novcic <- c('Glava', 'Pismo')4.1 Opisna statistika
Opisna (deskriptivna) statistika je prvi korak u analizi varijabli rezultata istraživanja.
Opisna statistika uključuje niz statističkih parametara koji opisuju varijable. Kao prvi korak u prikazu podataka koriste se upravo parametri opisne statistike i slikovni prikazi raspodjela podataka.
Za potrebe opisne statistike biti će prikazani načini i mogućnosti različitih paketa poput psych (William Revelle, 2023), lessR (Gerbing, 2021) i DescTools (Andri et mult. al., 2022).
Razumijevanje opisne statistike nije moguće bez poznavanja osnova teorije vjerojatnosti. To posebno dolazi do izražaja kada opisujemo varijable pojedinim raspodjelama (engl. distribution). Parametri raspodjela izražavaju se pojmovima vjerojatnosti određenog rezultata ili ishoda varijable. Vjerojatnost je potrebno razumjeti u području kvantitativnih i kvalitativnih, kategorijskih varijabli.
Tema vjerojatnosti i uzorkovanja nezaobilazna je u razumijevanju statistike i podatkovne znanosti jer se uzorkovanje provodi na različitim vrstama varijabli, od diskretnih do kvantitativnih metričkih varijabli tj. od varijabli koje su na nominalnoj mjernoj ljestvici do varijabli koje su na omjernoj mjernoj ljestvici. U području kvalitativnih, kategorijskih ili diskretnih varijabli, još će biti riječi u poglavlju o kategorijskim varijablama.
Uz navedeno, pojmovi vjerojatnosti su neizbježni u temi uzorkovanja. Uzorak i uzorkovanje su teme koje se provlače kroz gotovo sva poglavlja analize i interpretacije rezultata nekog istraživanja. Suvremena istraživanja nisu moguća bez prikladne procjene veličine uzorka i snage istraživanja. Veličina uzorka i snaga istraživanja ograničavajući su čimbenik u procjeni stanja u populaciji temeljem istraživanja na uzorku. Posebno mjesto zauzimaju u temema procjena veličine uzorka i statistička snaga.
4.2 Vjerojatnost i uzorkovanje
Vjerojatnost se odnosi na određeni događaj ili ishod. Ishodi se mogu odrediti unutar diskretne i kontinuirane varijable uz određenu vjerojatnost. U eksperimentima sa moguća dva ili više odvojenih tj. diskretnih ishoda, tada govorimo o diskretnoj slučajnoj varijabli. Prema tome, diskretna slučajna varijabla može poprimiti konačni broj vrijednosti.
U vjerojatnosti ishoda izražavamo se pojmovima relativne frekvencije događaja ili ishoda te vjerojatnosti događaja. U razmatranju vjerojatnosti potrebno je uzeti i vrijednosti količine uzorkovanja i ponavljanja.
R jezik omogućava jednostavno simuliranje uzorkovanja i načina postavljanja vjerojatnosti ishoda ili događaja. U tu svrhu koristi se funkcija sample().
Kako bi simulirali bacanje novčića i tradicionalnog ishoda pismo/glava, napravit ćemo varijablu “novcic” tj. vektor sa dva ishoda.
Mogući ishodi varijable “novcic” su prvi argument, drugi argument je veličina uzorka i treći argument je način uzorkovanja sa ili bez povrata.
sample (novcic, 20, replace = TRUE) [1] "Glava" "Glava" "Pismo" "Pismo" "Glava" "Pismo" "Glava" "Glava" "Pismo"
[10] "Pismo" "Pismo" "Glava" "Glava" "Glava" "Pismo" "Glava" "Pismo" "Pismo"
[19] "Pismo" "Glava"U suvremenoj podatkovnoj znanosti je vrlo važno ponavljanje eksperimenata te je također moguće napraviti vrlo jednostavno i takvu simulaciju u R jeziku. Važno je primjetiti da zbog slučajnog uzorkovanja, u našem slučaju nećemo uvijek dobiti isti rezultat.
replicate(7, sample(novcic, 10, replace = TRUE)) [,1] [,2] [,3] [,4] [,5] [,6] [,7]
[1,] "Pismo" "Glava" "Pismo" "Pismo" "Glava" "Pismo" "Glava"
[2,] "Glava" "Pismo" "Glava" "Pismo" "Pismo" "Pismo" "Pismo"
[3,] "Pismo" "Glava" "Glava" "Pismo" "Glava" "Glava" "Pismo"
[4,] "Pismo" "Pismo" "Glava" "Pismo" "Pismo" "Glava" "Pismo"
[5,] "Glava" "Glava" "Glava" "Pismo" "Glava" "Pismo" "Glava"
[6,] "Pismo" "Pismo" "Glava" "Glava" "Pismo" "Glava" "Pismo"
[7,] "Glava" "Glava" "Pismo" "Pismo" "Glava" "Pismo" "Glava"
[8,] "Glava" "Pismo" "Glava" "Pismo" "Glava" "Pismo" "Pismo"
[9,] "Glava" "Glava" "Pismo" "Glava" "Glava" "Glava" "Pismo"
[10,] "Pismo" "Glava" "Glava" "Pismo" "Pismo" "Pismo" "Glava"Osim simulacije jednostavne vjerojatnosti, u znanstvenim istraživanjima je također važna i uvjetovana ili kondicionirana vjerojatnost tj. kada je određeni ishod ili događaj uvjetovan vjerojatnosti nekog drugog događaja ili u množini ishoda.
