Vizualizacija podataka podrazumijeva grafički prikaz podataka s ciljem boljeg razumijevanja strukture i sadržaja podataka ili rezultata proizašlih iz analize. Dobra vizualizacija podataka ili rezultata istraživanja uspješnije će prenijeti poruku krajnjem korisniku: učeniku, studentu, klijentu, znanstvenoj zajednici… Razumijevanje mehanizama vizualizacije podataka znatno će pomoći u boljem shvaćanju tuđih vizualizacija podataka i identificiranju ključnih obilježja tih podataka kao i eventualnih nedostataka ili pogrešaka. Krajnji cilj vizualizacije podataka je komunikacija i prezentiranje. Dobra vizualizacija podataka šalje jasnu poruku i podiže kvalitetu cjelokupne analize, a loša vizualizacija degradira cjelokupni dojam nekog rada.
Nažalost, vizualizacije se često koriste pogrešno. Ponekad je to slučajno, iz nerazumijevanja odnosa među podacima ili slabostima određenih elemenata i vrsta grafikona , ali često je to i namjerno, kako bi autor naglasio svoju ideju odnosno poruku koju šalje tom vizualizacijom. Brojna istraživanja u psihologiji bave se percepijom vizualizacija podataka i utjecajem određenih vizualnih pojava na naše razumijevanje onoga što se prikazuje. Za detaljnije o percepciji pogledati izvrsnu knjigu o vizualizaciji podataka Healy (2019) . Ovdje nećemo ulaziti u detalje kako mi percipiramo razne vizualne elemente, boje i slično jer to prelazi okvire ove knjige, ali ćemo opisati neka temeljna pravila pri kreiranju kvalitetne vizualizacije podataka. Dobra vizualizacija podataka mora vjerno odražavati podatke i njihova obilježja obzirom da vizualizacija značajno usmjerava korisnika. Vizualizaciju često koristimo kako bi sami sebe uvjerili u ispravnost naše ideje jer pažljivim odabirom podataka, njihovim podskupom i vrstom vizualizacije možemo stvoriti priču potpuno drugačijom od one koja zaista postoji u podacima. Zato ćemo se u ovom poglavlju fokusirati na “ispravno” prikazivanje podataka, a poseban naglasak na to stavit stavljamo pri odabiru boja, oblika, osi i mjerila.
U ovom poglavlju obrađujemo mehanizme vizualizacije podataka i na primjerima obrađujemo najčešće korištene tipove vizualizacije podataka u obrazovanju i znanosti.
Osnovni R sadrži funkcije za vizualizaciju podataka, u prvom redu funkciju plot(). Osim osnovnih R funkcija, možemo koristiti funkcije iz brojnih etabliranih paketa poput ggplot2 ili tmap. U ovom dijelu knjige najveću pažnju posvetit ćemo ggplot2 paketu jer on slijedi osnovni tidyverse ideju kodiranja u R okruženju te je najpoznatiji i najviše korišteni paket za vizualizaciju podataka u R. Zbog svoje popularnosti, dostupna je iznimno bogata literatura na temu vizualizacije podataka putem ggplot2 paketa.
ggplot2 paket je dio tidyverse paketa te pozivanjem library(tidyverse) na početku R skripte pozivamo ujedno i ggplot2 paket. Ideja ggplot2 paketa je kreiranje vizualizacija kroz slojeve (layers). Sama vizualizacija prikazuje se u okviru Plots. Paket ggplot2 temelji se na funkciji ggplot().
Započinjemo ulazak u ggplot2 svijet vizualizacije sa ugrađenim skupom podataka mtcars koji sadrži podatke o 32 automobila.
Uvijek prvo pogledajmo strukturu i sadržaj skupa podataka koji želimo analizirati. Što predstavljaju varijable, tip varijabli, broj opažanja i ostalo.
Primjetimo koji su sve paketi uključeni u tidyverse. Za samu vizualizaciju podataka ključan nam je paket ggplot2 kojeg bi pozvali sa library(ggplot2), ali za transformaciju podataka koristit će se i druge naredbe koje su sastavni dio ostalih tidyverse paketa.
# proučimo strukturu i sadržaj skupa podataka mtcarshead(mtcars)
# ako je potrebno, pogledajmo i detaljnije o skupu podataka?mtcars
Kreirajmo grafikon kojim ćemo vizualizirati korelaciju između dvije varijable, hp i mpg.
hp prikazuje snagu automobila u konjskim snagama
mpg prikazuje potrošnju automobila u američkoj mjernoj jedinici mpg odnosno miljama po galonu. Ova mjerna jedinica je obrnuto proporcionalna mjernoj jedinici koju koristimo u Hrvatskoj (potrošnja u litrama na 100 prijeđenih kilometara). Dakle, niža vrijednost mpg varijable znači višu potrošnju goriva!
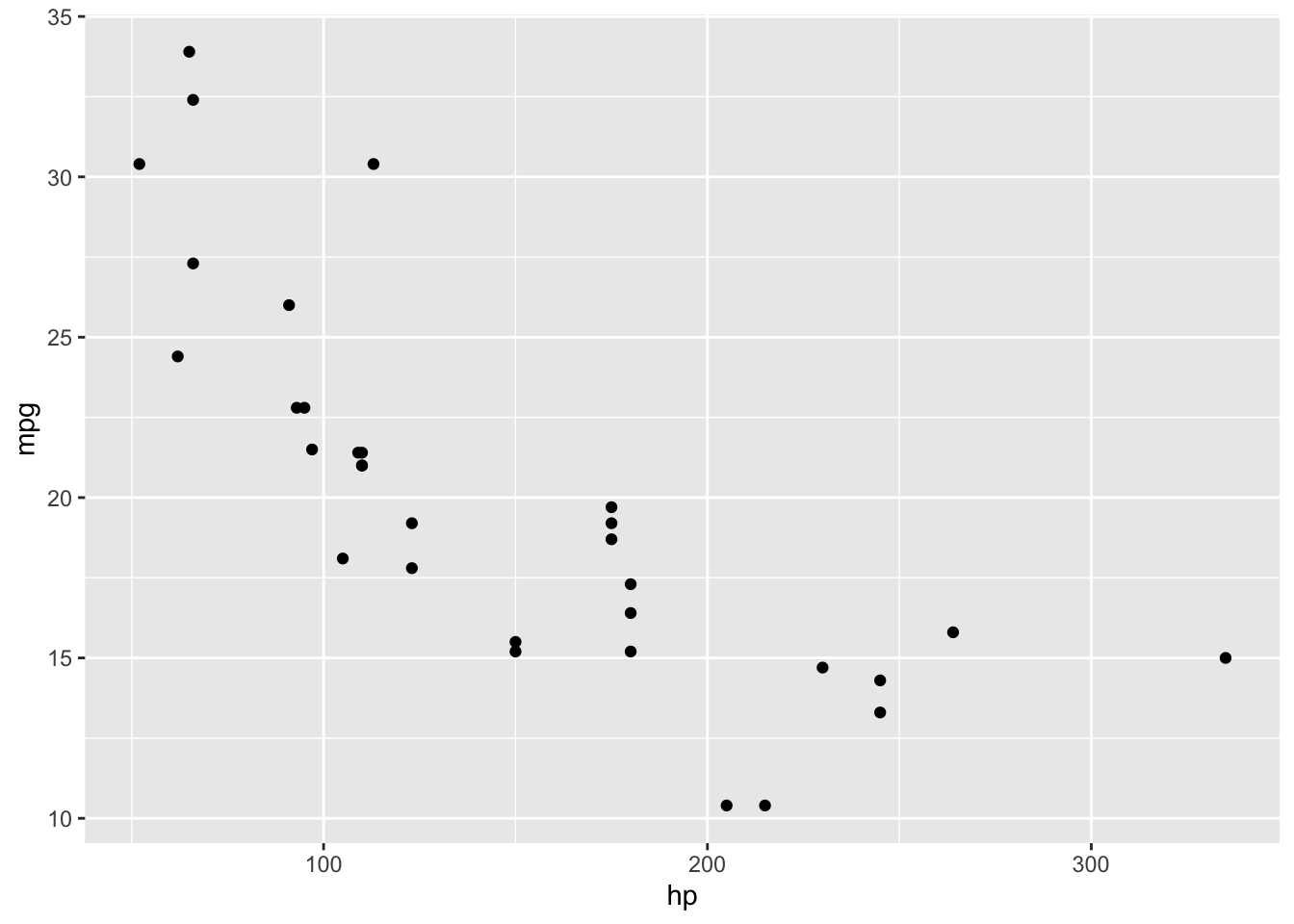
# kreirajmo grafikonggplot(data = mtcars)+geom_point(mapping =aes(x = hp , y = mpg))
Ovime smo kreirali točkasti grafikon u kojem svaka točka prikazuje jedan automobil odnosno odnos njegove snage (varijabla hp prikazana na x osi) i potrošnje (varijabla mpg prikazana na y osi). Grafikon nam pokazuje relativno snažnu negativnu korelaciju1 između snage automobila i potrošnje goriva izražene u miljama po galonu.
Struktura svake ggplot() funkcije sadrži skup na kojeg se odnosi, te slojeve vizualizacija koje moraju sadržavati aes() funkciju unutar koje navodimo varijable na x i y osi. U ovom slučaju to je bio točkasti grafikon izražen funkcijom geom_point() odnosno dijagram rasipanja.
Pojednostavnimo: unutar ggplot funkcije zadajemo skup podataka sa data=, a unutar pojedinih geometrijskih slojeva vizualizacije (koje uvijek počinju sa geom_) zadajemo što se nalazi na x i y osi sa mapping = aes(x = , y =).
Kao i u ostalim funkcijama u R okruženju ne moramo pisati pune nazive argumenata ako znamo redoslijed kojim se pojavljuju u funkciji i ako znamo koji su nužni argumenti za pokretanje te funkcije. Stoga u nastavku ovog poglavlja nećemo više pisati pune nazive argumenata data = i mapping =.
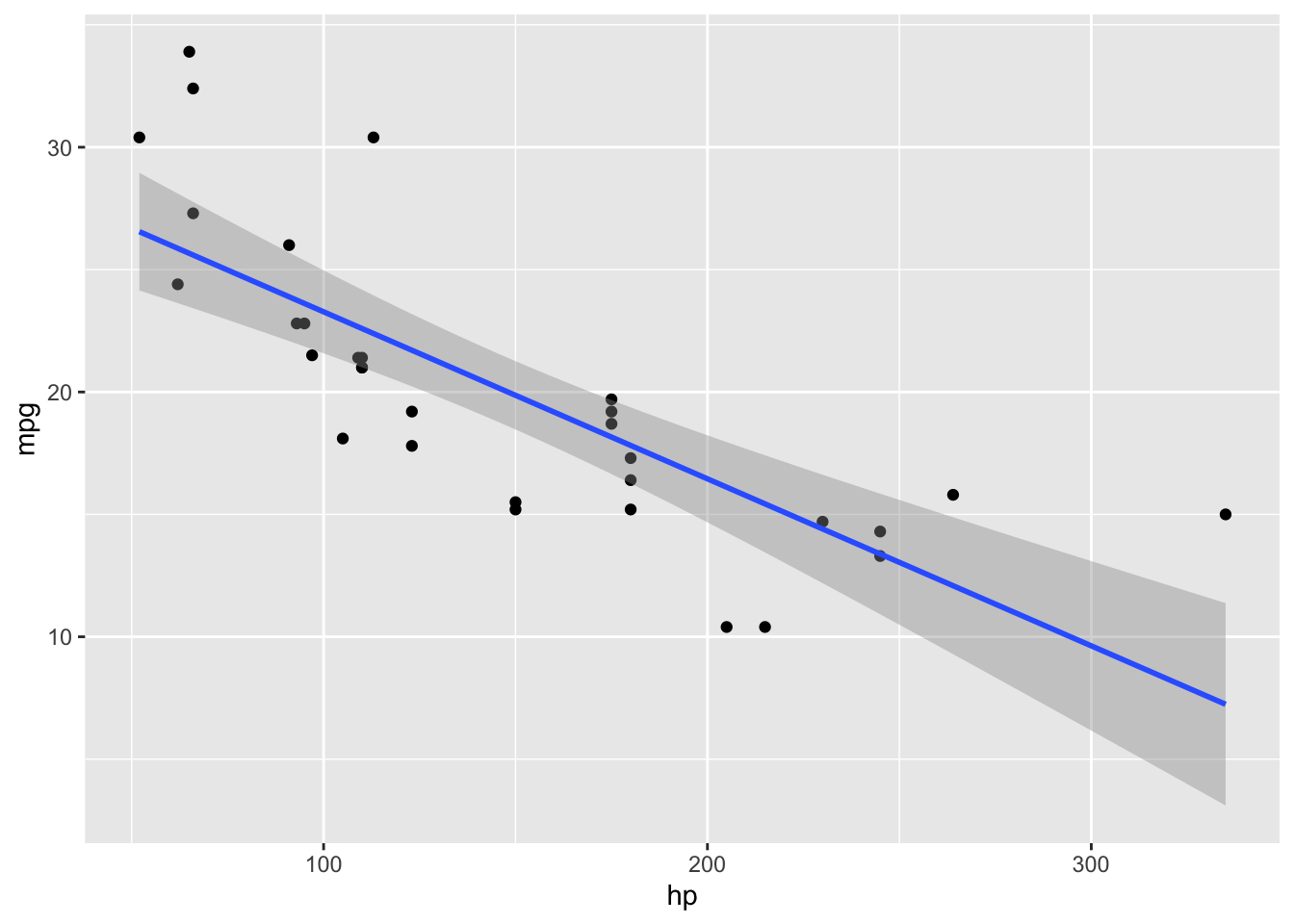
Uočimo da je tip vizualizacije odnosno sloja kojeg želimo dodati u ggplot() funkciji odvojen znakom +, a ne %>% operatorom. Kada govorimo o slojevima, to znači da možemo dodati još različitih geometrijskih funkcija na našu vizualizaciju. Dodajmo na postojeći grafikon liniju trenda odnosno regresijski pravac koristeći funkciju geom_smooth(method = "lm").
