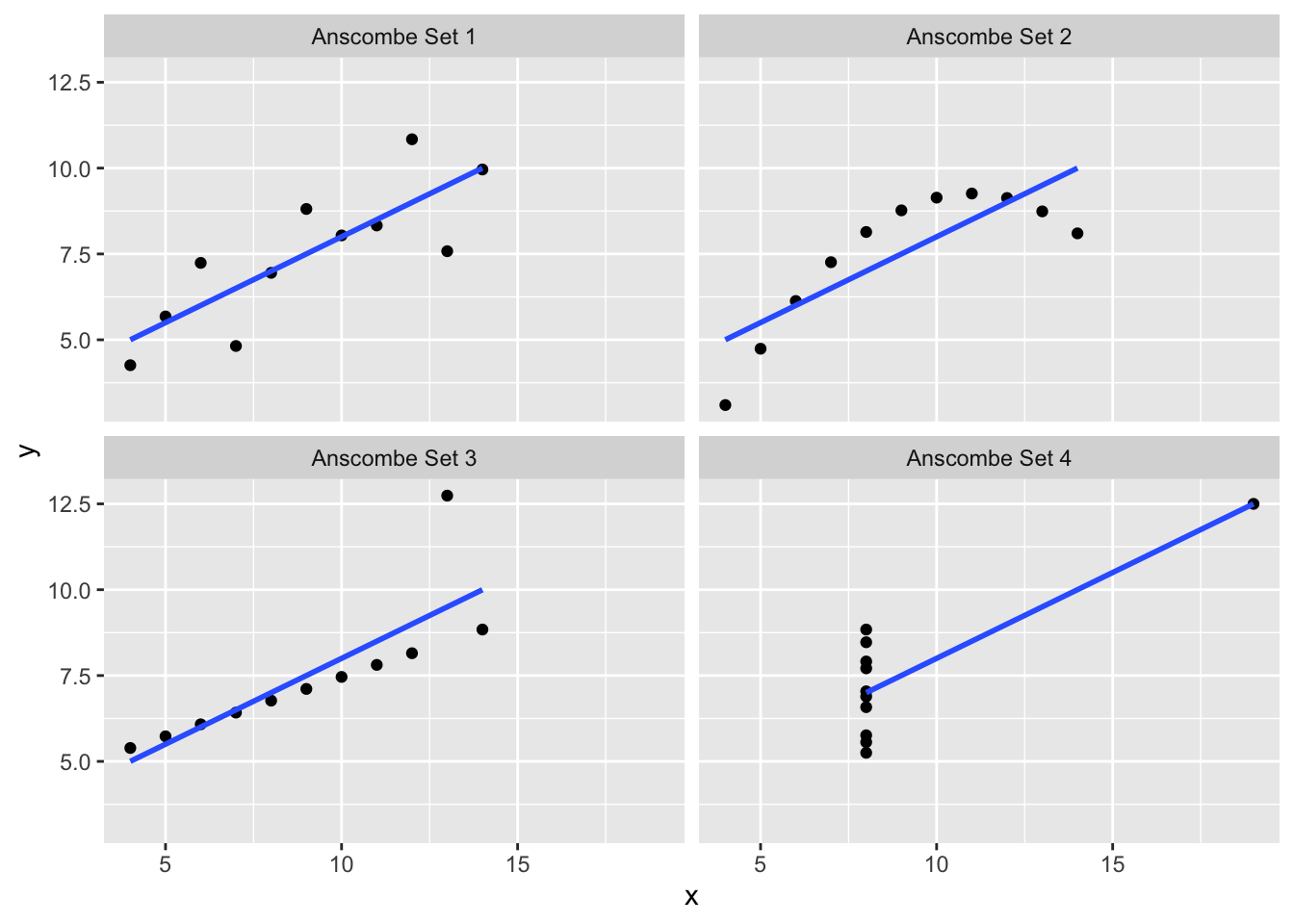
Zaključno, što nam je pokazao anscombe kvartet?
Iznimnu važnost vizualizacije rezultata istraživanja
Važnost vizualizacije pri usporedbi različitih modela, što je još značajnije u regresijskoj analizi
Bez vizualizacije interpretacija može biti vrlo netočna!
6.8.1.1 Zadatci: Korelacije
U carData paketu otvorite skup podataka Ginzberg (opis podataka dostupan na: https://rdrr.io/cran/carData/man/Ginzberg.html). Napravite analizu povezanosti svih varijabli na način da ćete izračunati povezanosti za sve kombinacije varijabli, zatim izračun raspona pouzdanosti i grafički prikaz za značajne povezanosti, uz intepretaciju.