Kako bi razumjeli diskretne varijable, nužno je upoznati se s elementima raspodjele diskretnih varijabli.
4.2.1 Binomna raspodjela
Prikaz raspodjela mogućih ishoda diskretnih varijabli naziva se binomna raspodjela. Diskretna slučajna varijabla može poprimiti konačni broj vrijednosti. Između vrijednosti koje su u pravilu cjelobrojne vrijednosti nema dodatnih vrijednosti. Binomna raspodjela matematički te zatim slikovno, grafički opisuje sve moguće ishode binomne raspodjele.
Pokušajmo s primjerom. Zamislimo eksperiment sa 10 identičnih igraćih kocki. Ukoliko bacimo odjednom 10 kocki, kolika je vjerojatnost dobivanja dviju šestica?
dbinom(x = 2, size = 10, prob = 1/6)[1] 0.29071Ako bismo željeli odgovoriti na pitanje kolika je vjerojatnost dobivanja dviju šestica ako bacamo 10 kocaka 10 puta, možemo to napraviti i grafički. Dobivanje dviju šestica ćemo klasificirati kao “uspjeh”
uspjeh<-0:10
dbinom(uspjeh, size=10, prob=1/6) [1] 1.615056e-01 3.230112e-01 2.907100e-01 1.550454e-01 5.426588e-02
[6] 1.302381e-02 2.170635e-03 2.480726e-04 1.860544e-05 8.269086e-07
[11] 1.653817e-08plot(uspjeh, dbinom(uspjeh, size=10, prob=1/6),type='h')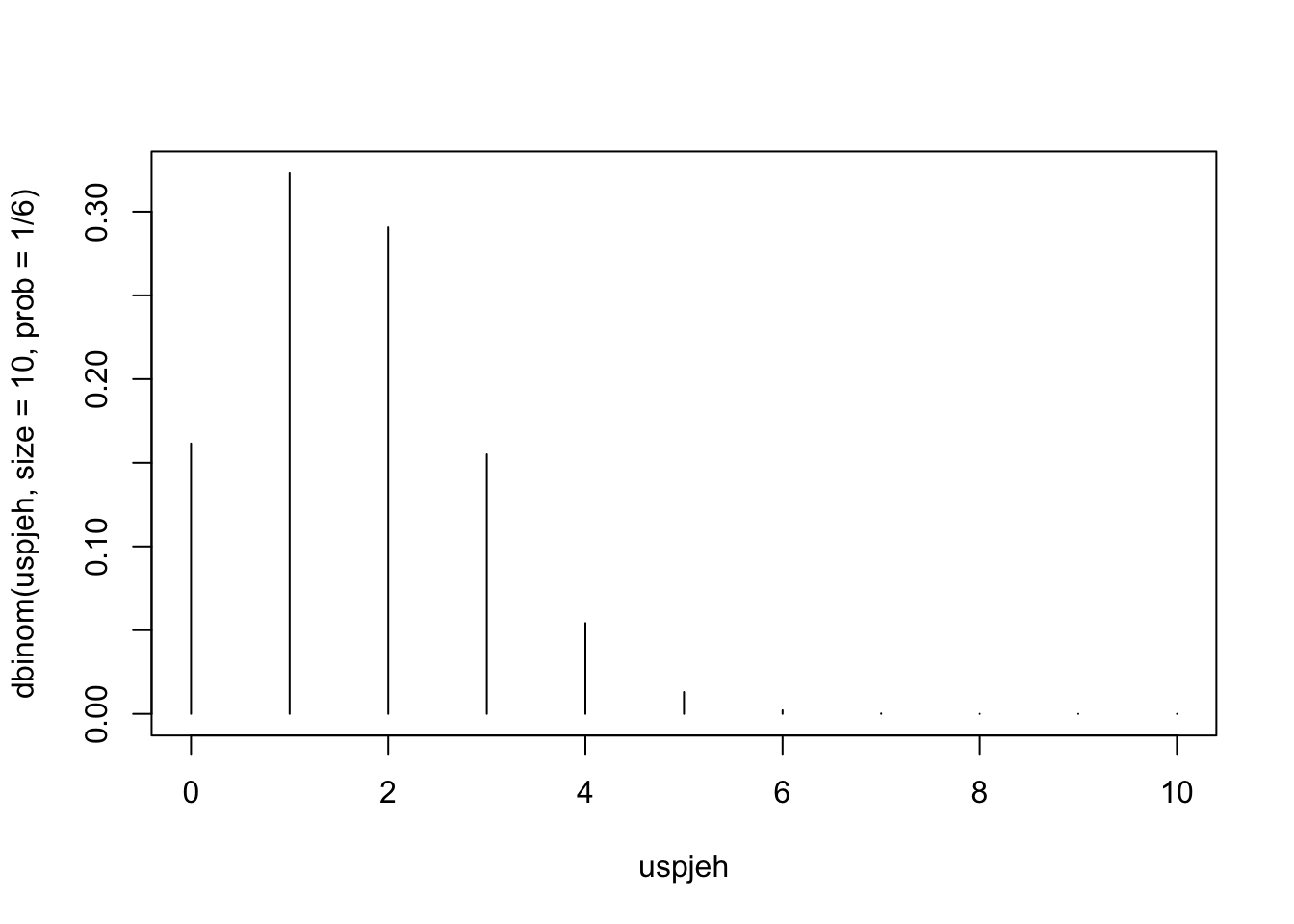
4.2.2 Poissonova raspodjela
Poissonova raspodjela među prvima je opisao francuski matematičar Simeon Denis Poisson (1781-1840). To je diskretna raspodjela događaja u određenom vremenu i prostoru. Ladislaus Josephovich Bortkiewicz (1868 - 1931) je ukazao na važnost Poissonove raspodjele u primjeni statistike u praksi. Iako je bio porijeklom poljak, zapamćen je kao ruski ekonomist i statističar. Napisao je prve knjige o važnosti primjene Poissonove raspodjele u primijenjenoj statistici.