# kreirajmo isti grafikon, ali s regresijskim pravcem. # Zašto ovaj kod ne radi?ggplot(mtcars)+geom_point(aes(x=hp , y=mpg))+geom_smooth(method ="lm")
Dobili smo pogrešku Error: stat_smooth requires the following missing aesthetics: x and y!. Sloj geom_smooth() ne zna što mu je na x, a što na y osi! Ne zna jer smo to zadali samo za sloj geom_point() te mu moramo to eksplicitno zadati. Možemo to napraviti na sljedeće načine (oba koda daju isti grafikon):
# točan, ali nepotrebno duži i stoga nekonvencionalan način:ggplot(mtcars)+geom_point(aes(x = hp , y = mpg))+geom_smooth(aes(x = hp , y = mpg), method ="lm")# točan, kraći i konvencionalan način:ggplot(mtcars, aes(x = hp, y = mpg))+geom_point()+geom_smooth(method ="lm")
`geom_smooth()` using formula = 'y ~ x'
Ako iste varijable, odnosno kombinacije x i y osi, vrijede za sve slojeve, možemo aes(x = , y =) zapisati unutar ggplot() funkcije! Tada nam svi slojevi geom_ “znaju” što koriste za x, a što za y os grafikona.
Na posljednjem grafikonu, sivom bojom oko pravca označena je standardna pogreška. Ako želimo pravac bez osjenčane standardne pogreške, samo u geom_smooth() funkciji dodajmo argument se=F.
Prebacimo se na još jedan ugrađeni skup podataka o automobilima, skup mpg.
# proučimo sadržaj i strukturu skupa mpghead(mpg)
# A tibble: 6 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa…
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa…
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa…
4 audi a4 2 2008 4 auto(av) f 21 30 p compa…
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa…
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa…
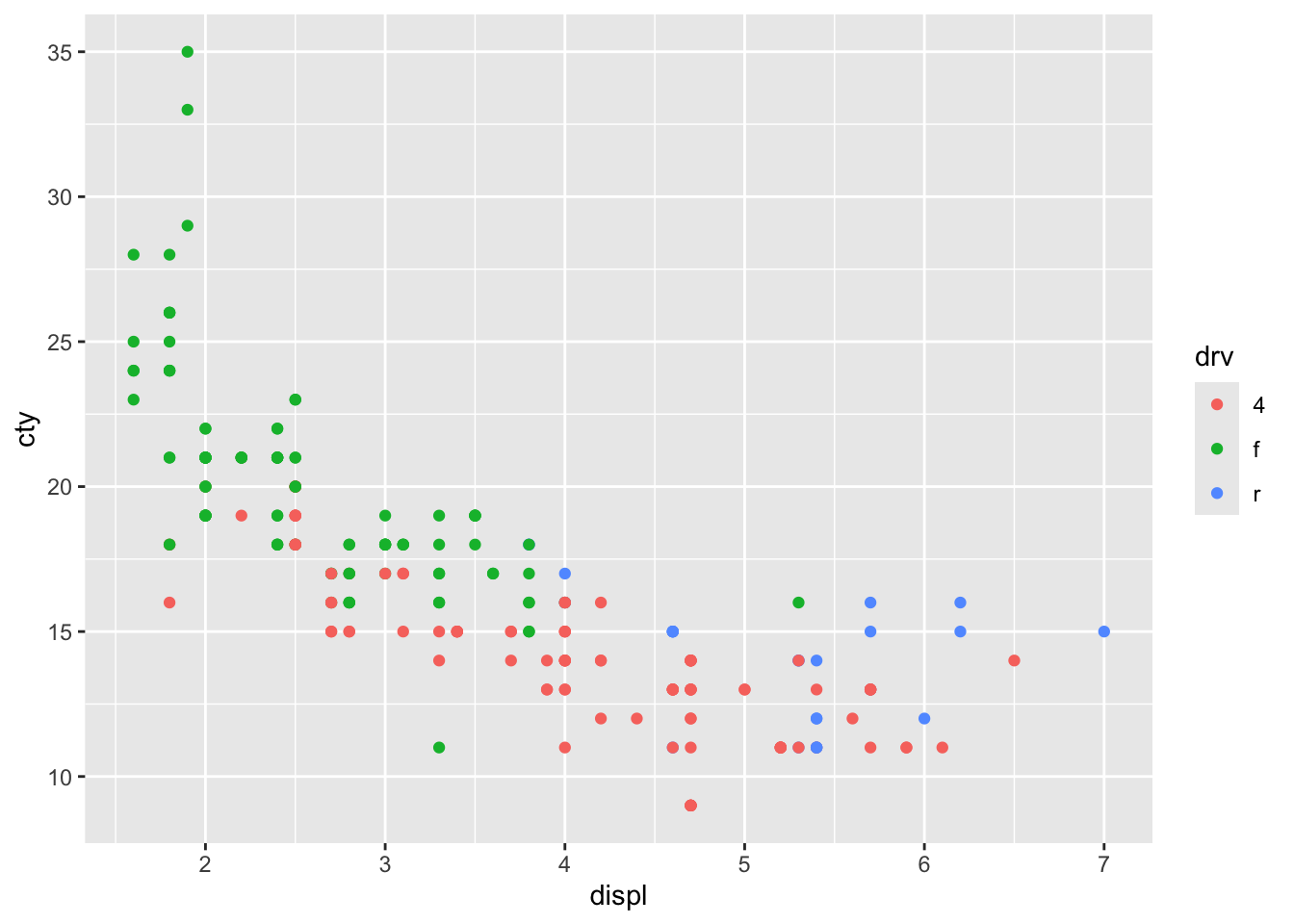
Vizualizirajmo korelaciju između varijabli obujam motora (displ) i potrošnja u gradu (cty). Dodatno, učinimo naš grafikon informativnijim i dodajmo mu još jednu varijablu - pogonski kotači (drv). * displ - obujam motora u litrama * cty - potrošnja goriva u gradskoj vožnji izražena u mjernoj jedinici milja po galonu * drv - pogonski kotači s modalitetima pogon na sva četiri kotača (4), prednje kotače (f) i stražnje kotače (r)
ggplot(mpg, aes(displ, cty, color = drv))+geom_point()
Novi argument unutar aes() funkcije je color = drv s kojim smo obojali naše točke odnosno automobile ovisno o pogonskim kotačima (sva četiri, prednji, stražnji pogon). ggplot je sam stvorio legendu s modalitetima varijable drv.
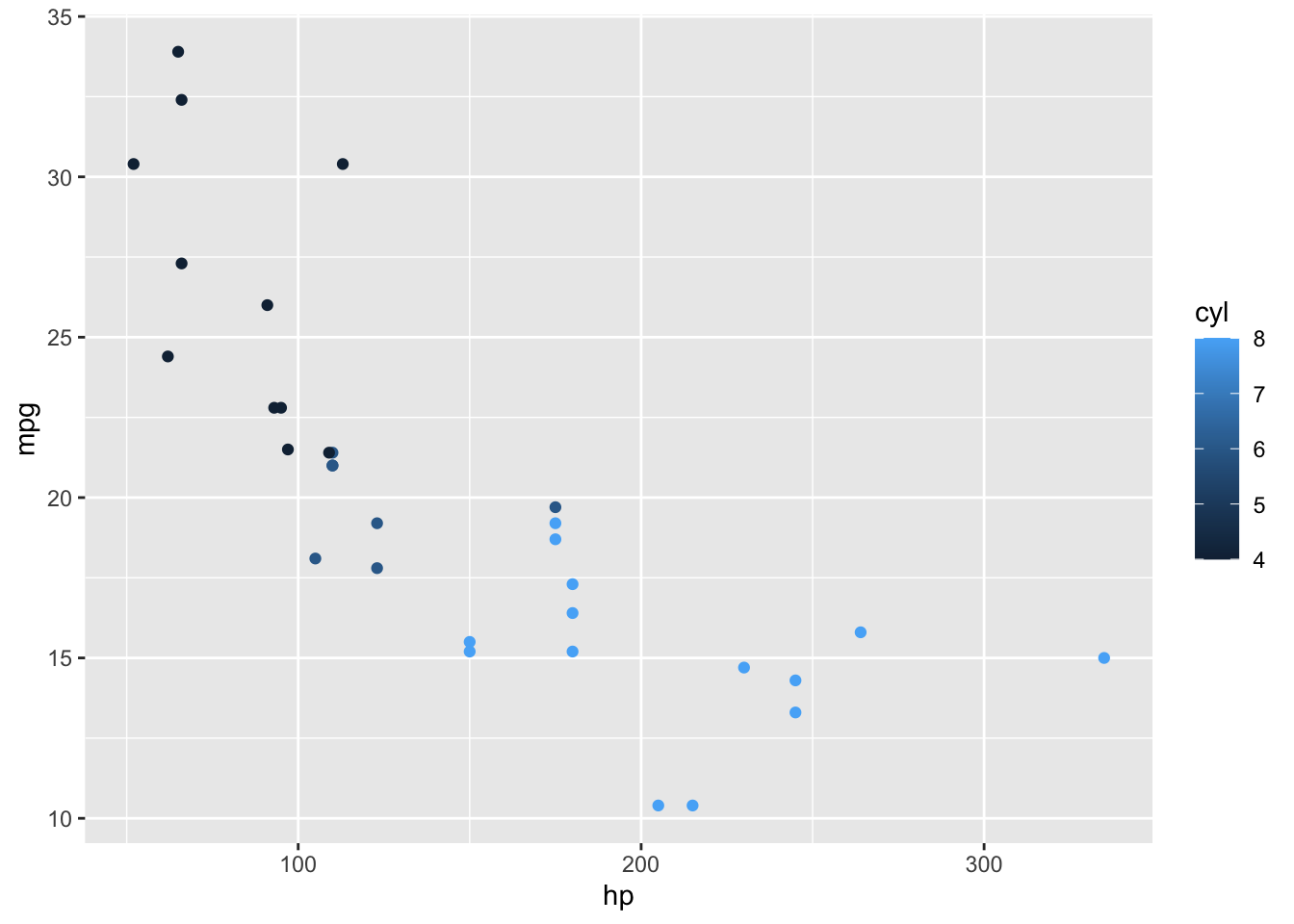
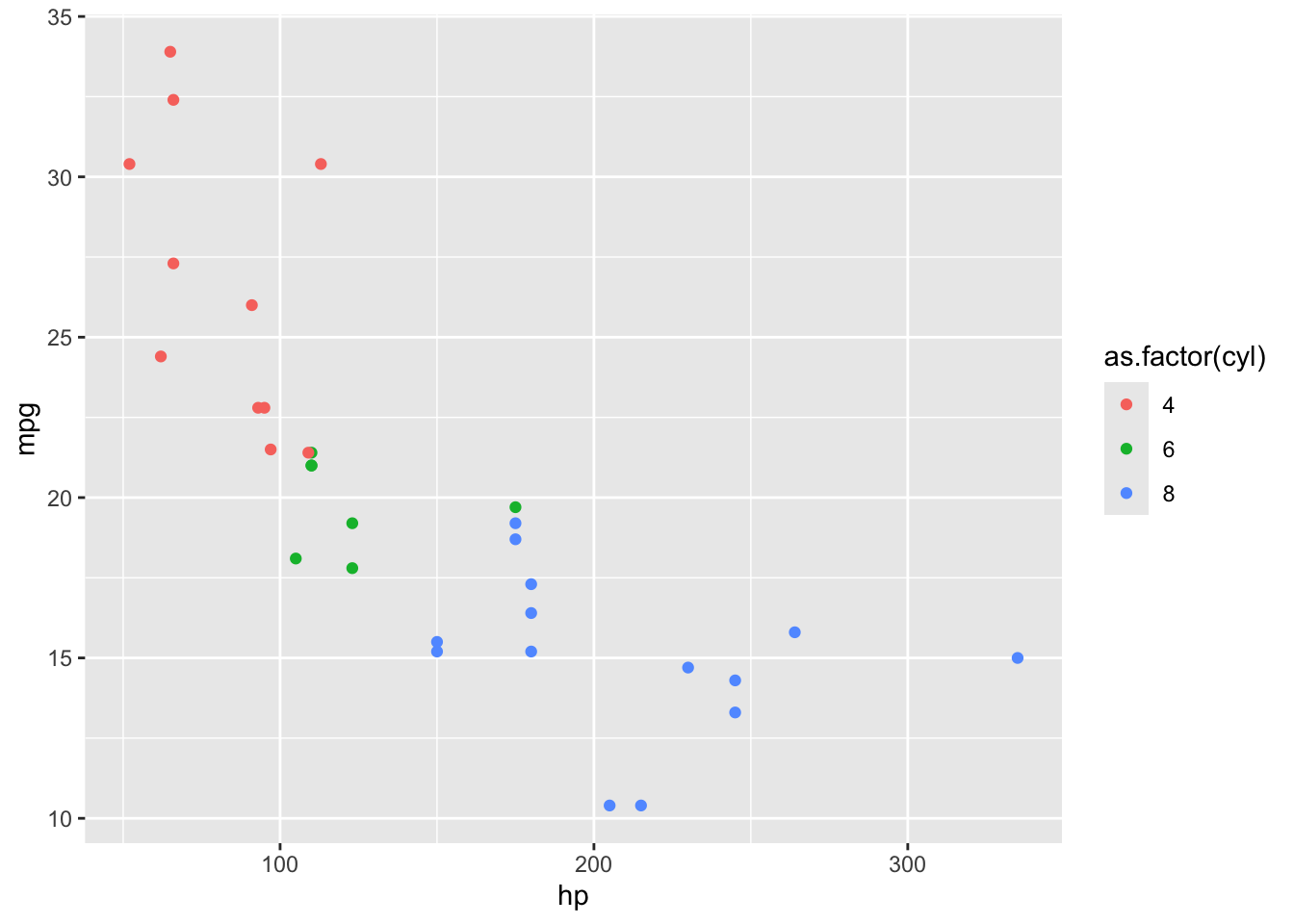
Ponovno se vratimo na skup podataka mtcars i korelaciju snage i potrošnje te točke obojajmo ovisno o broju cilindara automobila odnosno varijable cyl.