U carData paketu otvorite skup podataka Wong (opis podataka dostupan na: https://rdrr.io/cran/carData/man/Wong.html). Od svih numeričkih varijabli, odredite koju od njih vrijeme provedeno u komi najviše pojedinačno predviđa, te interpretirajte povezanost, uz grafički prikaz.
6.9 Regresijska analiza
Kako predvidjeti vrijednosti jedne varijable, poznavajući vrijednosti druge varijable? Kako analizirati predikciju i povezanost većeg broja varijabli u nekom istraživanju? To su pitanja na koja bi trebala dati odgovor regresijska analiza.
Iz dostupnih riječnika a posebno onih koji se vežu uz određena strukovna udruženja, poput APA riječnika, stoji slijedeća definicija: statistička analiza kojoj je svrha opisivanje, objašnjenje ili predikcija (ili sve troje) varijance zavisne varijable s jednim ili više prediktora ili nezavisnih varijabli.1 Iz navedene definicije proizlazi kako je to jedan od općih linearnih modela (eng. general linear model).
Regresijskih analiza postoji više, pa tako, ovisno o nacrtu istraživanja i/ili mjernoj ljestvici na kojoj se nalazi pojedina varijabla, možemo navesti slijedeće:
linearna regresijska analiza
logistička regresijska analiza
ordinalna logistička analiza
multinomialna logistička analiza
S obzirom na složenost regresijske analize, možemo navesti slijedeće oblike:
jednostavna i višestruka regresijska analiza
linearna i nelinearna regresijska analiza
hijerarhijska regresijska analiza
Linearna regresijska analiza je jedna od najraširenijih modela koji se koristi pri analizi povezanosti i predikcije dviju ili više varijabli. Linearna regresijska analiza pretpostavlja kvantitativne, metričke varijable koje su barem na intervalnoj mjernoj ljestvici. Kako samo ime i govori, u linearnoj regresijskoj analizi pretpostavljamo linearan, jednoliko rastući ili jednoliko padajući izgled regresijske linije koja opisuje odnos između dviju varijabli.
Opća jednadžba linearne regresijske analize između dviju (x i y) varijabli glasi:
\(y = ax + b\)
Što predstavljaju pojedine oznake;
y: zavisna varijabla (u literaturi se naziva i kriterij)
x: nezavisna varijabla (u literaturi se naziva i prediktor)
a: predstavlja nagib linije čija veličina predstavlja u kojoj se mjeri mijenja vrijednost Y za jediničnu promjenu vrijednosti varijable X
b: vrijednost varijable y kada je x nula ili procjena vrijednosti varijable y kada su svi prediktori x jednaki nula. U literaturi se navodi i pod nazivom u engleskom jeziku intercept
Kako izgleda funkcija za provedbu regresijske analize u R-u? To je funkcija lm() koja ima niz argumenata linearne i multivarijatne analize. Prvi argument je formula u kojem simbolički moramo opisati između kojih varijabli želimo napraviti analizu. O sadržaju formule ovisi kako će izgledati regresijska analiza.
Tako, slijdeći modeli mogu biti korisni u praksi:
y ~ x odnos (glavni učinak, main effect) između prediktora x i zavisne varijable y
y ~ x + z glavni učinak x i z kao nezavisnih varijabli na zavisnu varijablu y
y ~ x:z interaktivni učinak x i z nezavisne varijable, predviđena vrijednost y kao posljedica interakcije x i z.
y ~ x + z + x:z glavni učinak nezavisnih varijabli (x i z) uz interaktivni učinak (x i z) na predmet mjerenja y
library(car)
lm_car <- lm(dist ~ speed, data=cars)
summary(lm_car)
Call:
lm(formula = dist ~ speed, data = cars)
Residuals:
Min 1Q Median 3Q Max
-29.069080 -9.525321 -2.271854 9.214715 43.201285
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -17.5790949 6.7584402 -2.60106 0.012319 *
speed 3.9324088 0.4155128 9.46399 1.4898e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 15.37959 on 48 degrees of freedom
Multiple R-squared: 0.6510794, Adjusted R-squared: 0.6438102
F-statistic: 89.56711 on 1 and 48 DF, p-value: 1.489836e-12Koje vrijednosti dobijemo nakon jednostavne regresijske analize:
procijenjena vrijednost, regresijski koeficijent predstavlja vrijednost tj. očekivanu promjenu vrijednosti varijable y (zavisna varijabla) kada se promijeni jedna jedinična vrijednost varijable x (nezavisna varijabla). U prethodnom slučaju, y je dist a x je speed.