Poissonova raspodjela je diskretna raspodjela vjerojatnosti izražena kao vjerojatnost broja događaja u određenom vremenu. Važno je naglasiti kako događaji nisu povezani tj. događaj je neovisan o prethodniku i mogućem slijedećem događaju. Primjera Poissonove raspodjele ima jako puno. Prateći promet na određenom mjestu ili križanju, možemo napraviti raspodjelu prolaska automobila u određenom zadanom vremenu. U suvremenom mrežnom okruženju, možemo napraviti raspodjelu posjeta određenoj mrežnoj stranici u zadanom vremenu.
APA rječnik navodi kako je to teorijska raspodjela koja služi za opisivanje diskretnih događaja koji su rijetki, kao što je slučaj s broj prestanka od pušenja, zatim raspodjela broja agresivnih oblika ponašanja na igralištu u određenom vremenu. Za izračun funkcije potrebno je poznavati prosječan broj događaja u određenom intervalu a što se označava s \(\lambda\) (lambda). Koristeći lambdu i traženi broj događaja, možemo pomoću funkcija dpois, ppois i rpois izračunati potrebne parametre.
Uzmimo primjer križanja u prometu. Recimo da određeno križanje u jednoj minuti prođe 20 automobila. Kolika je vjerojatnost da u jednoj minuti prođe 1 automobil?
ppois(1,lambda = 20)[1] 4.328423e-08Vjerojatnost prolaska samo jednog automobila u jednoj minuti je iznimno mala.