# koja je manjkavost ovakvog prikaza varijable cyl?ggplot(mtcars, aes(x = hp, y = mpg, color = cyl))+geom_point()
Zašto se prikaz varijable cyl ovdje razlikuje od onoga u skupu mpg na prethodnom grafikonu u kojem smo obojali točke ovisno o varijabli drv? Varijabla cyl je u skupu mtcars numeričkog tipa! ggplot() numeričke varijable prikazuje drugačije od kategorijalnih (factor) ili znakovnih (character). Numeričke varijable ggplot() prikazuje kroz kontinuiranu nijansu (jedne) boje jer pretpostavlja numeričke varijable kao kontinuirane, a ne diskretne kao što su kategorijalne ili znakovne. Važno je voditi računa o tipu varijable kada koristimo ggplot().
Čim pretvorimo varijablu cyl u kategorijalnu varijablu (factor) imat ćemo prikaz istovjetan onome u skupu podataka mpg. Za promjenu tipa varijable u kategorijalnu, koristit ćemo funkciju as.factor().
ggplot(mtcars, aes(x = hp, y = mpg, color =as.factor(cyl)))+geom_point()
8.2 Vrste grafikona i elementi vizualizacije
Do sada smo mogli vidjeti da vrstu grafikona u ggplot() odabiremo s geom_ funkcijom. Elementarne vrste grafikona i geom_ funkcije su: * stupčasti - geom_bar() i geom_col() * histogram - geom_histogram() * box-plot - geom_boxplot() * dijagram rasipanja - geom_point() i geom_jitter() * linijski - geom_line() i geom_smooth() * tekstualni - geom_text()
Naravno, postoje i brojne druge vrste grafikona, ali spomenute vrste su najčešće korištene. Karte odnosno prostorni elementi (geom_polygon()) su posebna vrsta grafikona o kojoj ćemo kasnije posebno govoriti. Sve navedeno odnosi se na statičke vizualizacije odnosno “fiksne” grafikone koje možemo spremiti kao jpg, png, pdf ili neki drugi format. Osim statičkih vizualizacija postoje i dinamičke ili interaktivne vizualizacije. O njima će biti riječi u zasebnom poglavlju Dinamički izvještaji.
Vizualizacije na koje smo navikli pojavljuju se u dvodimenzionalnom Kartezijevom koordinatnom sustavu. Takav sustav omeđen je sa dvije osi apscisom (os x) i ordinatom (os y) koje se sijeku u ishodištu 0. Takav sustav ima četiri kvadranta. Trodimenzionalni Kartezijev koordinatni sustav dodatno je omeđen i trećom osi z. Trodimenzionalne vizualizacije su vrlo problematične obzirom da ih često percipiramo drugačije u odnosu na stvarnu strukturu i sadržaj podataka (Healy, 2019) te ih u ovoj knjizi nećemo obrađivati, a ggplot() ih također ne nudi kao jednostavan, elementarni oblik grafikona.
Kod odabira grafikona važno je poznavati strukturu i sadržaj našeg skupa podataka kao i klasu varijabli koje želimo vizualizirati. Nećemo koristiti iste vizualizacije i elemente za numeričke i kategorijalne varijable.
ggplot mnogo stvari pri izradi vizualizacije radi automatski. Primjerice, sam će odabrati skalu odnosno mjerilo na x i y osima. Također, ako koristimo boje, sam će odabrati paletu boja. No, sve to možemo mijenjati o ćemu će biti riječi u ovom poglavlju.
Boje, oblici i teme su važne komponente svake vizualizacije. Čak i ako je vaša vizualizacija crno-bijela, preostali vizualni elementi poput boje pozadine, veličine točke u dijagramu rasipanja ili oblika koji predstavlja određenu kategoriju igraju važnu ulogu u ukupnoj priči koju vaša vizualizacija predstavlja.
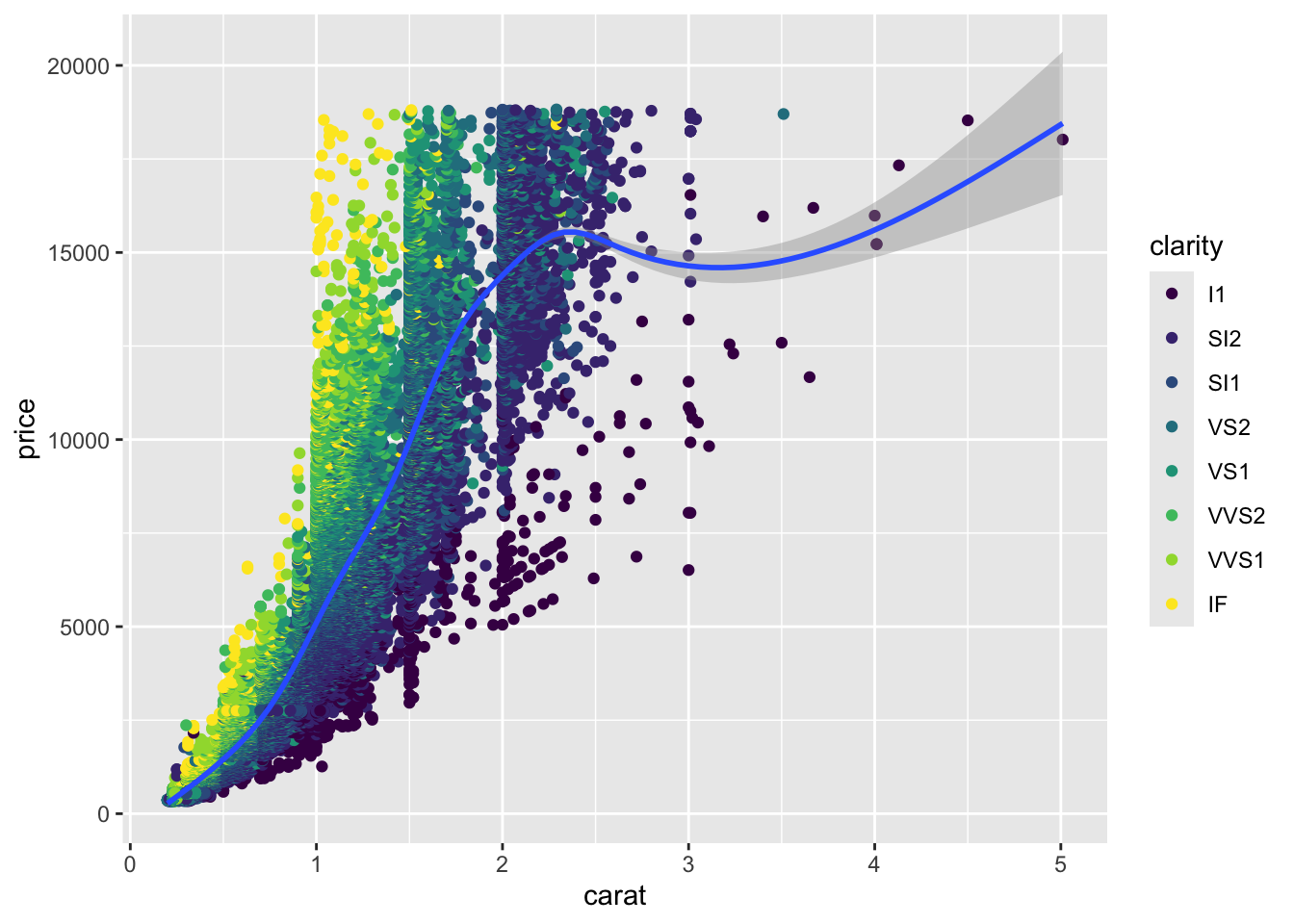
Na primjeru skupa podataka diamonds() kreirajmo dijagram rasipanja. Potom ga obogatim dodatnim slojem informacija odnosno elemenata vizualizacije: bojom i dodatnom geometrijskim elementom - linijskim grafikonom. Kreiranje vizualizacija u ggplot-u temelji se na slojevima (engl. layers). Na takav način funkcionira i izvođenje koda: R prvo “crta” sloj koji je i prvi po redu u našem kodu. Stoga je i u vizualizacijama ključan redoslijed u kodiranju.
`geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'
Dobili smo grafikon koji prikazuje odnos između veličine i cijene dijamanta. Dodatno, boja točke ovisi o transparentnosti dijamanta. Također, napravili smo i linijski grafikon koji nam pokazuje vezu između varijable veličine i cijene dijamanta. U konzoli smo dobili obavijest kako je korištena metoda “gam” odnosno generalizirani aditivni model. Možemo pretpostaviti sljedeće: 1) postoji više metoda unutar geom_smooth() funkcije 2) “gam” metoda je zadana postavka (ona koja će se upotrijebiti ako ne promijenimo argument method=) Ako želimo prikazati linearnu vezu, unutar geom_smooth() funkcije potrebno je dodati argument method="lm".
Isto tako, sve ostale geom_ funkcije razlikuju brojne argumente.
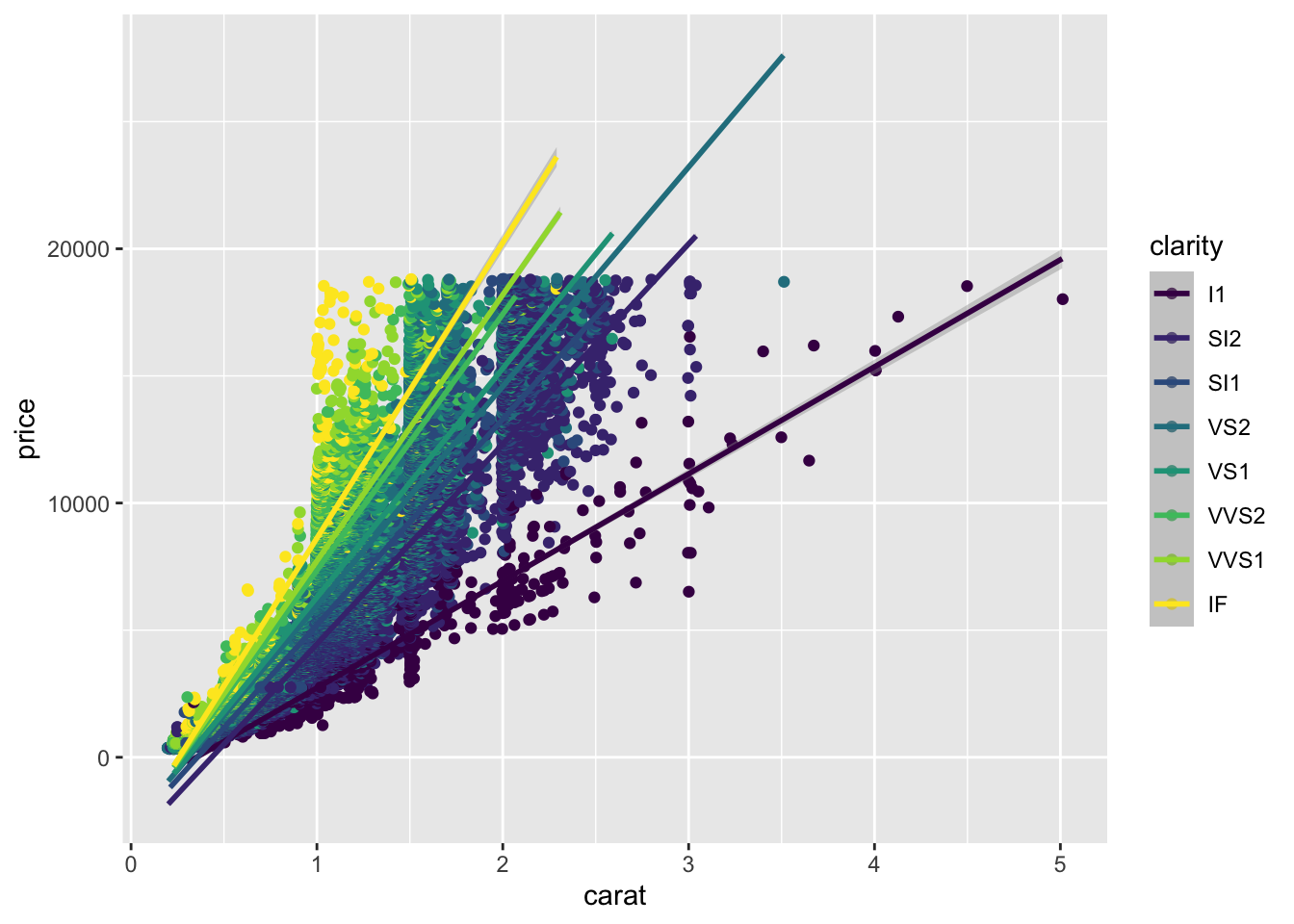
Na grafikonu vidimo da dosta dijamanata ima veličinu zaokruženu na cijeli (1,2 karata) ili pola broja (0,5, 1,5 karata). Pretpostavit ćemo da je to tako jer se režu na te veličine iz praktičnih, marketinških i tržišnih razloga. Zbog navedenog nam se mnogo točaka preklapa. Ovom problemu možemo doskočiti na način da umjesto geom_point() koristimo geom_jitter() vizualizaciju koja će svaku točku za nijansu pomaknuti tako da bude što manje preklapanja. U našem slučaju geom_jitter neće rezultirati boljom vizualizacijom jer je on koristan kod manjih skupova podataka. Iako geom_jitter kod manjih skupova grafikon poboljšava u vidu preglednosti, geom_jitter() ne predstavlja izvorni sadržaj podataka te ga je potrebno oprezno koristiti. Dodatno, umjesto “gam” metode, upotrijebimo linearnu vezu odnosno linearni model.