standardna pogreška, vrijednost za svaku pojedinu nezavisnu varijablu, očekujemo pogrešku predikcije i procjenu standardne devijacije navedenog koeficijenta.
t vrijednost i pripadajuća p vrijednost, ukoliko je značajan p, tada tumačimo kao statistički značajan odnos između prediktora (nezavisne varijable) i zavisne varijable.
rezidualna standardna pogreška, je mjera kvalitete linearne regresije. Rezidualna standardna pogreška je prosječna vrijednost devijacije od prave regresijske linije. U prethodnom primjeru, stvarna udaljenost zaustavljanja prosječno je 15.38 stopa (4.69 m) udaljena od procijenjene vrijednosti.
stupnjevi slobode, računaju se kao razlika između broja mjerenja i broja parametara regresijske analize. U ovom slučaju imamo samo dva parametra, intercept i slope tj.
koeficijent determinacije, proporcija varijance zavisne varijable (predmeta mjerenja ili kriterija) koja se može objasniti nezavisnim varijablama (prediktorom ili prediktorima)
Nakon što provedemo linearnu regresijsku analizu, u slikovnom prikazu možemo analizirati reziduale tj. prosječno odstupanje između dobivenog rezultata i procijenjene vrijednosti (rezidual = stvarna vrijednost y - predviđena vrijednost y). Reziduali bi trebali biti homoscedastični tj. podjednakog raspršenja s gornje i donje strane linije regresijskog pravca.
Homoscedascicitet je važan uvjet za primjenu parametrijskih testova pa tako i koeficijenta korelacija i regresijske analize. Heteroscedascicitet u suprotnome znači različito odstupanje duž pravca ili linije regresije. Drugim riječima, rezidualne vrijednosti (razlike između predviđenih i stvarnih vrijednosti) trebaju prosječno jednake biti duž pravca ili linije regresije.
U slijedećem vrlo jednostavnom primjeru, možemo vidjeti kako izgleda regresijski pravac i rezidualne vrijednosti. U okviru R sustava imamo ugrađene primjere podataka te tako i podatke koji su pospremljeni u mtcars a odnose se na podatke iz 70-tih godina 20. stoljeća o potrošnji pojedinih automobila, snazi, težini i sličnim podatcima.
Prvo ćemo jednom objektu dodijeliti podatke iz mtcars a zatim izvući podatke koji su potrebni za izradu slikovnog prikaza i interpretaciju razlike između stvarnih i predviđenih vrijednosti. Napravit ćemo regresijsku analizu na koji način je težina povezana s potrošnjom goriva te u kojoj mjeri težina predviđa potrošnju automobila.
primjer_reziduali <- mtcars
ra_primjer_reziduali <- lm(mpg~wt, data = primjer_reziduali)
primjer_reziduali$predvidjene_vr <- predict(ra_primjer_reziduali)
primjer_reziduali$rezidualne_vr <- residuals(ra_primjer_reziduali)Nakon što smo dobili vrijednosti, slijedi izrada slikovnog prikaza pomoću ggplot2 paketa. Primjer slikovnog prikaza s argumentima preuzet s: https://drsimonj.svbtle.com/visualising-residuals.