Kako možemo slikovno prikazati Poissonovu raspodjelu? U izradi trebamo koristiti funkciju dpois
Potrebno je objasniti što graf prikazuje… Raspodjelu vjerojatnosti prolaska jednog automobila. ili 20?
# prvo ćemo odrediti mogući raspon diskretnih događaja od 1 do recimo 50 automobila na križanju
broj_auto <- 1:50
# nakon određivanja raspona možemo napraviti slikovni prikaz
plot(broj_auto, dpois(broj_auto, lambda = 20), type='h')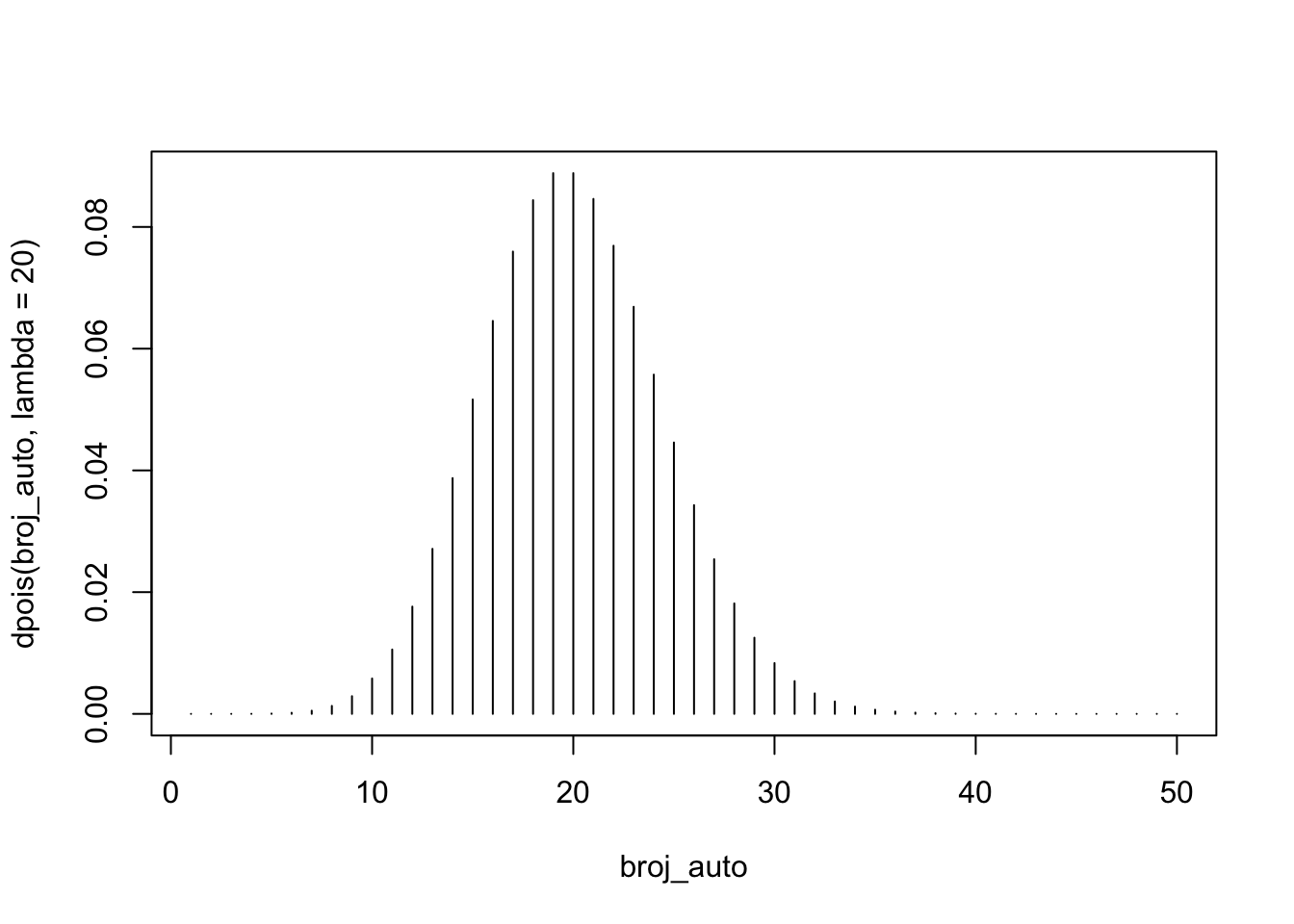
4.2.3 Normalna raspodjela
Kao što smo prethodno obradili binomnu i Poissonovu raspodjelu kod diskretnih varijabli, sada ćemo nešto više reći o raspodjeli koja se odnosi na kontinuirane, kvantitativna, metričke varijable i koja predstavlja temelj za razumijevanje mnogih testova inferencijalne, zaključne statistike. Normalna raspodjela je jedan od središnjih pojmova u primjeni statistike u znanosti. Normalna raspodjela vezana je uz pojam centralnog graničnog teorema (eng.: Central Limit Theorem) U R-u imamo nekoliko vrlo vrijednih načina prikaza rezultata istraživanja ili simulacije podataka. Za simulaciju rezultata istraživanja možemo prikazati normalnu raspodjelu pomoću funkcije rnorm.