ggplot(diamonds, aes(carat, price, color = clarity))+geom_jitter()+geom_smooth(method ="lm")
`geom_smooth()` using formula = 'y ~ x'
Još jednom primjetimo da argument color= (kao i fill=) možemo pisati u globalnim ggplot argumentima, ali i zasebno zasvaki element (u ovom slučaju mogli smo ga upisati kao argument funkcije geom_jitter). Kada argument pišemo u globalnim ggplot opcijama, onda se on odnosi na sve elemente odnosno geom_ funkcije, a kada argument pišemo unutar pojedine geom_ funkcije onda se on odnosi samo na taj sloj grafikona. Također, važno je razlikovati argument unutar aes() funkcije koji predstavlja varijablu, u odnosu na argument izvan aes() funkcije koji predstavlja nekakvo obilježje geom_ funkcije odnosno sloja vizualizacije. R literatura smatra argumentima samo funcije poput aes(), na.rm=, method= dok color=, size=, alpha= naziva aesthetics odnosno vizualnim opcijama pojedine geom_ funkcije. Sve argumente i aesthetics-e neke geom_ funkcije možemo vidjeti s naredbom ? uz naziv funkcije, primjerice ?geom_smooth. Poduprimo ovo s primjerom.
library(ggplot2)#pogledajmo sve opcije koje geom_smooth razumije?geom_smooth
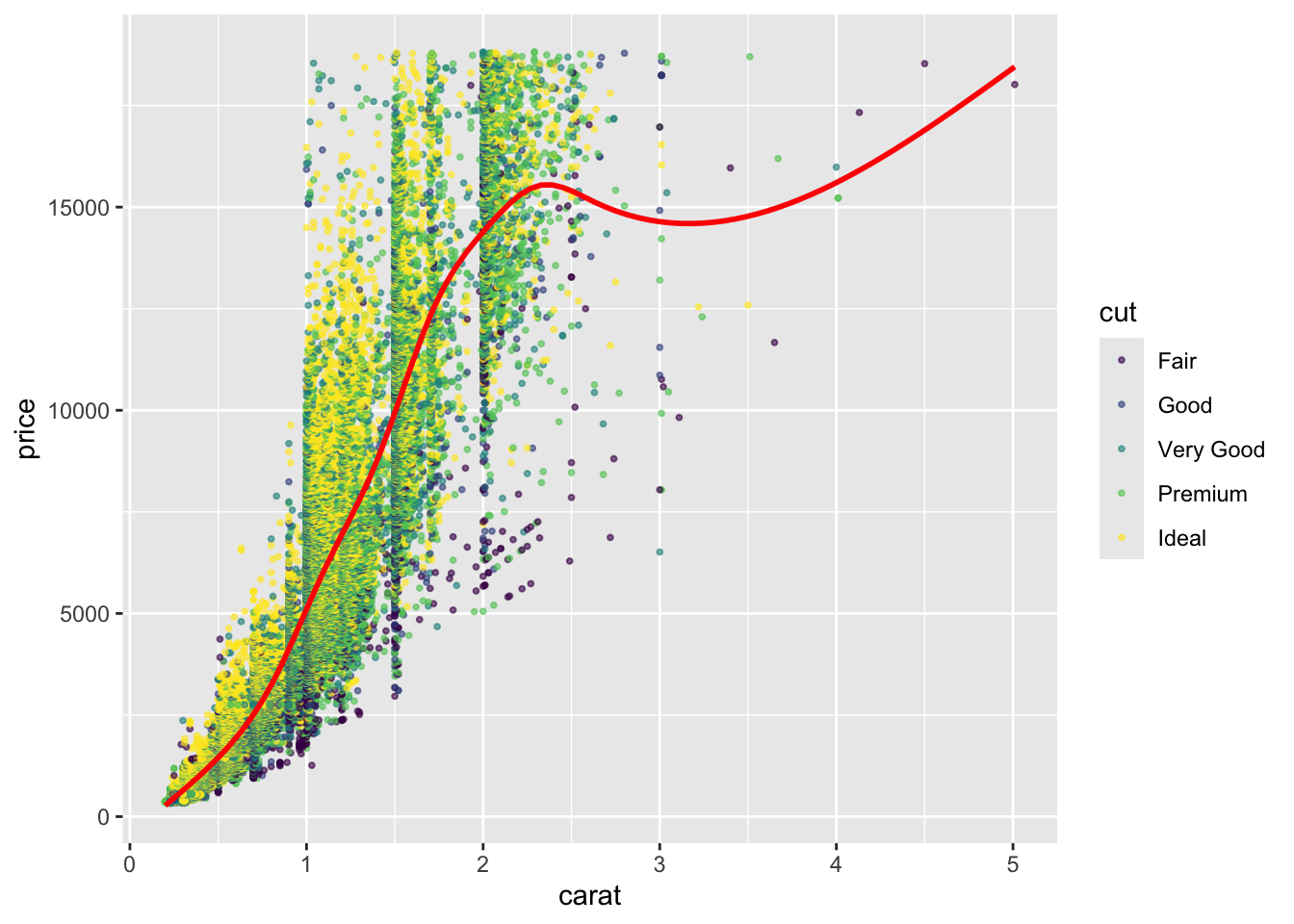
#iskoristimo dodatne aesthetics-e size, alpha i colorggplot(diamonds, aes(carat, price))+geom_point(aes(color=cut), size =0.7, alpha =0.6)+geom_smooth(color="red", se = F)
`geom_smooth()` using method = 'gam' and formula = 'y ~ s(x, bs = "cs")'
Točke smo obojali ovisno o rezu dijamanta i za to smo koristili aes() funkciju. Dodatno smo promijenili (smanjili) veličinu točaka sa size te transparentnost točaka sa alpha koju smo stavili na 60%. Boju geom_smooth krivulje smo stavili na crvenu, te odredili da ne želimo prikaz standardne pogreške sa se=F.
R razlikuje 657 naziva boja koje smo mogli upisati u prehodnom grafikonu umjesto “red”. Možemo ih pogledati s funkcijom colors().
# pogledajmo nazive ugrađenih bojacolors()
No, R razumije i heksadecimalni sustav naziva boja. U tom sustavu crvena (r), zelena (g) i plava (b) su predstavljene s dva znaka (#rrggbb). Svaki znak ima 16 mogućih simbola: 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F. Postoje brojni alati kojima možemo za željenu boju ili specifičnu nijansu pronači kod. Primjerice na https://htmlcolorcodes.com/ možemo odabrati željenu nijansu boje i kopirati heksadecimalni kod boje (hex).
Ručno možemo mijenjati boje sa funkcijom scale_color_manual() ili scale_fill_manual(), ovisno o tome stavljamo li u aes() argument color ili fill za varijablu temeljem koje želimo bojati neki sloj vizualizacije.
Naša preporuka je da ne odabirete ručno boje odnosno palete i kombinacije boja za vizualizacije. Zanemariv broj korisnika poznaje odnose među bojama odnosno kako ti odnosi utječu na našu percepciju vizualizacije. R stoga ima zadane palete boja koje su prilagođene na način da budu što neutralnije odnosno da što vjernije prikazuju odnose među vrijednostima. Također, neke ugrađene palete boja u R-u su prilagođene i korisnicima slijepima na boje. Dodatno, postoji i nekolicina R paketa koji su vrlo često korišteni, gotovo pa standardni u R zajednici. To su, uz ugrađene palete, RcolorBrewer i colorspace koje je potrebno dodatno instalirati kao paket.
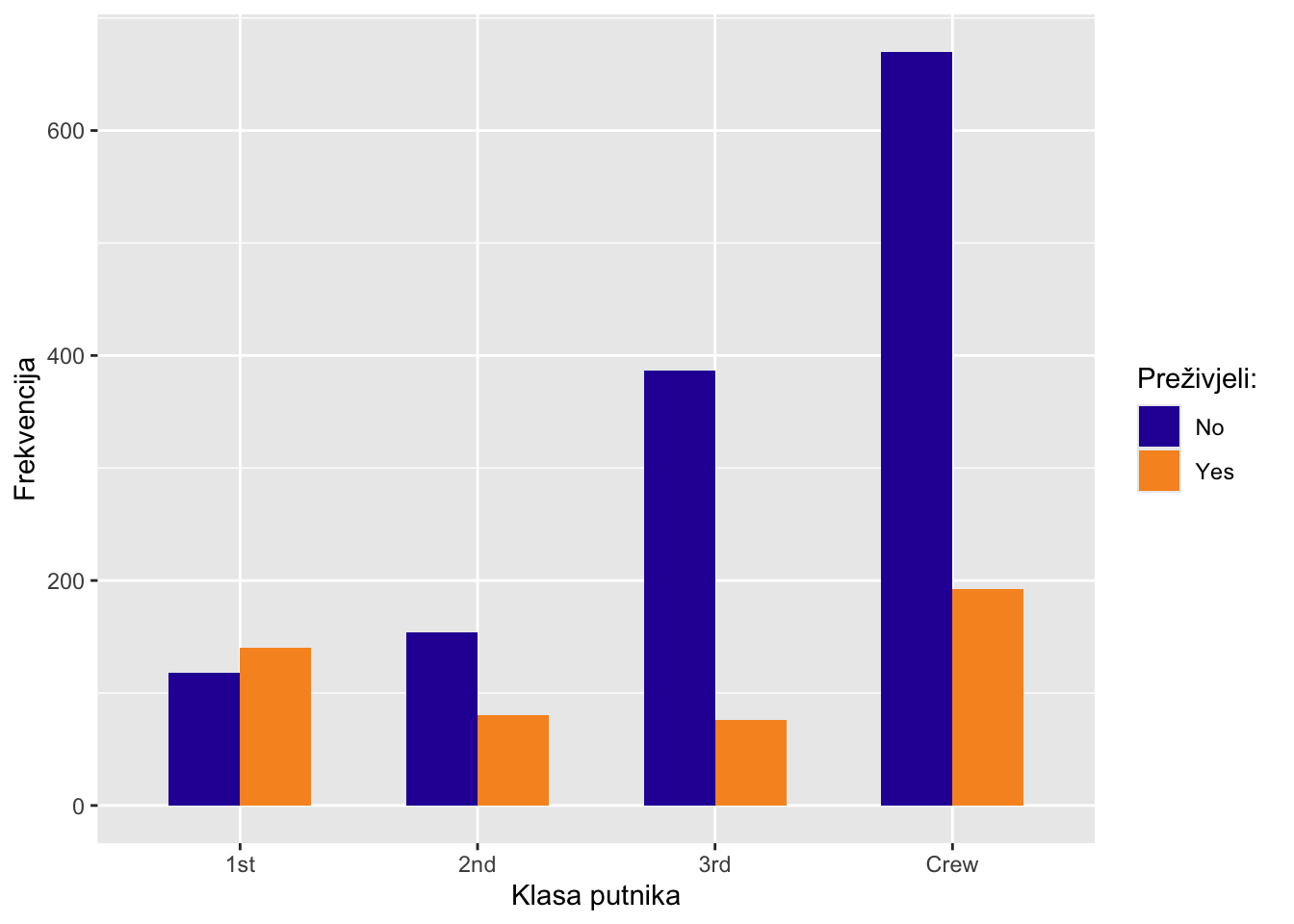
Kreirajmo stupčasti grafikon koristeći ugrađeni skup podataka o putnicima Titanic-a. Obzirom da je on klase table, pretvorimo ga prvo u data frame. Nakon toga, ručno promijenimo vizualne elemente: boju stupaca sa scale_fill_manual(), ali i naslove x i y osi sa funkcijom labs().
Napravite prethodni grafikon bez argumenta position = "dodge". Kakva promjena se dogodila?