library(ggplot2)
ggplot(primjer_reziduali, aes(x = wt, y = mpg)) +
geom_smooth(method = "lm", se = FALSE, color = "lightgrey") +
geom_segment(aes(xend = wt, yend = predvidjene_vr), alpha = .2) +
geom_point() +
geom_point(aes(y = predvidjene_vr), shape = 1) +
theme_bw() `geom_smooth()` using formula = 'y ~ x'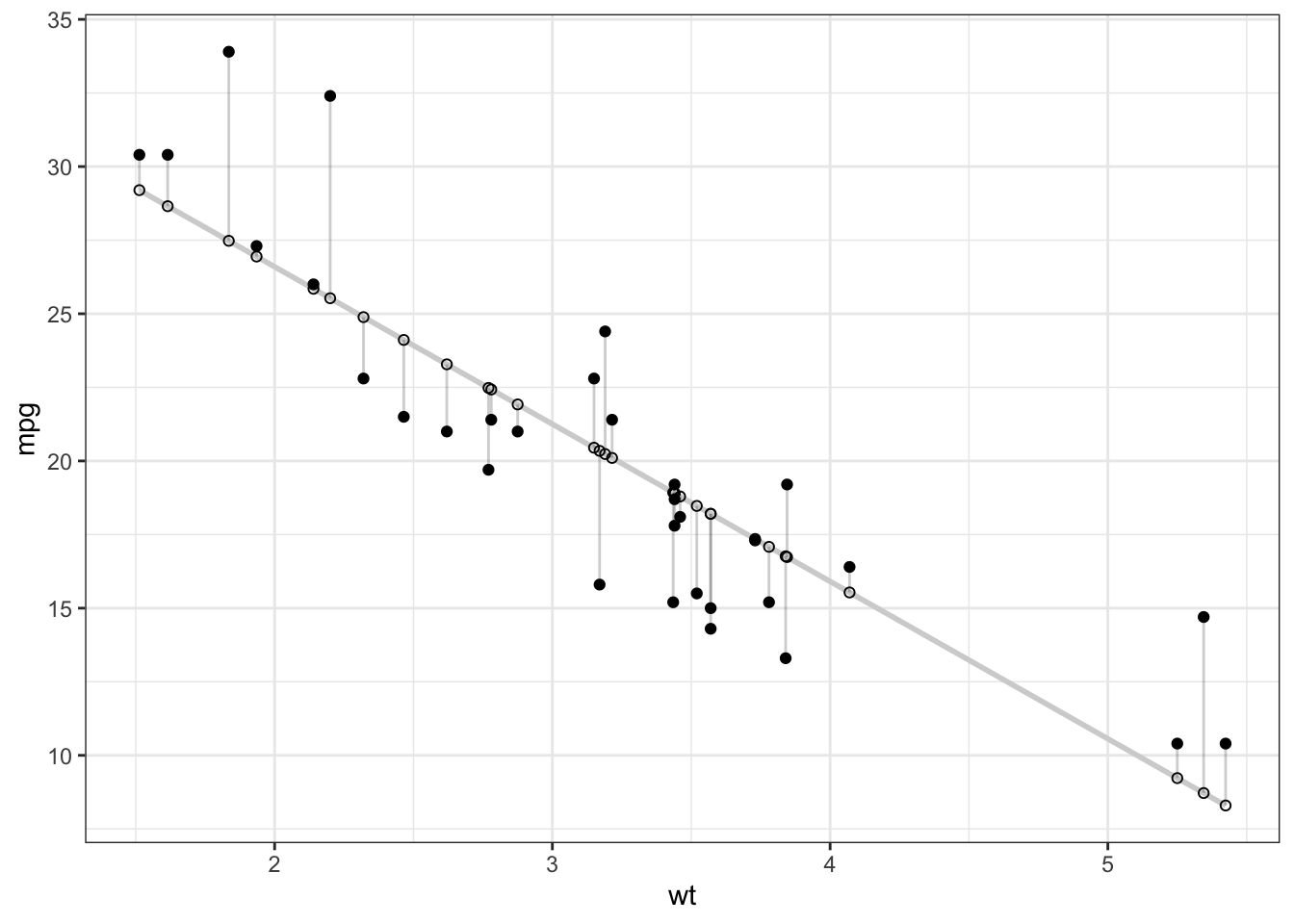
Ukratko, koji su uvjeti i ograničenja za uporabu regresijske analize:
Opisna (deskriptivna) analiza varijabli koje se želi analizirati pomoću regresijske analize. To uključuje tablični i slikovni prikaz uz analizu raspodjela vrijednosti pojedine varijable. Opisno i slikovno analizirati uvjete za parametrijsku statistiku.
Ukloniti odstupajuće vrijednosti (outliers) u pojedinim varijablama temeljem pokazatelja u prvom koraku
Ukloniti vrijednosti koje nedostaju (missing values, no answers) što se može na različite načine npr. drop_na() pomoću paketa, biblioteke tidyverse
Provjera homogenosti varijanci
Provjera normaliteta i linearnosti
Provjera rezidualnih vrijednosti (trebaju biti neovisne varijable jedna od druge)
Provjera značajnih p vrijednosti nakon primjene regresijske analize te posebno obratiti pažnju na ekstremne vrijednosti tj. ukoliko su koeficijenti visoki uz postojanje p vrijednosti koje nisu značajne
Tablice regresijske analize a koje su poprilično uređene za publikacije u APA stilu, mogu se jednostavno izraditi pomoću paketa apaTables (Stanley, 2023). apaTables ima odličnu dokumentaciju s primjerima, pa tako zbog demonstracije možemo vidjeti jedan takav, gdje rezultat provedene analize možemo prikazati ili spremiti u doc format.