### Histogramski prikaz simulacija rezultata istraživanja
### na 100 ispitanika (n=100), aritmetička sredina 100 i standardna devijacija 10
hist(rnorm(100, mean = 100, sd = 10),
main="Normalna raspodjela",
ylab="Frequencija rezultat",
xlab ="Hypothetski rezultat")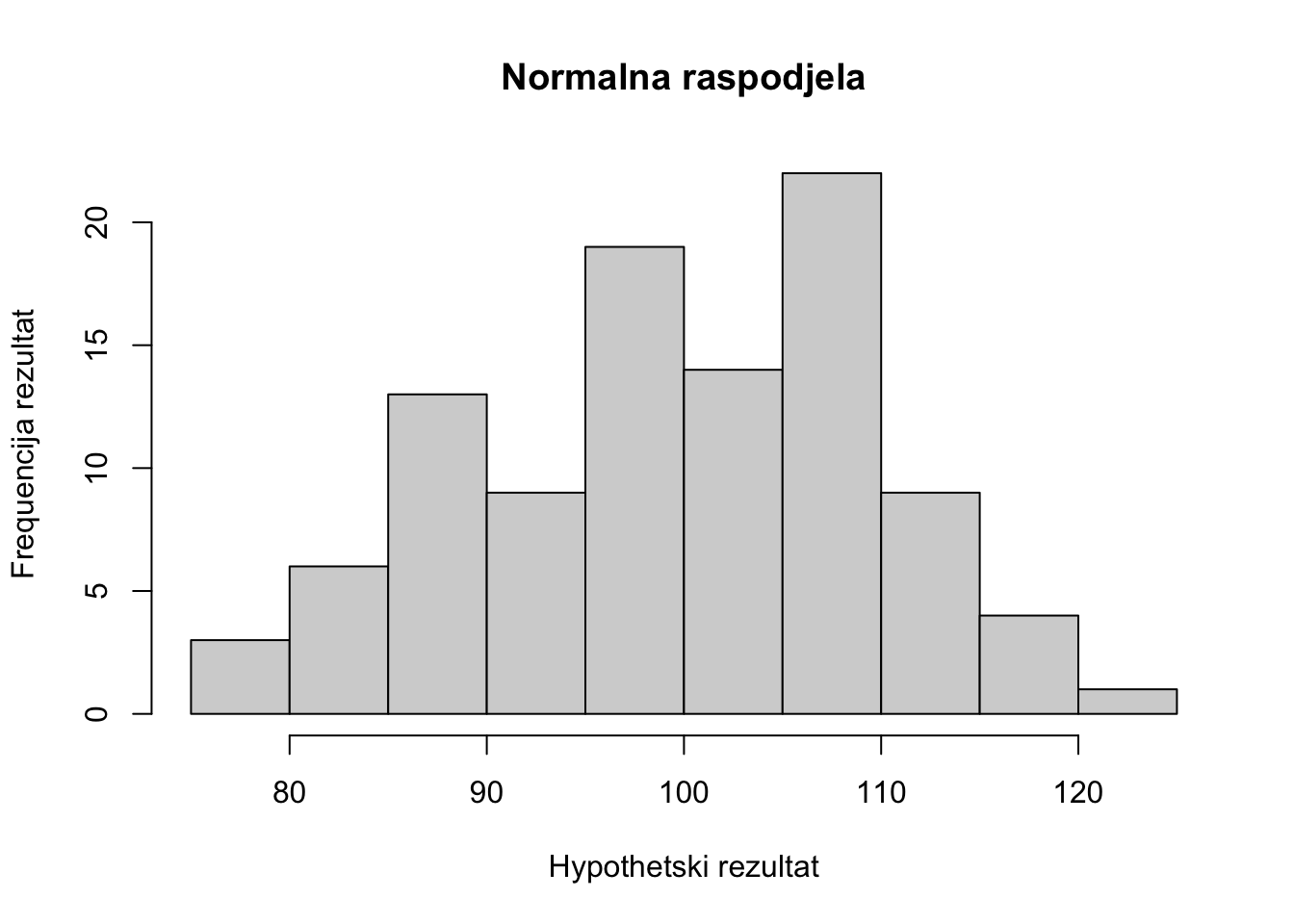
## kako se mijenja izgled raspodjele ovisno o broju ispitanika povećavajući
## broj ispitanika 10 puta
hist(rnorm(1000, mean = 100, sd = 10),
main="Normalna raspodjela",
ylab="Frequencija rezultat",
xlab ="Hypothetski rezultat")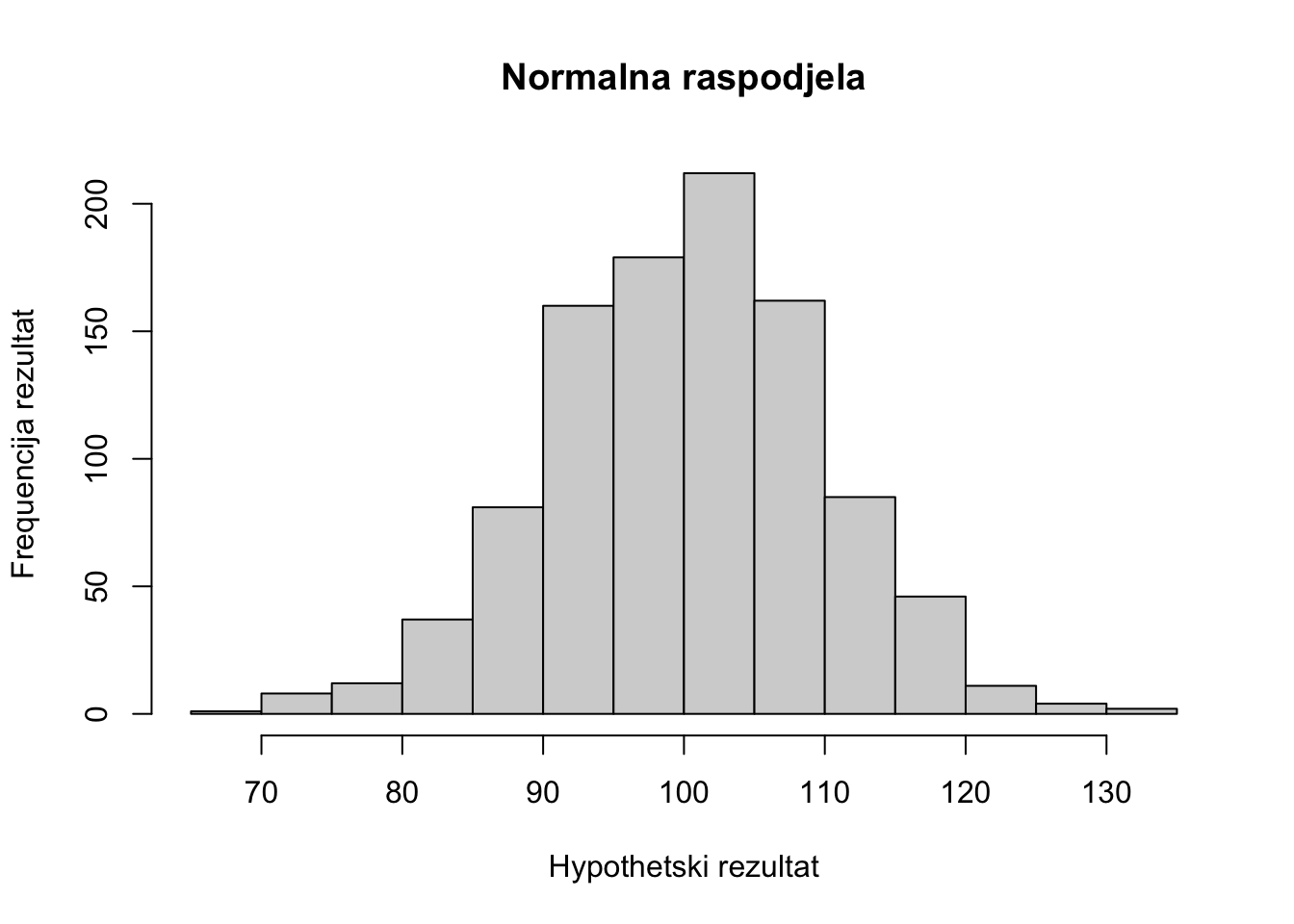
## povećavajući broj ispitanika 100 puta
hist(rnorm(10000, mean = 100, sd = 10),
main="Normalna raspodjela",
ylab="Frequencija rezultat",
xlab ="Hypothetski rezultat")
Iz navedenih primjera vidimo promjene oblika raspodjela mijenjanjem veličine uzorka.
4.3 Mjere centralne tendencije
Najčešće mjere centralne tendencije koje se koriste u praksi su:
aritmetička sredina (mean)
centralna vrijednost (medijan)
dominantna vrijednost (mod)
Rjeđe korištene su i:
geometrijska sredina
harmonična sredina
U ovom dijelu bit će opisani izračuni aritmetičke sredine, centralne vrijednosti i dominantne vrijednosti, dok se geometrijska sredina i harmonična sredina iznimno rijetko koriste u praksi.
