Kvantitativna analiza teksta u R sučelju predstavlja automatiziran pristup procesiranja najčešće velikih količina podataka, koje se zatim mogu analizirati korištenjem statističkih procedura. Često je cilj kvanitificirati obilježja teksta, koje bi se zatim mogle analizirati korištenjem klasičnih statističkih postupaka. Sam tekst ima različita obilježja, koja mogu biti osnovna (broj riječi u tekstu, duljina riječi), do relativno složenijih analiza (emocionalne karakteristike teksta, razina čitljivosti). U ovom dijelu ćemo se usredotočiti na pripremanje i formatiranje (engl. pre processing) teksta koji želimo analizirati, neke osnovne opisne analize teksta te konačno analizu sentimenta i čitljivosti teksta.
12.1 Priprema podataka za analizu (čišćenje podataka)
Prvi korak u svakoj analizi teksta je priprema podataka za analizu, te taj dio zauzima relativno veći dio vremena u radu s tekstualnim podacima.
Niže se nalazi primjer teksta, a cilj je dati uvid čitatelju koji je rezultat nekih osnovnih naredbi u R-u vezanih za analizu teksta. Čišćenje većih količina teksta se u principu ne razlikuje u odnosu na manje količine teksta, osim što za čišćenje većih količina teksta treba veća količina vremena.
Primjer_teksta<-"Garfield loves lasagna. He found three pieces. He gave Odie one, 2nd to John, and the last he keeps for himself."print(Primjer_teksta)
[1] "Garfield loves lasagna.\n He found three pieces.\n He gave Odie one,\n 2nd to John,\n and the last he keeps for himself."
Naša varijabla je tekstualna varijabla. Ovdje je važno naglasiti da su dijelovi teksta odvojeni u nove redove, te da između sebe imaju različite veznike i slično. Ali ovaj tekst sadrži velika i mala slova, brojeve, veznike i interpunkciju, što sve predstavlja problem u analizi podataka. Prvi korak je očistiti tekst, s ciljem prikaza naredbi koje omogućuju uređivanje teksta. Za početak možemo otvoriti pakete tm, tidytext i tibble, koji sadrže naredbe koje olakšavaju proces čišćenja tekstualnih podataka.
[1] "Garfield loves lasagna\n He found three pieces\n He gave Odie one\n 2nd to John\n and the last he keeps for himself"
Možete primjetiti kako je interpunkcija nestala, nema više zareza, točaka, dvotočki.
Sljedeći problem u analizi teksta su brojevi, te zbog toga moramo maknuti sve brojeve koji se nalaze u tekstu. Pritom treba naglasiti da R prepoznaje brojeve u numeričkom obliku (1,2,3), dok tekstualno napisane brojeve (one, two, three) tretira kao tekst.
[1] "Garfield loves lasagna\n He found three pieces\n He gave Odie one\n nd to John\n and the last he keeps for himself"
Stoga je ova naredba maknula samo brojeve napisane brojkama, dok su brojevi napisani riječima ostali. Ostao je čak i nastavak za redne brojeve na engleskom “nd”. Taj nastavak predstavlja jedan oblik teksta za koji ne želimo da uđe u analizu, jer nema smisleno značenje. Osim toga, u analizi nam smetaju i veznici te neke česte riječi koje se pojavljuju u tekstu, a koje nemaju (emocionalnu) valenciju, te ne doprinose analizi. Zovemo ih “stopwords”, a njihov popis se može pronaći korištenjem sljedeće naredbe:
Sada ćemo iz našeg teksta maknuti stopwords, za koje ste mogli vidjeti da predstavljaju uglavnom zamjenice, priloge i veznike. Ali, ukoliko znamo da u tekstu postoje još neke riječi koje želimo očistiti, jer ne predstavljaju vrstu teksta koju bismo željeli analizirati, možemo i te riječi dodati u naredbu.U trenutnom slučaju, želimo maknuti i ostatak “nd”, jer ta riječ zapravo ništa ne znači u analizi, te ćemo taj nastavak dodati u naredbu.
[1] "Garfield loves lasagna\n He found three pieces\n He gave Odie one\n John\n last keeps "
U nekim (rijetkim) slučajevima, velika i mala slova mogu poslužiti za razlikovanje različitih riječi (najčešće vlastitih imena i općih imenica). Međutim, u uobičajenom postupku, prilikom čišćenja mičemo sva velika slova u tekstu korištenjem naredbe tolower.