library(apaTables)
basic.reg <- lm(sales ~ adverts + airplay,
data = album)
table2 <- apa.reg.table(basic.reg)
table2
Regression results using sales as the criterion
Predictor b b_95%_CI beta beta_95%_CI sr2 sr2_95%_CI r
(Intercept) 41.12** [22.72, 59.53]
adverts 0.09** [0.07, 0.10] 0.52 [0.44, 0.61] .27 [.18, .36] .58**
airplay 3.59** [3.02, 4.15] 0.55 [0.46, 0.63] .29 [.20, .38] .60**
Fit
R2 = .629**
95% CI[.55,.69]
Note. A significant b-weight indicates the beta-weight and semi-partial correlation are also significant.
b represents unstandardized regression weights. beta indicates the standardized regression weights.
sr2 represents the semi-partial correlation squared. r represents the zero-order correlation.
Square brackets are used to enclose the lower and upper limits of a confidence interval.
* indicates p < .05. ** indicates p < .01.
#Možemo tablicu spremiti u doc format na računalu
#apa.save(filename = "table2.doc",
# table2)Posebno korisna procedura u primjeni regresijske analize je usporedba različitih modela regresijske analize, kako bi izabrali onaj s većim udjelom objašnjene varijance ili regresijski model koji je jednostavniji s manjim brojem varijabli koje objašnjavaju variranje u zavisnoj varijabli. U engleskom govornom području za takav pristup usporedbe modela koristi se pojam block-based regression. Iz primjera sa službenih stranica paketa apaTables, može se vidjeti kako jednostavno napraviti usporedbu dva regresijska modela.
library(apaTables)
block1 <- lm(sales ~ adverts + airplay, data = album)
block2 <- lm(sales ~ adverts + airplay + I(adverts*airplay), data = album)
table3 <- apa.reg.table(block1, block2)
table3
Regression results using sales as the criterion
Predictor b b_95%_CI beta beta_95%_CI sr2
(Intercept) 41.12** [22.72, 59.53]
adverts 0.09** [0.07, 0.10] 0.52 [0.44, 0.61] .27
airplay 3.59** [3.02, 4.15] 0.55 [0.46, 0.63] .29
(Intercept) 28.30* [1.09, 55.50]
adverts 0.11** [0.07, 0.16] 0.69 [0.42, 0.96] .05
airplay 4.02** [3.14, 4.91] 0.61 [0.48, 0.75] .15
I(adverts * airplay) -0.00 [-0.00, 0.00] -0.19 [-0.49, 0.11] .00
sr2_95%_CI r Fit Difference
[.18, .36] .58**
[.20, .38] .60**
R2 = .629**
95% CI[.55,.69]
[.01, .08] .58**
[.08, .22] .60**
[-.01, .01]
R2 = .632** Delta R2 = .003
95% CI[.55,.69] 95% CI[-.01, .01]
Note. A significant b-weight indicates the beta-weight and semi-partial correlation are also significant.
b represents unstandardized regression weights. beta indicates the standardized regression weights.
sr2 represents the semi-partial correlation squared. r represents the zero-order correlation.
Square brackets are used to enclose the lower and upper limits of a confidence interval.
* indicates p < .05. ** indicates p < .01.
Sličan postupak, možemo izvesti s paketom modelsummary (Arel-Bundock, 2022). U slijedećih nekoliko linija koda, preuzetih sa službenih stranica paketa modelsummary, možemo vidjeti jednostavnu primjenu usporedbe tri regresijska modela koji se razlikuju s obzirom na broj varijabli koje se nalaze u svakom modelu. Dobivena tablica je spremna za publikaciju sa svim potrebnim indeksima. Ovaj primjer, povlači podatke s mreže (url adresa) i pridjeljuje određenom objektu te u narednom koraku se radi usporedba tri modela.