Aritmetička sredina predstavlja zbroj svih vrijednosti podijeljen brojem (količina) vrijednosti. Pri korištenju aritmetičke sredine treba voditi računa o aritmetičkoj sredini populacije (\(\mu\)) i aritmetičkoj sredini uzorka (\(\bar{X}\)) što svakako nije isto. U praksi gotovo uvijek radimo s aritmetičkom sredinom uzorka koju označavamo s velikim slovom M ili (\(\bar{X}\)). Aritmetičku sredinu populacije u literaturi nazivamo i pravom aritmetičkom sredinom jer pri korištenju statističkih testova ili provjeri valjanosti hipoteza, aritmetičku sredinu populacije odmjeravamo ili procjenjujemo temeljem aritmetičke sredine uzorka.
Nekoliko je uvjeta za primjenu aritmetičke sredine:
Zahtjeva numeričke podatke i normalnu raspodjelu rezultata mjerenja.
Prikladnija mjera centralne tendencije za varijable na intervalnim i omjernim mjernim ljestvicama.
Prikladnija mjera centralne tendencije za veći uzorak (N>20) (obično navodimo 30).
Uz aritmetičku sredinu u pravilu se navodi standardna devijacija kao mjera varijabilnosti rezultata.
Prije uporabe i interpretacije svakako napraviti slikovni prikaz podataka dotične varijable.
Aritmetička sredina je jedna od mjera centralne tendencije koja se nekritički koristi u praksi tj. statističko metodološki problematično (Speelman & McGann, 2013). Najčešće greške ukjučuju rad s malim uzorcima ili izračun prosjeka kod podataka s manjim brojem ekstremnih vrijednosti.
Najjednostavnije korištenje aritmetičke sredine u R jeziku je uporabom funkcije mean(). Prilikom korištenja navedene funkcije valja znati i primjenu argumenta na.rm=TRUE što znači korištenje izračuna ignorirajući missing value. U slijedećem primjeru jednostavno možemo pridjeliti varijabli proba_x vrijednosti od 1 do 10 te izračunati aritmetičku sredinu.
proba_x <- c(1,2,3,4,5,6,7,8,9,10)
mean(proba_x)[1] 5.5Centralna vrijednost (C) nalazi se točno u sredini niza vrijednosti poredanih od najmanje prema najvećoj. Zahtjeva numeričke podatke. Računa se kada raspodjela (distribucija) rezultata mjerenja odstupa od normalne. Prikladna za manje uzorke čiji rezultati znatno odstupaju, variraju. Uz centralnu vrijednost kao mjeru centralne tendencije u pravilu se navodi absolutno odstupanje od medijana (MAD, median absolute distance) i/ili ukupni raspon (min, max, TR = max - min). Centralna vrijednost se izračunava pomoću funkcije median().
proba_y <- c(1,2,3,3,3,3,3,4,5,6,6,7,8,9,10)
median(proba_y)[1] 4Dominantna vrijednost (D) je vrijednost čija je učestalost najveća u odnosu na druge vrijednosti varijable. Računa se na učestalostima ili frekvencijama. Nije važna raspodjela podataka jer u tom slučaju normalna raspodjela ne postoji. U pravilu se koristi kada su varijable kvalitativne, kategorijske ili se nalaze na nominalnoj ili najviše ordinalnoj mjernoj ljestvici. U tom slučaju, ograničeni smo jer ne možemo korisiti aritmetičku sredinu ili medijan. Dominantna vrijednost pomoću funkcije nije uključena u base paket od R jezika, već trebamo dohvatiti paket modeest i koristiti funkciju mfv().
library(modeest)
mfv(proba_y)[1] 3Ukoliko želimo koristiti zbirni izvještaj deskriptivne statistike, tada može koristiti paket “psych”. U tom slučaju dobijemo niz vrijednosti deskriptivne statistike, u ovom slučaju varijable “proba_y” ili cijele datoteke s podatcima.
library(psych)Registered S3 method overwritten by 'psych':
method from
plot.residuals rmutildescribe(proba_y) vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 15 4.87 2.7 4 4.77 2.97 1 10 9 0.46 -1.16 0.7Naravno, moguće je dobiti i izračun za cijeli skup podataka.
library(psych)
describe(sat.act) #primjer datoteke ugrađene u paket psych za demonstraciju vars n mean sd median trimmed mad min max range skew
gender 1 700 1.65 0.48 2 1.68 0.00 1 2 1 -0.61
education 2 700 3.16 1.43 3 3.31 1.48 0 5 5 -0.68
age 3 700 25.59 9.50 22 23.86 5.93 13 65 52 1.64
ACT 4 700 28.55 4.82 29 28.84 4.45 3 36 33 -0.66
SATV 5 700 612.23 112.90 620 619.45 118.61 200 800 600 -0.64
SATQ 6 687 610.22 115.64 620 617.25 118.61 200 800 600 -0.59
kurtosis se
gender -1.62 0.02
education -0.07 0.05
age 2.42 0.36
ACT 0.53 0.18
SATV 0.33 4.27
SATQ -0.02 4.41Ukoliko želimo napraviti nešto ljepšu tablicu, možemo to napraviti pomoću paketa kableExtra (Zhu, 2021). Pomoću argumenta format možemo promijeniti izgled tablice.