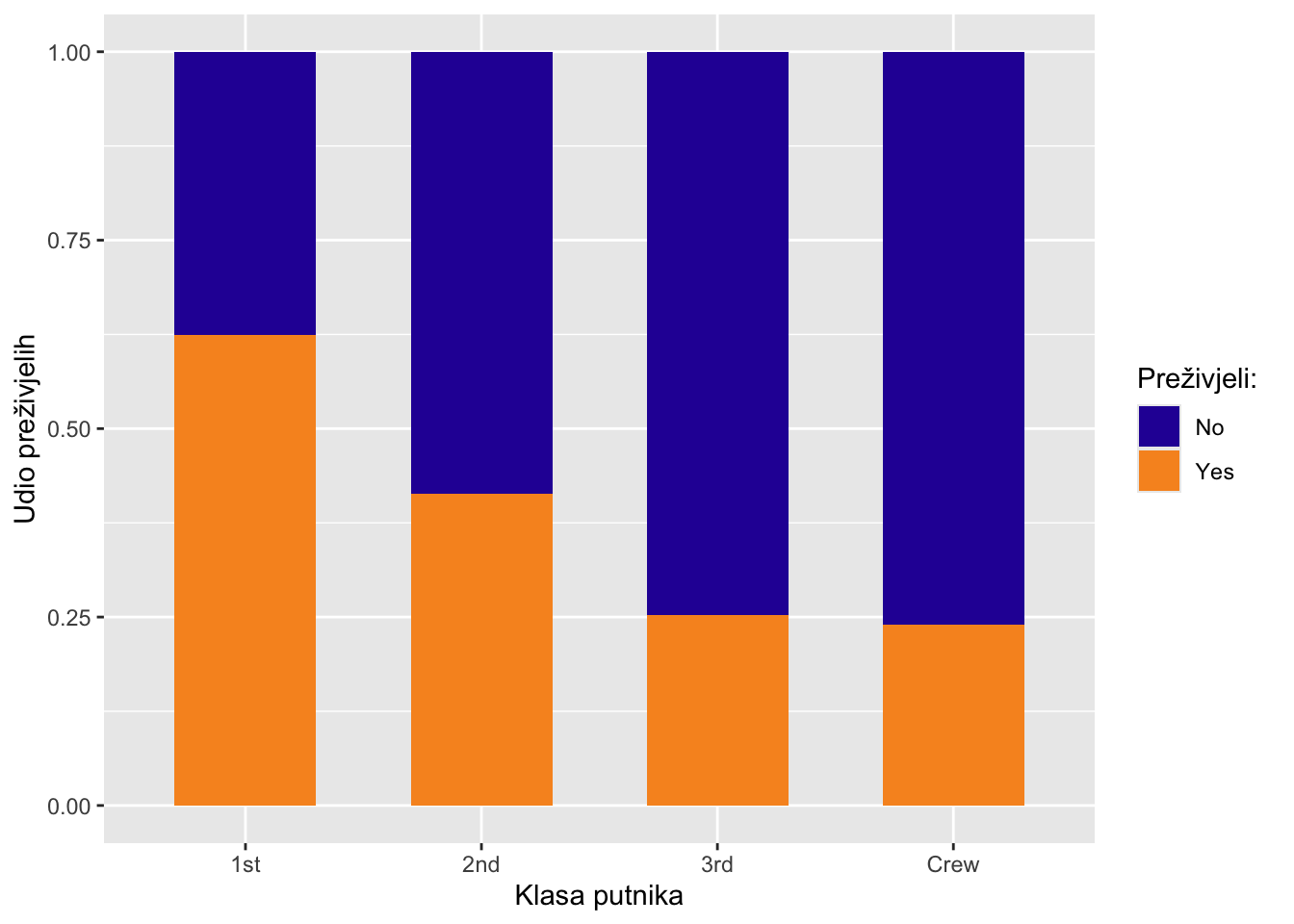
Iz vizualizacije frekvencija očito je da putnika u prvoj i drugoj klasi ima bitno manje nego li onih u trećoj klasi ili posade. Ako želimo bolje usporediti same udjele preživjelih unutar skupine putnika, možemo promijeniti samo jednu opciju u prethodnom grafikonu, a to je pozicijska opcija unutar geom_bar() koju ćemo promijeniti u position = "fill". Sada ćemo dobiti grafikon s jednakom visinom stupaca odnosno udjele preživjelih u svakoj klasi putnika.
Ovime smo preglednije prikazali kolika je bila stopa prežiljavanja po svakoj klasi putnika i vidimo da su u relativnom odnosu najbolje prošli putnici prve klase kojih je više od pola preživjelo havariju Titanika.
Idemo “okrenuti” predzadnji grafikon vodoravno. Za to nam je potrebna naredba coord_flip(). Dodatno ćemo promijeniti cjelokupni izgled grafikona kroz temu.
Naša preporuka je da stupčasti grafikon uvijek “okrenemo” kada na apscisi (x os) imamo kategorijalne (factor) ili znakovne (character) varijable u obliku teksta, a to se posebno odnosi kada su natpisi kategorija na x-osi dugi i teško čitljivi okomito.
8.3 Natpisi na osima i teme
Do sada smo mogli vidjeti da ggplot odnosno R automatski određuje mjerilo i nazive na osima, ali te elemente možemo i ručno mijenjati. Ručno mijenjanje mjerila i natpisa na osima radimo kroz set funkcija koje započinju sa scale_x_ i scale_y_. Nastavak funkcije scale_x_ ovisi o tipu (class) podataka koji se nalazi na osi koju mijenjamo. Na primjeru iz skupa podataka population, pogledajmo kako napraviti grafikon u kojem ćemo ručno promijeniti natpise i mjerilo na x i y osima. Dodatno, koristimo paket scales koji je praktičan za ručno mijenjanje osi. Paket scales sadrži niz funkcija kojima automatiziramo prikaz varijabli odnosno njihovu mjernu jedinicu, mjerilo i slično (primjerice, paket scales sadrži jednostavne funkcije kojima decimalne brojeve prikazujemo kao postotke).
library(scales)head(population) # pogledajmo što sadrži ugrađeni skup podataka "population"
# A tibble: 6 × 3
country year population
<chr> <dbl> <dbl>
1 Afghanistan 1995 17586073
2 Afghanistan 1996 18415307
3 Afghanistan 1997 19021226
4 Afghanistan 1998 19496836
5 Afghanistan 1999 19987071
6 Afghanistan 2000 20595360
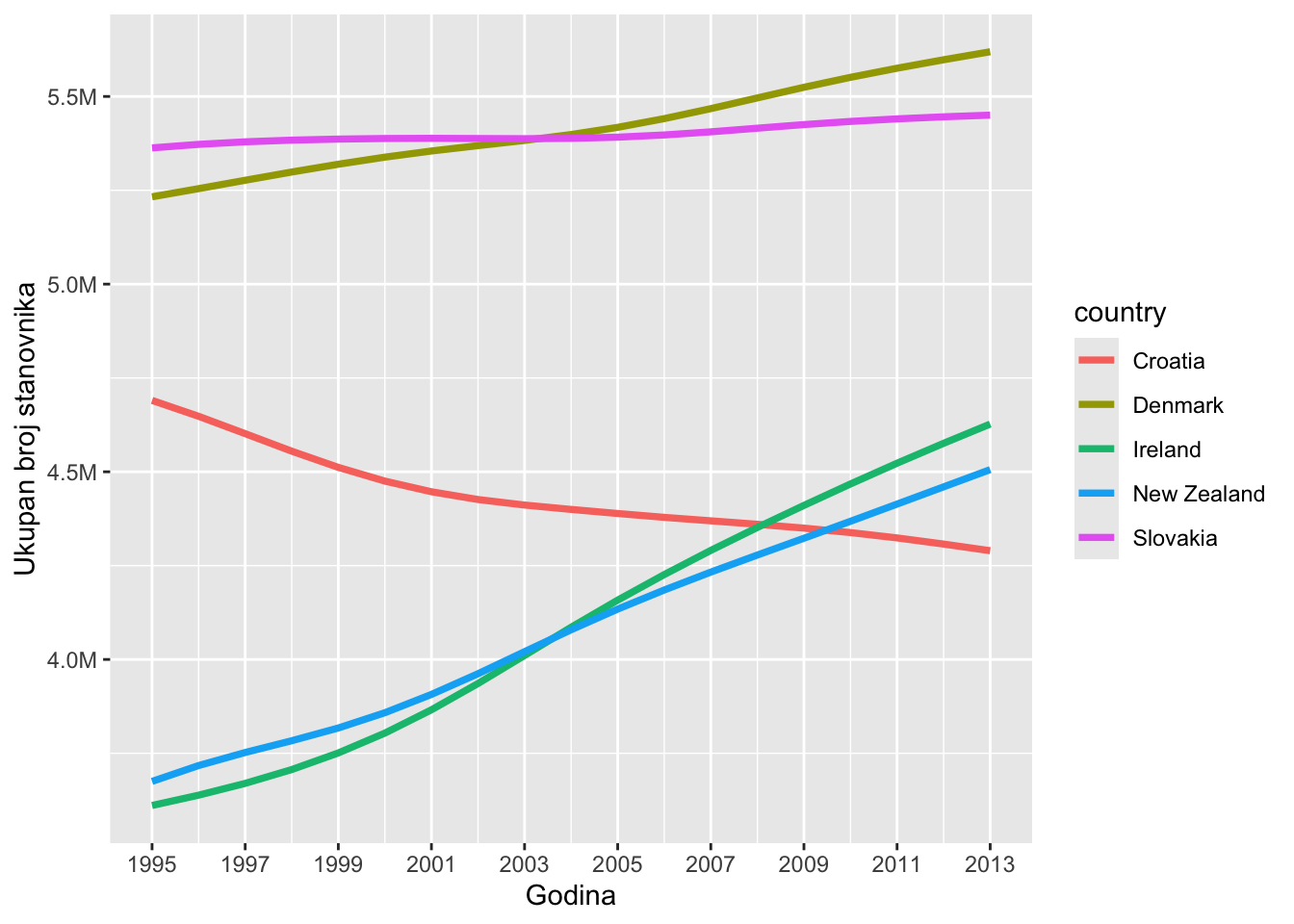
# odaberimo nekoliko zemalja od interesastanovnistvo <- population %>%filter(country %in%c("Croatia", "Denmark", "Slovakia", "Ireland", "New Zealand")) ggplot(stanovnistvo, aes(year, population, color = country))+geom_line(size=1.3)+scale_x_continuous("Godina", breaks =seq(1995,2013,2))+scale_y_continuous("Ukupan broj stanovnika", labels =label_number(scale_cut =cut_short_scale()))
U ovom primjeru, ručno smo promijenili x os tako da pokazuje svaku drugu godinu, počevši od 1995 godine (jer je to početna godina u skupu podataka population). Os y smo promijenili tako da prikazuje stanovništvo u milijunima sa oznakom M (u izvornom skupu podataka podaci su navedeni u točnim iznosima, a prikaz punih brojki na y osi je u ovom slučaju manje pregledan). Za to smo koristili funkciju scale_cut() iz paketa scales koja automatski “skrati” brojke i doda sufiks ovisno radi li se o tisućama (K), milijunima (M), milijardama (B) ili bilijunima (T). Dva osnovna argumenta u setu funkcija scale_x_ i scale_y_ su breaks= i labels=. U ovom primjeru smo također mogli vidjeti da sa funkcijama scale_x_continuous() i odgovarajućoj funkciji za y os možemo ručno promijeniti i glavni naziv osi, jednako kao i u funkciji labs().
Teme su set naredbi kojima modificiramo opće karakteristike vizualizacije, a najćešće se odnose na veličinu znakova, boju pozadine, pomoćne osi (rešetke) u pozadini, oznake na osima i slično. Postoje predefinirane teme u osnovnom R kodu, ali i u ggplot2 paketu. Također, postoje i dodatni paketi koji sadrže teme. Neki od najpoznatijih paketa za teme su ggthemes i hrbrthemes. Osim predefiniranih tema, sami možemo spremiti i svoju temu kao objekt i pozvati ju unutar ggplot funkcije.