[1] "garfield loves lasagna he found three pieces he gave odie one john last keeps "
Ovaj posljednji primjer prikazuje vrstu teksta koja je “očišćena”, i koja je spremna za analizu.
12.2 Rad s ugrađenim skupovima tekstualnih podataka
Jednako kao što smo analizirali manji dio teksta, tako radimo i s većim količinama teksta.
Za drugi primjer možemo uzeti tekst “alice” u paketu languageR koji sadrži priču Lewisa Carrola Alice u zemlji čudesa, a radi se o nizu odvojenih riječi u redovima, koje zajedno tvore navedenu priču. Sada ćemo čišćenje teksta primijeniti na taj skup podataka. Na kraju ćemo usporediti prvih 50 redova (riječi) priče prije i poslije čišćenja podataka.
Kada se promatra prvih 50 redova u skupu podataka, može primijetiti kako je nakon čišćenja ostao značajno manji broj riječi koje će se analizirati.
12.3 Određivanje čestine riječi u tekstu
Određivanje čestine riječi u tekstu predstavlja jednu od osnovnih radnji u kvantitativnoj analizi teksta. Razlozi za provjeru čestine riječi mogu biti različiti, od jednostavne opisne analize ili testiranja unaprijed postavljene hipoteze o tekstu. Prvi korak je očistiti tekst prema prikazanom obrascu, te zatim napraviti tablicu koja sadrži popis riječi u tekstu i njihovu frekvenciju, odnosno čestinu pojavljivanja. U primjeru koristimo “očišćeni” tekst “alice” iz languageR paketa. Prvi korak je pretvoriti skup podataka u varijablu u R-u, zatim se određuje distribucija čestine pojavljivanja riječi u tekstu (kao što bismo radili s bilo kojom kategorijskom varijablom). Konačno, korištenjem naredbe sort, možemo poredati varijable prema čestini pojavljivanja. U rezultatima se može vidjeti kako je najčešće korištena riječ “alice”, ali i kako u verziji teksta koja je očišćena postoje vrste riječi koje bismo mogli maknuti: “ll”, “ve”. Zato je važno nakon čišćenja teksta pregledati posljednju verziju distribucije čestine riječi, kako bi se korisnik uvjerio da je tekst spreman za analizu.
Nekad, za potrebe atraktivnog prikazivanja distribucija čestine riječi u tekstu, ili s ciljem naglašavanja određenih podataka tijekom prezentacije, prikladno je koristiti “oblake riječi” (engl. wordclouds). Oblake riječi je moguće napraviti u R-u, i to na više načina. R paketi wordcloud i wordcloud2 su zanimljivi načini vizualnog prikaza čestine riječi u tekstu. Wordcloud2 predstavlja interaktivniji prikaz ranije inačice. Nakon što smo napravili graf, u trenutnoj matrici pod nazivom imamo oko 18 tisuća praznih vrijednosti, preporuka je uvijek ih se riješiti prilikom oblikovanja matrice.
Ovakva vrsta analize teksta je opisna, koristi se u rijetkim slučajevima i najčešće zahtijeva velike količine teksta da bi imala smisla. Novija primjena tekstualne analize je korištenje statističkih postupaka u opisima i usporedbi jezičnih karakteristika teksta. Novije analize teksta uključuju analizu čitljivosti i analizu sentimenta.
12.5 Analiza čitljivosti i emocionalnih karakteristika teksta
Za demonstraciju analize čitljivosti nije dovoljno da imamo jednu riječ po redu u matrici. Potrebne su nam veće količine tekstova, kako bismo mogli izračunati potrebnu razinu čitljivosti i emocionalne karakteristike teksta, koje se ne mogu izračunati iz samo jedne riječi. Korištenjem paketa hcandersenr možemo analizirati 156 priča koje je napisao Hans Christian Andersen. Ta baza podataka će nam pomoći da pogledamo kako možemo analizirati prethodno navedene parametre i pripremiti tekst za statističku analizu. U ovom slučaju je važno naglasiti da je naš broj ispitanika (redova, n) zapravo broj analiziranih tekstova.