library(kableExtra)
dobra_tbl <- describe(sat.act)
kable(dobra_tbl, digits = 2, format = "pipe")| vars | n | mean | sd | median | trimmed | mad | min | max | range | skew | kurtosis | se | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| gender | 1 | 700 | 1.65 | 0.48 | 2 | 1.68 | 0.00 | 1 | 2 | 1 | -0.61 | -1.62 | 0.02 |
| education | 2 | 700 | 3.16 | 1.43 | 3 | 3.31 | 1.48 | 0 | 5 | 5 | -0.68 | -0.07 | 0.05 |
| age | 3 | 700 | 25.59 | 9.50 | 22 | 23.86 | 5.93 | 13 | 65 | 52 | 1.64 | 2.42 | 0.36 |
| ACT | 4 | 700 | 28.55 | 4.82 | 29 | 28.84 | 4.45 | 3 | 36 | 33 | -0.66 | 0.53 | 0.18 |
| SATV | 5 | 700 | 612.23 | 112.90 | 620 | 619.45 | 118.61 | 200 | 800 | 600 | -0.64 | 0.33 | 4.27 |
| SATQ | 6 | 687 | 610.22 | 115.64 | 620 | 617.25 | 118.61 | 200 | 800 | 600 | -0.59 | -0.02 | 4.41 |
4.4 Mjere varijabilnosti, odstupanja
U praksi se koristi niz vrijednosti mjera varijabilnost kao što su:
ukupni (totalni) raspona,
koeficijent varijacije
absolutna udaljenost od medijana (MAD),
standardna devijacija (SD),
varijanca.
Uz aritmetičku sredinu u pravilu se koristi standardna devijacija.
\[\sigma = \sqrt{\frac{\sum\limits_{i=1}^{n} \left(x_{i} - \bar{x}\right)^{2}} {n-1}}\]
Mjera raspršenja podataka čija je raspodjela / distribucija normalna. Standardna devijacija pokazuje koliko se gusto rezultati grupiraju oko aritmetičke sredine. Manja standardna devijacija može pokazati sličnost između podataka ili manju varijaciju varijable koju mjerimo. S druge strane, veće raspršenje ukazuje na različitost rezultata ili veću varijabilnost pojave. Naredba za izračun je sd(). Uzmimo u obzir da je u nekoj disribuciji prosjek 100, a standardna devijacija 20. U svakoj normalnoj distribuciji, sa jednom standardnom devijacijom s obje strane distribucije zahvaćamo približno 68% rezultata, dakle od rezultata 80 do 120. Sa dvije standardne devijacije ćemo zahvatiti približno 95% rezultata.
Kvadrat standardne devijacije je varijanca, koja predstavlja prosječno kvadratno odstupanje rezultata od aritmetičke sredine.
Koeficijent varijacije (CV) je standardna devijacija izražena u postocima od aritmetičke sredine.
Totalni raspon se računa kao razlika između najvećeg i najmanjeg broja u skupu podataka, te se često prikazuje uz mod i medijan.
Absolutna udaljenost od medijana (MAD) se računa na sličnom tragu kao i standardna devijacija, na način da se uzmu apsolutne razlike svakog pojedinog rezultata od medijana, zbroje se i podijele s ukupnim brojem rezultata.
4.4.1 Procjene simetričnosti
Kod potpuno simetrične raspodjele, aritmetička sredina, centralna vrijednost i dominantna vrijednost su jednake vrijednosti. Ukoliko raspodjela rezultata odstupa od normalne, tada su navedene mjere centralne tendencije različite vrijednosti.
Skewness je mjera asimetričnosti te ukoliko je ta vrijednost veća od -1 ili +1 tada možemo reći kako je raspodjela jako asimetrična. Ukoliko je vrijednost između -0.5 i 1 te između +0.5 i 1 tada kažemo kako je raspodjela umjereno asimetrična. Konačno, ako je vrijednost u rasponu između -0.5 i 0.5, dakle oko nula, tada možemo reći kako navedena raspodjela je približno normalna.
U slijedećem primjeru možemo jednostavno simulirati simetričnosti i odnose prema mjerama centralne tendencije. Varijablama proba_x, proba_y i proba_z dodijelimo niz vrijednosti kako slijedi i promotrimo što se događa sa vrijednosti skewness i kurtosis pomoću paketa psych i funkcije describe().
library(psych)
proba_x <- c(1,2,3,4,5,6,7,8,9,10)
describe(proba_x) vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 10 5.5 3.03 5.5 5.5 3.71 1 10 9 0 -1.56 0.96proba_y <- c(1,2,3,4,5,6,7,8,9,15)
describe(proba_y) vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 10 6 4.08 5.5 5.5 3.71 1 15 14 0.79 -0.25 1.29proba_z <- c(1,5,6,7,8,9,10,11,12,13)
describe(proba_z) vars n mean sd median trimmed mad min max range skew kurtosis se
X1 1 10 8.2 3.61 8.5 8.5 3.71 1 13 12 -0.48 -0.87 1.14Vrijednost kurtosis pokazuje u kojoj mjeri je raspodjela platikurtična ili leptokurtična. Ukoliko je vrijednost kurtosis ispod 3, tada je riječ o raspodjeli koja je u manjoj ili većoj mjeri spljoštenija tj. platikurtična. Vrijednost oko 3 podrazumijeva kako je raspodjela slična teorijskoj normalnoj raspodjeli.