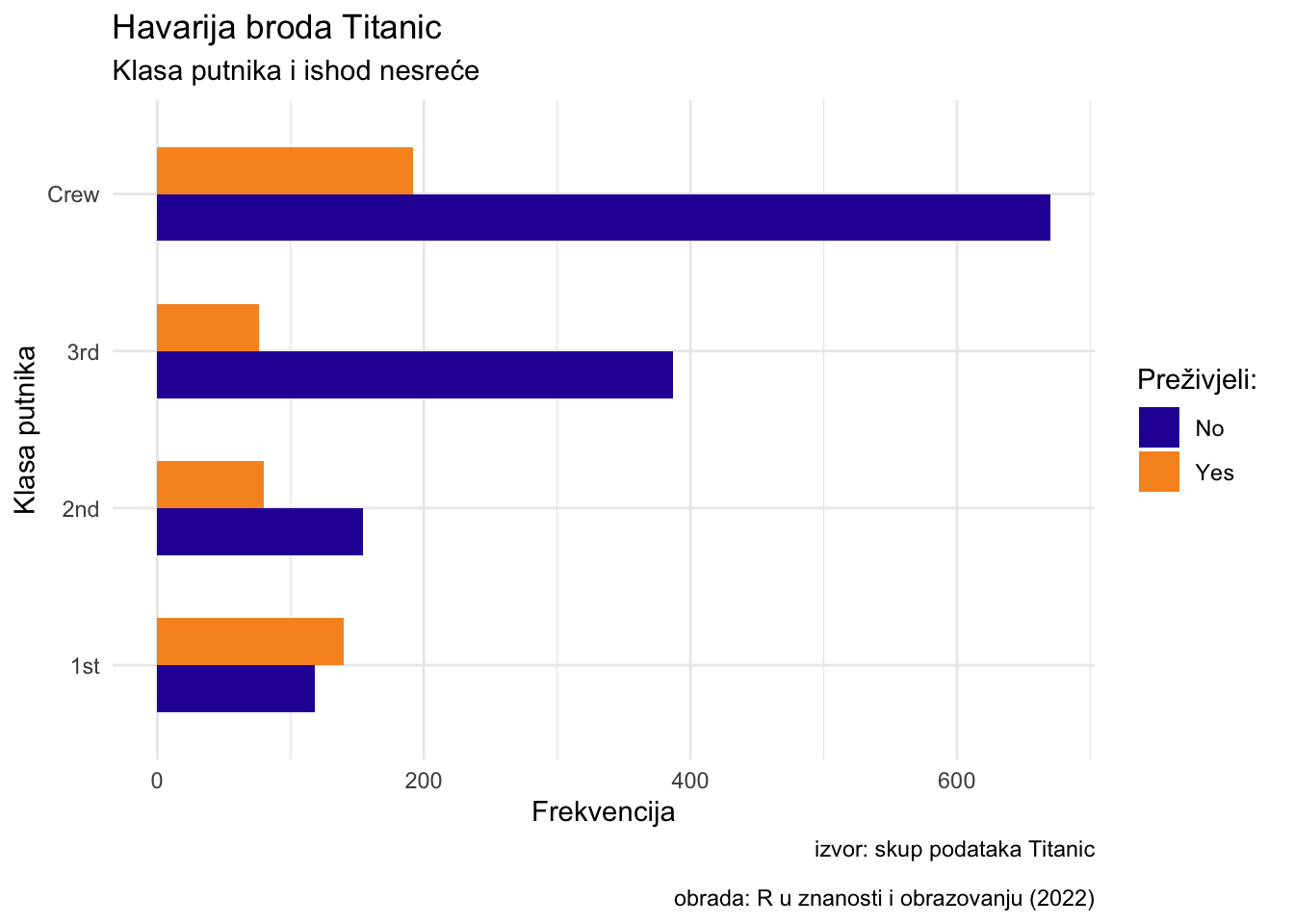
Na sljedećem primjeru upotrijebimo ugrađenu temu naziva theme_minimal(). Dodajmo naslov, podnaslov i opis grafikona u funkciji labs().
Titanic <-as.data.frame(Titanic) ggplot(Titanic, aes(Class, Freq, fill=Survived))+geom_bar(stat ="identity", position ="dodge", width =0.6)+scale_fill_manual(values =c("#2a1ca4", "#f79425"))+labs(x ="Klasa putnika",y ="Frekvencija",fill ="Preživjeli: ",title ="Havarija broda Titanic",subtitle ="Klasa putnika i ishod nesreće",caption ="izvor: skup podataka Titanic\n obrada: R u znanosti i obrazovanju (2022)")+coord_flip()+theme_minimal()
Primjetimo znak \n u opisu (caption) grafikona. Znak \n označava prelazak teksta u novi redak.
Argument stat = "identity" unutar geom_bar() funkcije je argument pozicije. Njega koristimo kada želimo prikazati odnos između dvije varijable takav kakav je (najčešće kad je jedna od njih numerička, kao ovjde varijabla Freq). U slučaju stat = "identity", ggplot neće ništa računati već prikazati odnos onakav kakav je u izvornom skupu podataka.
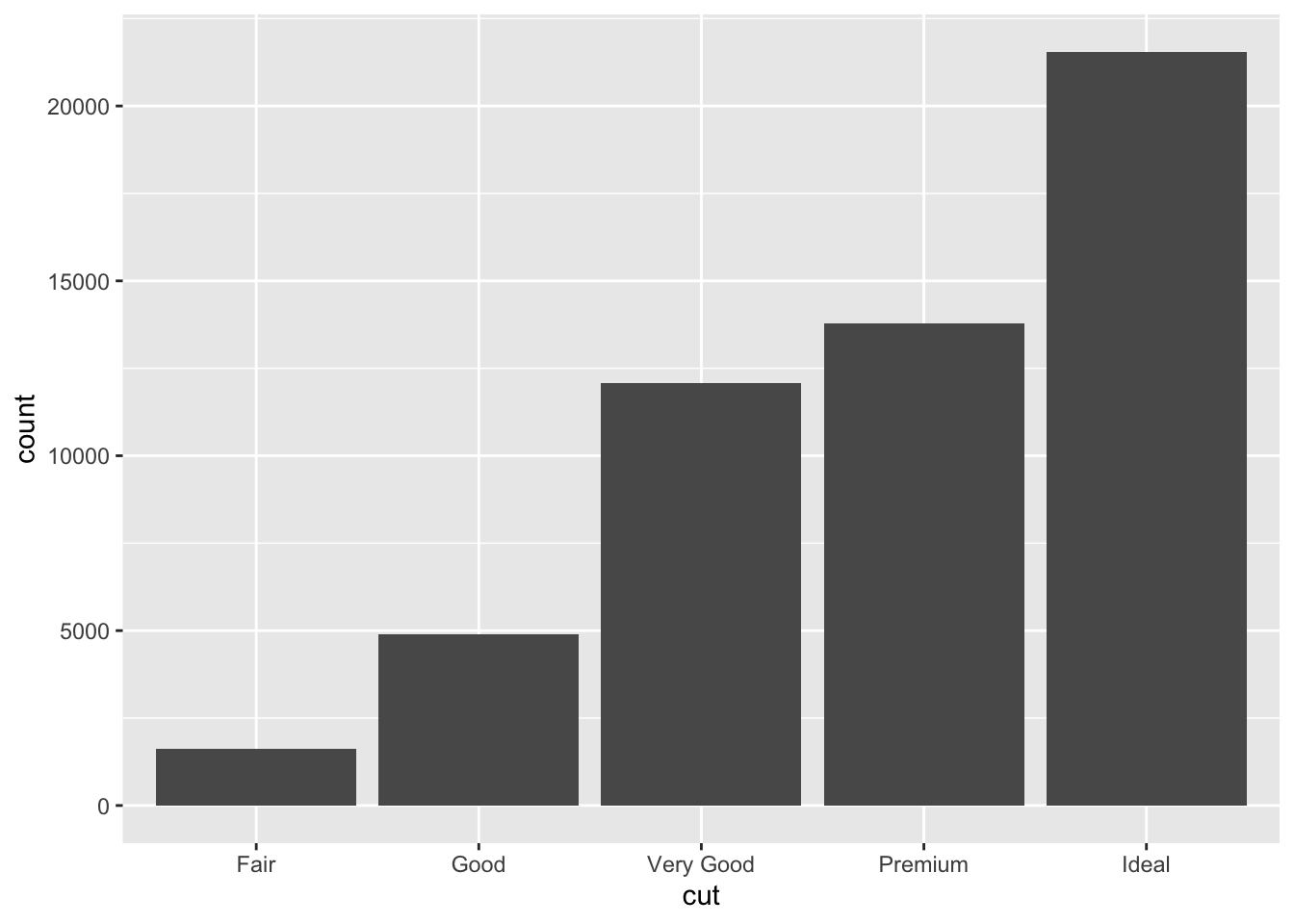
Ukoliko želimo prikazati frekvenciju samo jedne varijable, nećemo navoditi y argument unutar aes(), ali umjesto stat="identity" koristimo stat="count". To je i zadana vrijednost za geom_bar() pa ne trebamo izrijekom ni pisati stat="count". Tada će ggplot() izračunati frekvenciju za navedenu x varijablu. Pogledajmo na primjeru skupa diamonds() gdje ćemo sa geom_bar i zadanom postavkom stat=“count” izračunati frekvencije dijamanata prema vrsti reza.
ggplot(diamonds, aes(cut))+geom_bar()
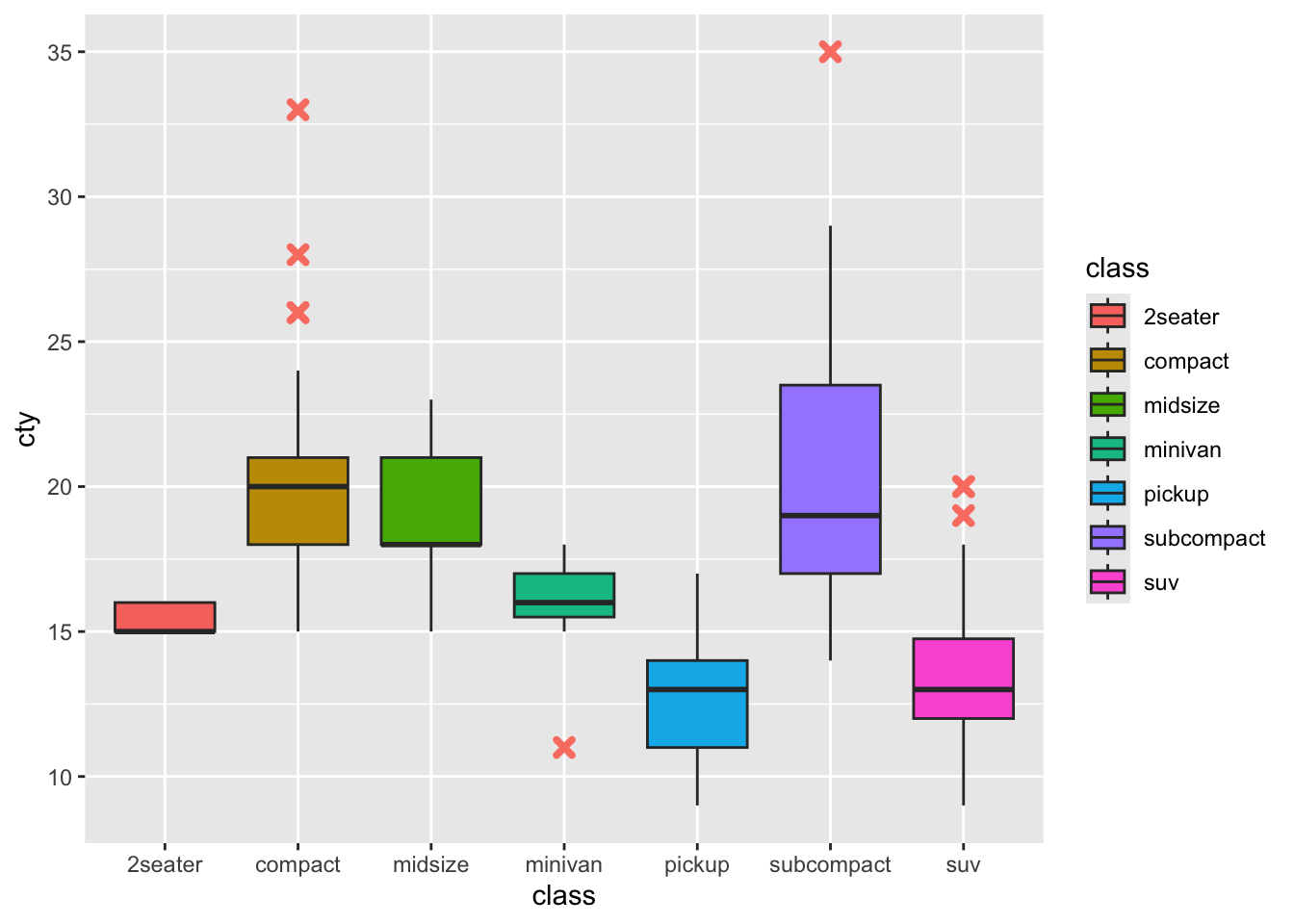
Ocije size, linetype i shape mijenjaju izgled linije ili točke. Na primjeru geom_boxplot() funkcije pogledajmo kako mijenjaju oblik izdvojenica sa argumentima outlier.shape i outlier.stroke kojim mijenjamo debljinu fonta. Svaki oblik ima svoju brojčanu oznaku.
Do sada smo radili vizualizacije nad skupovima podataka koje nismo mijenjali. U svakodnevnom radu koristit ćemo podskupove podataka, transformirati izvorne podatke i raditi više manipulacija nad izvornim skupom prije nego ga vizualiziramo. U ovom dijelu povezat ćemo znanje iz poglavlja upravljanje podacima sa metodama vizualizacije podataka. U praktičnom smislu to znači povezivanje radnji transformacije i manipulacije podataka sa ggplot() funkcijom. Za navedeno ćemo koristiti pipe (%\>%) operator. Kod ovakvog povezivanja važno je ponoviti da se radnje odvijaju u redoslijedu izvođenja koda te da ne navodimo data argument unutar ggplot() funkcije jer podaci odnosno data argument dolazi s lijeve strane ggplot() funkcije kroz podatke koji su transformirani i povezani s pipe operatorom na ggplot() funkciju.