require(hcandersenr)
Kako možemo vidjeti iz paketa, tekst se prelama iz reda u red, te nema ujednačenog obrasca prema kojem bi se mogao spojiti, primjerice da kraj priče označava dvotočka ili neki izraz. Srećom, uz svaki redak teksta je navedeno o kojoj se priči radi, pa možemo tekst grupirati prema tom kriteriju. Ukoliko to ne bismo imali, bilo bi iznimno teško automatski spojiti priče jer, nažalost, ni analiza teksta korištenjem programa nije svemoguća. Ukoliko imate sreće, ili možete utjecati na slaganje tekstova u matricu, preporuka je uvijek koristiti ujednačen način odvajanja skupova podataka (u najboljem slučaju neki specijalni znak ili skup brojeva).
# A tibble: 6 × 2
book text
<chr> <chr>
1 "\"Beautiful\"" "Alfred the sculptor - yes, you know him, d…
2 "\"Dance, dance, doll of mine!\"" "\"Yes, this is a song for very small child…
3 "\"Something\"" "\"I mean to be somebody, and do something …
4 "A cheerful temper" "From my father I received the best inherit…
5 "A leaf from heaven" "High up in the thin, clear air there flew …
6 "A picture from the ramparts" "It is autumn. We stand on the ramparts, an…
Sada imamo tablicu sa 156 priča, a varijable u bazi podataka su Book (ime knjige) i text (tekst knjige). Sada ćemo analizirati sentiment Andersenovih priča. Prijašnje vrste analize teksta si uglavnom opisne, te se sve temeljli na čestini riječi. Ipak, u pravoj kvantitativnoj analizi teksta najčešće želimo analizirati kakva su obilježja nekog teksta. Najčešći pristup u analizi obilježja teksta se odnosi na analizu sentimenta ili emocionalnih obilježja teksta. Taj pristup omogućuje da korištenjem R paketa analiziramo je li neki test sadržava riječi koje su povezane s pozitivnim ili negativnim emocijama (ili nekim drugim psihološkim kontruktom), te izračunom tih koeficijenata omogućava usporedbu. Neki od najpoznatijih paketa u ovom dijelu su sentimentr, SentimentAnalysis i syuzhet. Primjerice, korištenjem tih paketa (i pomoću paketa ggplot2) možemo napraviti slikovni prikaz emocionalnih karakteristika na cijelom skupu tekstova.