library(modelsummary)Warning: package 'modelsummary' was built under R version 4.4.1`modelsummary` 2.0.0 now uses `tinytable` as its default table-drawing
backend. Learn more at: https://vincentarelbundock.github.io/tinytable/
Revert to `kableExtra` for one session:
options(modelsummary_factory_default = 'kableExtra')
options(modelsummary_factory_latex = 'kableExtra')
options(modelsummary_factory_html = 'kableExtra')
Silence this message forever:
config_modelsummary(startup_message = FALSE)
Attaching package: 'modelsummary'The following object is masked from 'package:psych':
SD# učitavanje podataka
url <- 'https://vincentarelbundock.github.io/Rdatasets/csv/palmerpenguins/penguins.csv'
dat <- read.csv(url)
# rekodiranje varijable, pretravanje jedinica iz mm u cm
dat$bill_length_cm <- dat$bill_length_mm / 10
dat$flipper_length_cm <- dat$flipper_length_mm / 10
# usporedba modela
models <- list(
"Small model" = lm(bill_length_cm ~ flipper_length_cm, data = dat),
"Medium model" = lm(bill_length_cm ~ flipper_length_cm + body_mass_g, data = dat),
"Large model" = lm(bill_length_cm ~ flipper_length_cm + body_mass_g + species, data = dat))
modelsummary(models, statistic = 'conf.int')| Small model | Medium model | Large model | |
|---|---|---|---|
| (Intercept) | -0.726 | -0.344 | 0.984 |
| [-1.356, -0.097] | [-1.245, 0.557] | [0.215, 1.752] | |
| flipper_length_cm | 0.255 | 0.222 | 0.095 |
| [0.224, 0.286] | [0.158, 0.285] | [0.048, 0.142] | |
| body_mass_g | 0.000 | 0.000 | |
| [0.000, 0.000] | [0.000, 0.000] | ||
| speciesChinstrap | 0.939 | ||
| [0.867, 1.011] | |||
| speciesGentoo | 0.207 | ||
| [0.088, 0.326] | |||
| Num.Obs. | 342 | 342 | 342 |
| R2 | 0.431 | 0.433 | 0.817 |
| R2 Adj. | 0.429 | 0.430 | 0.815 |
| AIC | 369.0 | 369.6 | -12.6 |
| BIC | 380.5 | 385.0 | 10.4 |
| Log.Lik. | -181.499 | -180.813 | 12.313 |
| F | 257.092 | 129.365 | 375.333 |
| RMSE | 0.41 | 0.41 | 0.23 |
Osim navedenih mogućnosti prilagođavanja izgleda izvještaja regresijske analize, vrlo je praktičan način pomoću paketa gtsummary (Sjoberg et al., 2021). U slijedećem primjeru, prikazati ćemo preporučeni način iz dokumentacije dostupne u paketu. Poslužit ćemo se primjerom logističke regresijske analize u kojoj se predviđa tumorska razina pomoću dvije varijable, godine i stupanj.
library(gtsummary)
Attaching package: 'gtsummary'The following object is masked from 'package:MASS':
selectlr_tumor <- glm(response ~ age + stage, trial, family = binomial)
tbl_regression(lr_tumor, exponentiate = TRUE)| Characteristic | OR1 | 95% CI1 | p-value |
|---|---|---|---|
| Age | 1.02 | 1.00, 1.04 | 0.091 |
| T Stage | |||
| T1 | — | — | |
| T2 | 0.58 | 0.24, 1.37 | 0.2 |
| T3 | 0.94 | 0.39, 2.28 | 0.9 |
| T4 | 0.79 | 0.33, 1.90 | 0.6 |
| 1 OR = Odds Ratio, CI = Confidence Interval | |||
Na ovaj način, dobijemo jako lijepu tablicu spremnu za publikaciju poput znanstvenog članka.
6.9.0.1 Zadatci: Regresijska analiza
- Otvorite skup podataka longley (paket datasets bi već trebao biti instaliran u R-u, opis paketa dostupan na: https://stat.ethz.ch/R-manual/R-devel/library/datasets/html/longley.html).
Odredite koja od varijabli u skupu najbolje predviđa varijablu Employed, na način da ćete prvo unositi jednu po jednu varijablu samostalno u model, a na kraju sve zajedno. Odredite optimalan model i interpretirajte rezultate.
U skupu podataka BostonHousing2 (opis skupa podataka: https://www.rdocumentation.org/packages/mlbench/versions/2.1-3/topics/BostonHousing) odredite optimalan model koji će predviđati cijenu kuće (varijabla cmedv).
U carData paketu odaberite bilo koji skup podataka i na njemu provedite regresijsku analizu. Interpretirajte podatke.
any of several statistical techniques that are used to describe, explain, or predict (or all three) the variance of an outcome or dependent variable using scores on one or more predictor or independent variables. Regression analysis is a subset of the general linear model. It yields a regression equation as well as an index of the relationship between the dependent and independent variables.↩︎