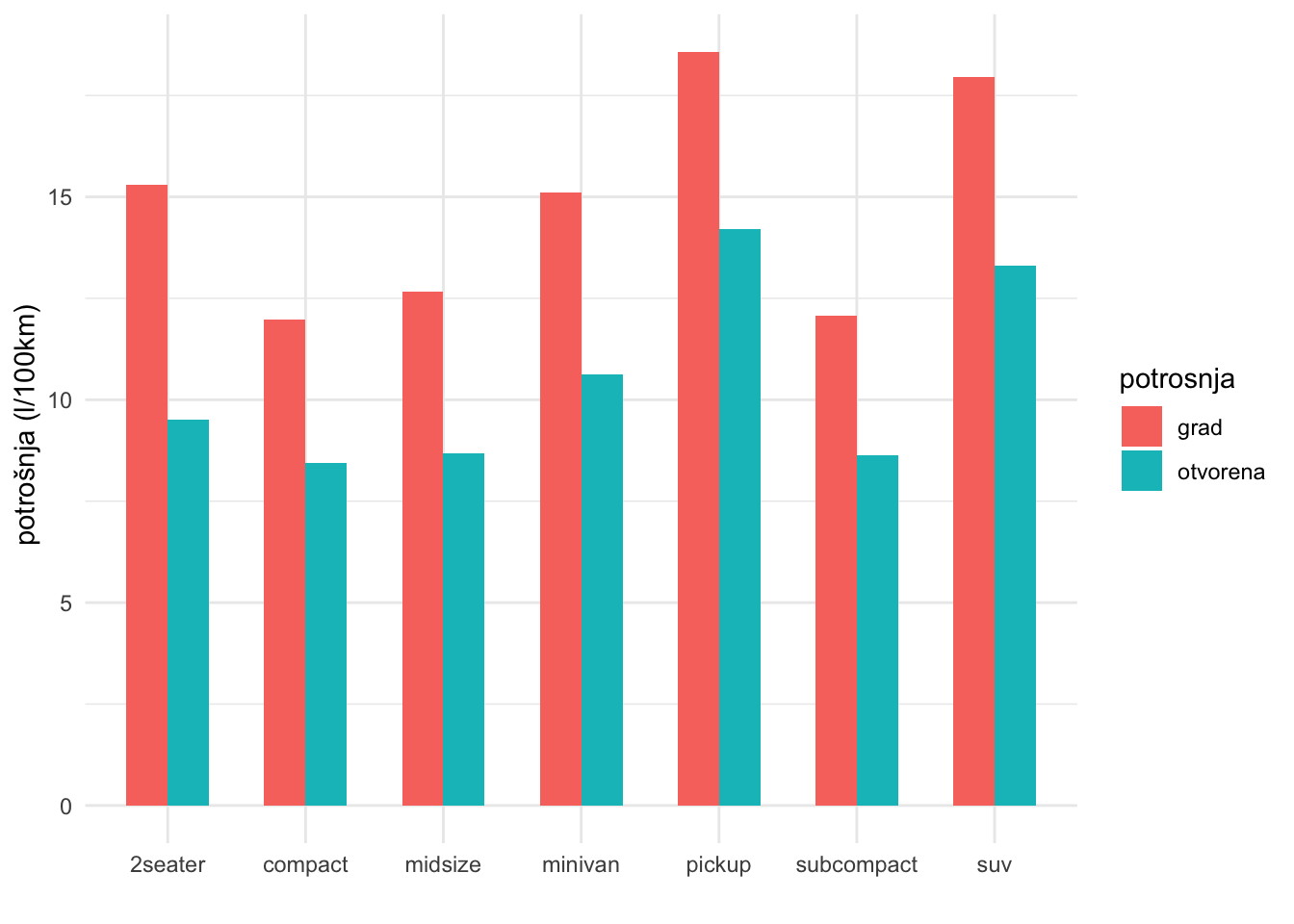
Na primjeru skupa mpg, povežimo nekoliko radnji s crtanjem stupčastog grafikona. Cilj nam je prikazati potrošnju u gradu i na otvorenoj cesti za svaku vrstu automobila (varijabla “class”). Potrošnju u litrama na 100km dobit ćemo tako da 235,2 podijelimo s potrošnjom u miljama po galonu (mjerna jedinica potrošnje u skupu mpg).
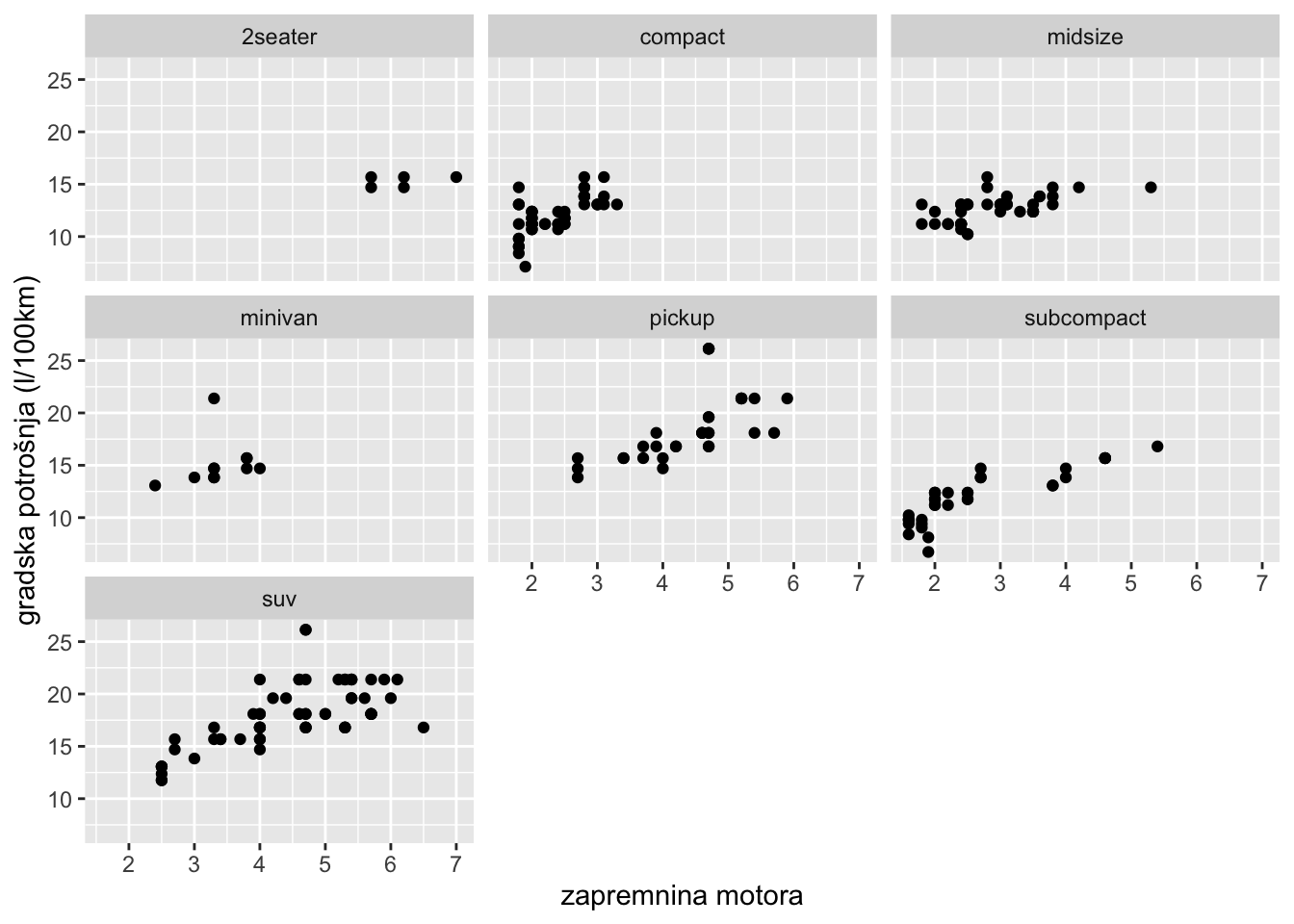
Do sada smo kategorijalne varijable ili grupirane podatke isticali bojama (color ili fill funkcijama) ili oblicima (shape, linetype, size funkcijama) na istoj vizualizaciji. No, ponekad to nije pregledno ili želimo vizualizirati svaku grupu odvojeno. To možemo raditi tako da napravimo više odvojenih grafikona ili koristeći facet-e. Koristeći facet opciju možemo elegantno i pregledno vizualizirati modalitete kategorijalne varijable. Na primjeru skupa mpg pogledajmo odnos između zapremnine motora (varijabla “displ”) i gradske potrošnje u litrama (podijelimo 235.2 sa varijablom “cty” koja predstavlja potrošnju u miljama po galonu), ali odvojimo grafikone za svaku klasu automobila (varijabla “class”).
Koristeći funkciju facet_wrap() kreirali smo vizualizaciju podijeljenu na klase automobila. Jedini argument koji nam je bio potreban je varijabla kojom će facet_wrap() funkcija grupirati podatke, a on se piše unutar funkcije nakon oznake ~.
Funkcija nam je automatski odabrala broj redaka i stupaca (grafikona), a to možemo ručno promijeniti sa opcijama nrow= ili ncol= unutar facet_wrap() funkcije.
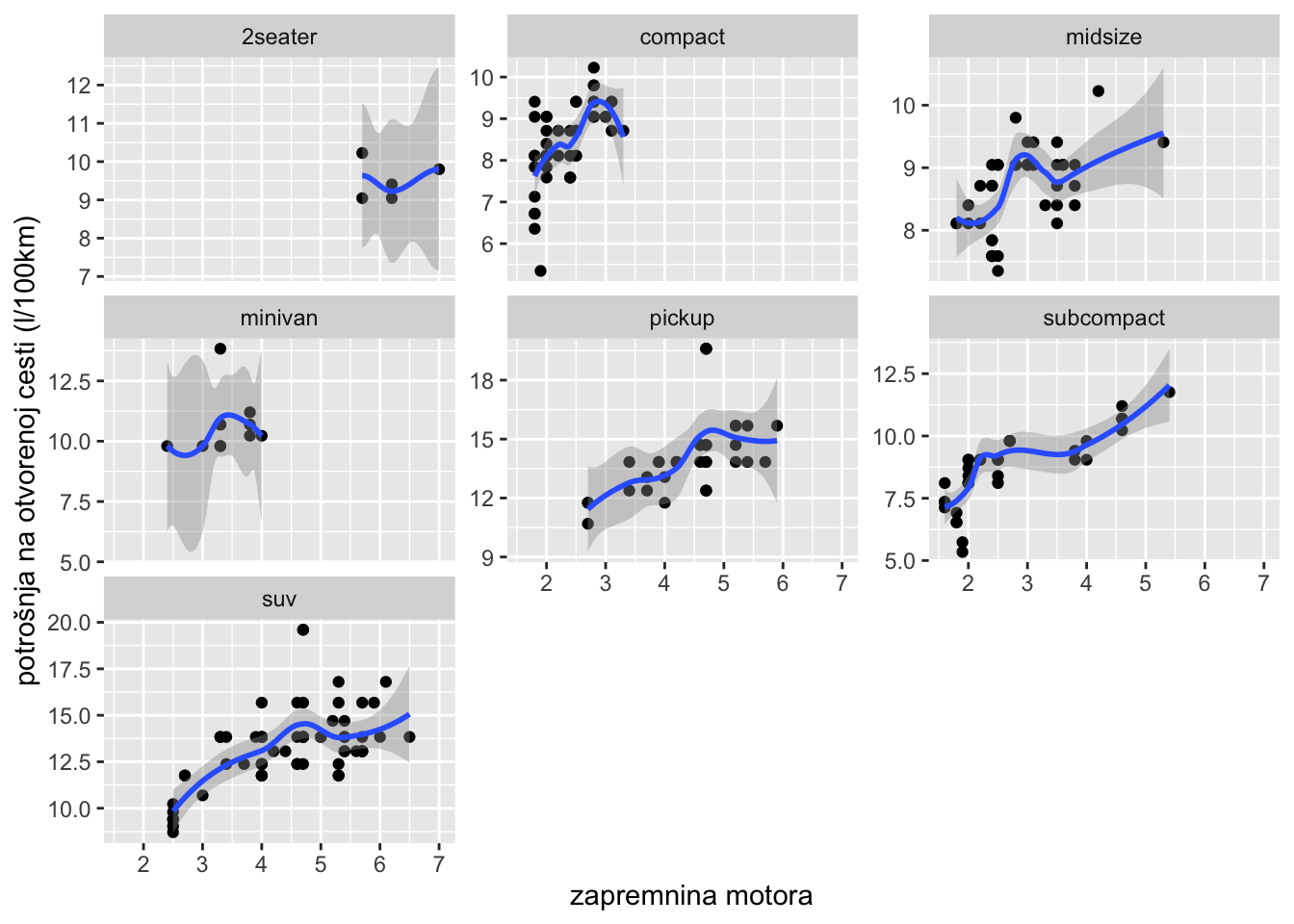
Obratite pozornost da našem primjeru x i y osi imaju ista mjerila za sve klase automobila. Ukoliko želimo imati različita mjerila na osima za svaki grafikon, možemo upotrijebiti opcije scales="free_x ili scales="free_y. Pogledajmo na sljedećem primjeru u kojem će svaka klasa automobila imati zasebnu y os koja prikazuje potrošnju na otvorenoj cesti (varijabla “hwy”). Ovaj puta, osim samog dijagrama rasipanja, dodajmo i liniju trenda (zanemarimo što nije idealno raditi liniju trenda na ovako malom broju opažanja u nekim klasama automobila) i primjetimo da i Facet-i također mogu imati više geometrijskih funkcija.