require(sentimentr)require(SentimentAnalysis)require(syuzhet)sent <-analyzeSentiment(data_aggregated$text, language ="english")sent2<-get_nrc_sentiment(data_aggregated$text)head(sent2)
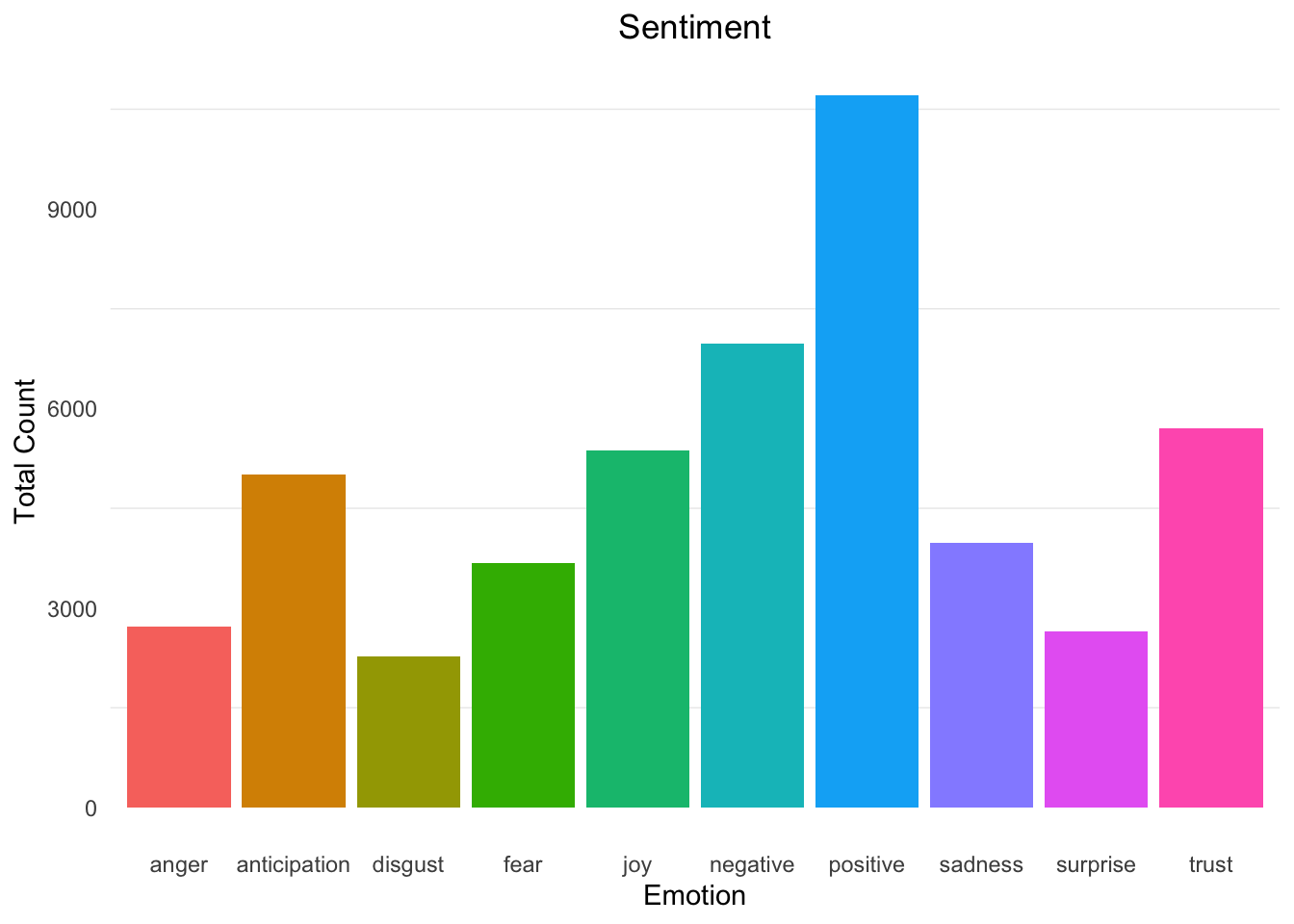
sent3 <-as.data.frame(colSums(sent2))sent3 <-tibble::rownames_to_column(sent3)colnames(sent3) <-c("emotion", "count")require(ggplot2)ggplot(sent3, aes(x = emotion, y = count, fill = emotion)) +geom_bar(stat ="identity") +theme_minimal() +theme(legend.position="none", panel.grid.major =element_blank()) +labs( x ="Emotion", y ="Total Count") +ggtitle("Sentiment") +theme(plot.title =element_text(hjust=0.5))
Rezultat na slikovnom prikazu je broj riječi povezan s određenom emocijom ili psihološkim konstruktom.
Sljedeći aspekt analize teksta je analiza čitljivosti, odnosno procjena lakoće čitanja određenog teksta. Za to je preporuka koristiti pakete quanteda i quanteda.textstats, koji sadrže više od stotinu različitih koeficijenata za procjenu čitljivosti. Svaki od koeficijenata čitljivosti ima svoju interpretaciju, a sama interpretacija se može pronaći u opisu paketa. Za naš trenutni primjer koristiti ćemo SMOG formulu koja označava koliko godina obrazovanja osoba mora imati da bi s lakoćom pročitala opisani tekst.
Min. 1st Qu. Median Mean 3rd Qu. Max.
6.105 7.404 7.929 8.120 8.750 10.773
Dakle, medijan broja godina obrazovanja za čitanje Andersenovih priča je oko osam godina (IQR 7-9), što se može interpretirati da bi osoba trebala imati barem završenu osnovnu školu da bi mogla s lakoćom pročitati Andersenove priče.
12.6 Priprema podataka za statističku analizu
Ukoliko želimo raditi statističku analizu s podatcima, onda možemo napraviti i analizu sentimenta koja će pripremiti podatke za unos u matricu.
sentxy <-analyzeSentiment(data_aggregated$text, language ="english", removeStopwords =FALSE, stemming =FALSE)head(sentxy)