ggplot(mpg, aes(displ, 235.2/hwy))+geom_point()+geom_smooth()+facet_wrap(~class, scales ="free_y")+labs(x="zapremnina motora",y="potrošnja na otvorenoj cesti (l/100km)")
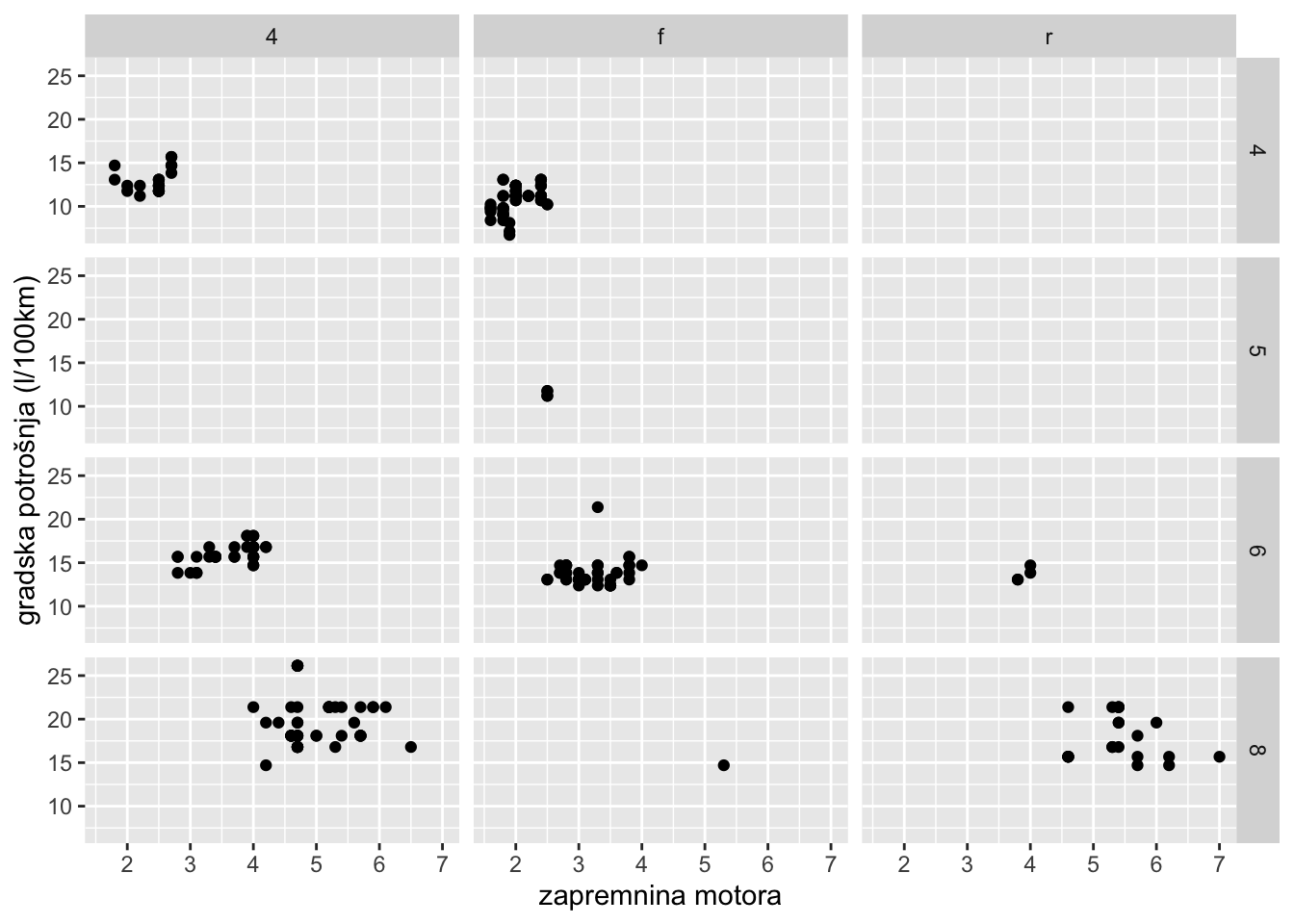
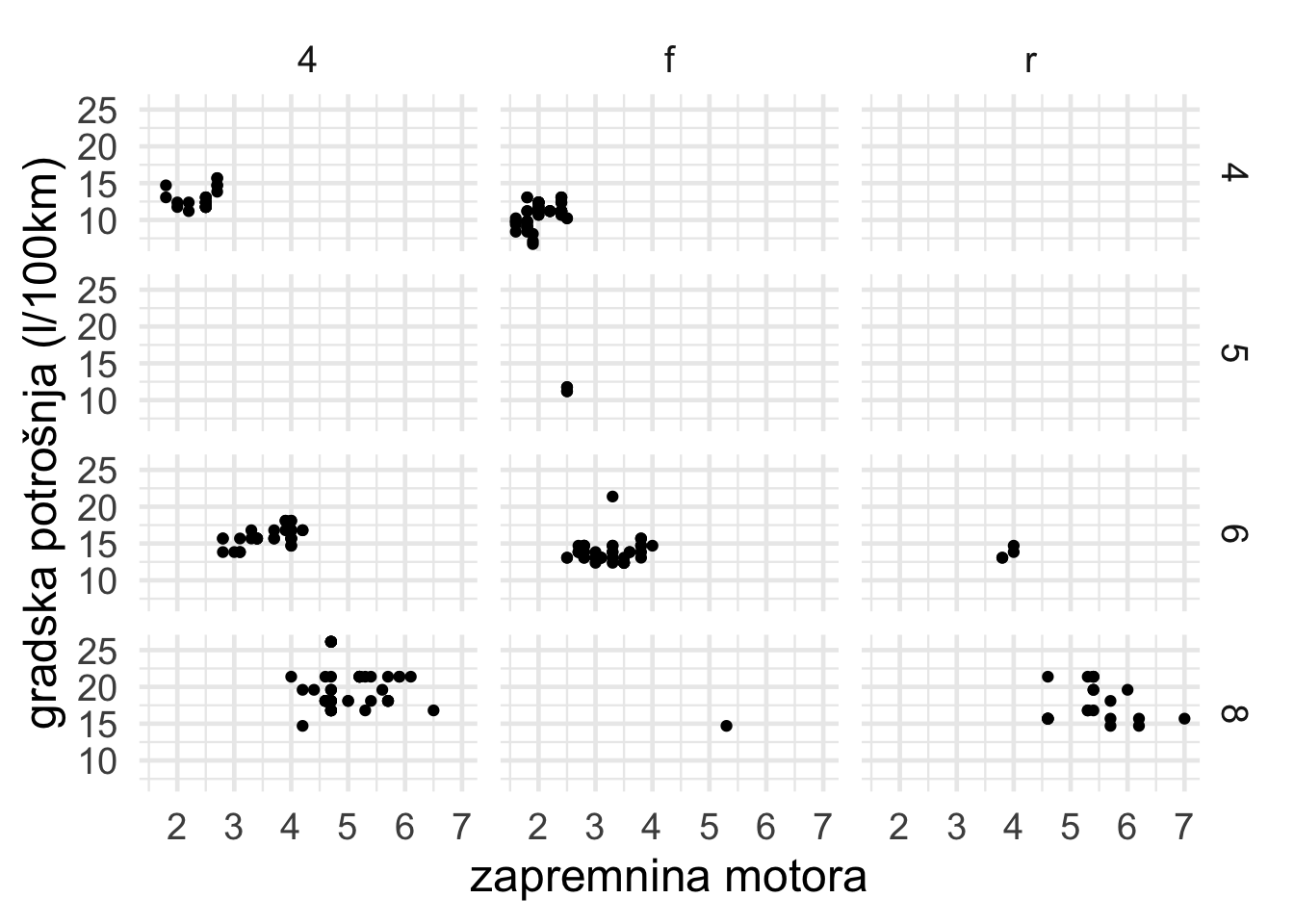
Kada želimo prikazati odnos između dvije varijable pomoću facet-a koristit ćemo funkciju facet_grid(). Nastavljajući se na naša prethodna dva primjera, dodajmo u facet-e odnos između pogonskih kotača (4x4, prednji i stražnji) i broja cilindara u motoru.
Sada kada znamo napraviti vizualizaciju podataka u R okruženju, potrebno je naučiti kako tu vizualizaciju izvesti iz R okruženja. Iako mnoge analize možemo od početka do kraja napraviti u R okružju, uključujući komunikaciju rezultata (prezentacija, tekstualni dokument, web stranica i ostalo), projekt ili suradnici mogu zahtijevati izlazak iz R okruženja.
Vizualizacija koju smo uspješno napravili i koju vidimo u RStudio okviru “Plots”, spremljena je tek u kratkotrajnu memoriju i završetkom aktualne R sesije, ona nestaje. No, vrlo jednostavno možemo ju izvesti kao zasebnu datoteku.
U RStudiu postoji i prečac odnosno point-and-click opcija za izvoz vizualizacije i nalazi se u okviru “Plots” odmah poviše vizualizacije pod ikonicom “Export”. Ovaj način nudi nam opcije izvoza kao slikovne datoteke (Save as Image) ili u PDF formatu (Save as PDF). Klikom na spremanje vizualizacije kao slikovne datoteke otvara se novi okvir u kojem odabiremo naziv vizualizacije i veličinu vizualizacije. Ako mijenjate veličinu vizualizaciju, pazite na omjer vizualizacije odnosno aspect ratio kojeg možemo fiksirati u ovom okviru. Ovdje također možemo promijeniti i format slikovne datoteke koji ćemo dobiti, a zadan je .png format. Spremanje vizualizacija u PDF formatu je standard u dijeljenju dokumenata jer je format vrlo prilagodljiv, optimiziran za printanje i dijeljenje te je potpuna replika izvornog dokumenta, jednak na svim uređajima (računalo, mobilni uređaj, tablet i ostalo). Osim toga, PDF format zadržava kvalitetu i kad se grafikon “zumira” jer sprema vizualizaciju u vektorskom obliku za razliku od raster formata kod JPG, PNG, GIF i ostalih.
Istu operaciju možemo napraviti i kroz kod. Za to ćemo koristitiggsave() funkciju. Zadana opcija ggsave() funkcije je da spremi posljednje kreiranu vizualizaciju te stoga nije potrebno navoditi na koji grafikon se odnosi spremanje jer najčešće grafikon nećemo spremati kao zaseban R objekt u Environment (iako to možemo raditi i u nekim slučajevima ima svoju korist). Jedini potreban argument u ggsave() funkciji je naziv datoteke koji želimo dati. Među ostalim, možemo mijenjati format (zadani je .png format, a mijenjamo ga kroz opciju device=), veličinu (height= i width= opcije) i gustoću točaka (opcija dpi=).
Zapamtite da je veličina vizualizacije jako bitna. Prevelika rezolucija vizualizacije rezultirat će “sitnim slovima” te je potrebno korigirati veličinu fonta i oznaka na vizualizaciji ako želimo zadržati vrlo visoku rezoluciju. To ćemo napraviti sa argumentom base_size= unutar neke teme. Na primjeru pogledajmo ggsave() funkciju i mijenjanje veličine teksta na vizualizaciji kroz base_size argument.
Ovime smo spremili vizualizaciju u .jpg formatu u radni direktorij pod nazivom “plot_prvi.jpg”.
8.7 Zadaci
Zadatak 1
Kreirajte grafikon koji pokazuje prosječnu cijenu dijamanata (skup diamonds) prema boji (varijabla “color”). Napravite ga sa funkcijom geom_bar() i geom_col(). Koja je razlika između te dvije naredbe i koja je jednostavnija za potrebu ovog grafikona?
Kreirajte grafikon koji pokazuje ukupan broj dijamanata prema svakoj boji. Napravite ga sa funkcijom geom_bar() i geom_col(). Koja je razlika između te dvije naredbe i koja je jednostavnija za potrebu ovog grafikona?
Zadatak 2
Iz skupa diamonds kreirajte dijagram rasipanja koji prikazuje odnos između reza dijamanta (varijabla “cut”) i boje dijamanta (varijabla “color”). Je li ovaj grafikon informativan? Kojim tipom grafikona bi bolje ilustrirali vezu između reza i boje dijamanta?
Grafikon spremite u dva formata: jedan format neka bude JPG, a drugi PDF. Otvorite oba grafikona izvan R okruženja aplikacijom za pregled slika. Zumirajte grafikone. Uočavate li razliku u kvaliteti prikaza između JPG i PDF formata?
Zadatak 3
Iz skupa diamonds kreirajte dijagram rasipanja koji prikazuje odnos između veličine dijamanta i cijene dijamanta. Obojite točke ovisno o boji dijamanta. Koristeći funkciju facet_wrap() odvojite vizualizaciju po rezu dijamanta. Napišite hrvatske nazive za x i y os i kao izvor grafikona (caption) napišite vaše ime i prezime. Spremite grafikon u .jpg i .pdf formatima.
Možete li isti grafikon napraviti samo da je varijabla prema kojoj radimo facet varijabla “table” (ona prikazuje veličinu gornje, najveće plohe dijamanta gledajući ga od gore). Koji tip varijable je varijabla “table”? Zašto se facete ne rade za takvu vrstu varijable?
Healy, K. (2019). Data Visualization (a practical introduction) (1st edition). Princeton University Press.
Sjetimo se, potrošnja je izražena u američkim mjernim jedinicama mpg odnosno milja po galonu goriva pa niži mpg znači višu potrošnju goriva.↩︎