4.4.2 Položaj i vjerojatnosti rezultata u normalnoj raspodjeli
R ima niz funkcija koje omogućavaju kvalitetno prikazivanje raspodjela te površina, vjerojatnosti i vrijednosti pojedinih rezultata.
Tako funkcija pnorm() omogućava izračun površine i vjerojatnosti iznad određene vrijednosti normalne raspodjele. Ako zamislimo normalnu raspodjelu koeficijenata inteligencije (IQ) čija je aritmetička sredina 100 i devijacija 10, koliko je vjerojatno u slučajnom odabiru dobiti vrijednost manju od 110.
pnorm(110,mean=100,sd=10)[1] 0.8413447U gornjem slučaju vidimo da je vjerojatnost da se dobije vrijednost manja od 110 oko 84%. Važno je naglasiti da ova funkcija vrijedi samo za
Funkcija qnorm() izračunava obrnuto tj. koja je vrijednost u određenom percentilu normalne raspodjele. Tako npr. iz prethodnog primjera, koja vrijednost IQ pada točno na 80. percentil?
qnorm(0.80,mean=100,sd=10)[1] 108.4162Kako izgleda raspodjela kvocijenta inteligencije u histogramskom prikazu i interpolaciji normalne krivulje u prethodnom primjeru na 1000 ispitanika.
x <- rnorm(1000, mean=100, sd=10)
hist(x, probability=TRUE,
main = "Normalna raspodjela",
xlab="Rezultat")
xy <- seq(min(x), max(x), length=100)
lines(xy, dnorm(xy, mean=100, sd=10))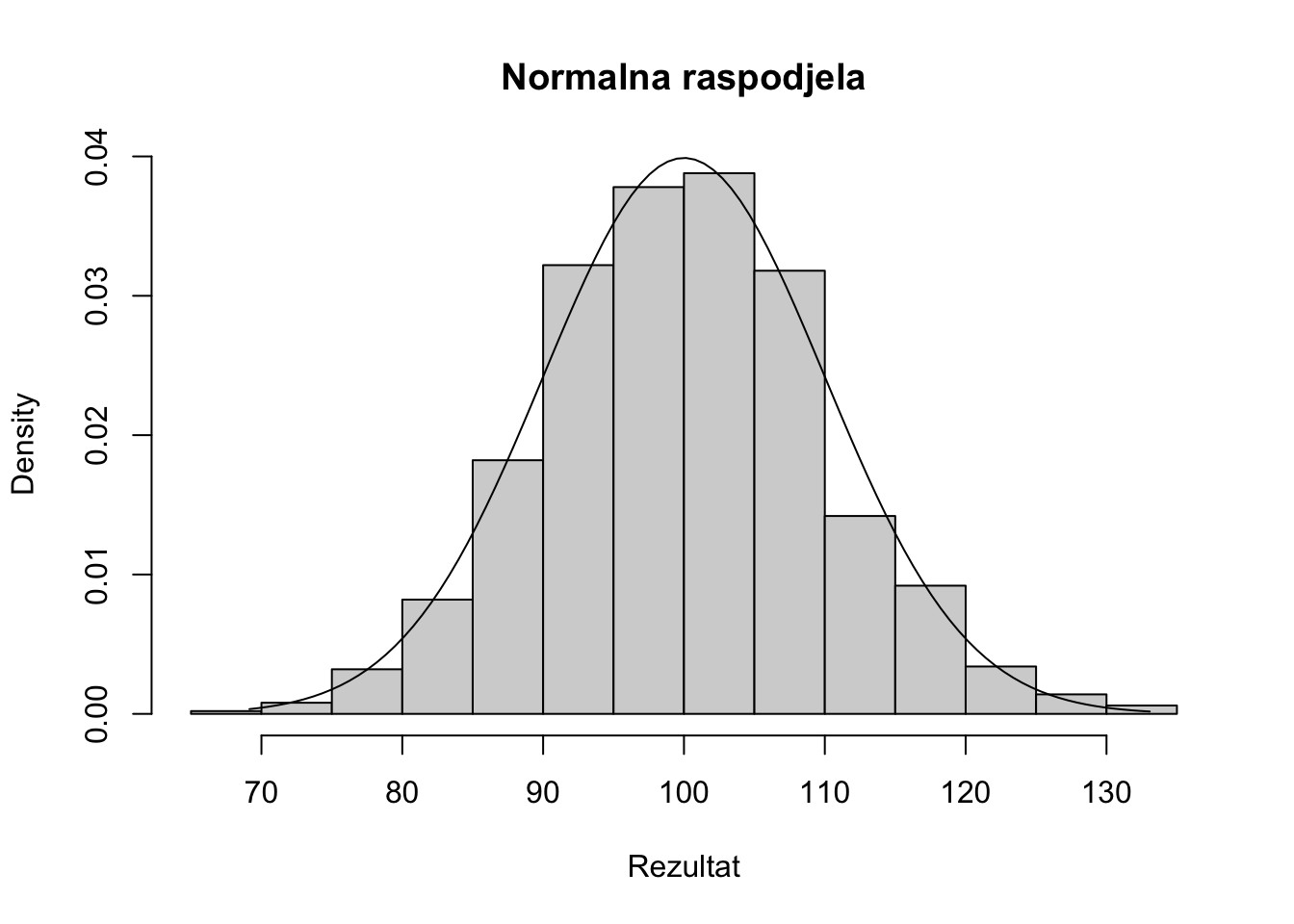
4.4.3 Centili, decili
Centile često koristimo za izražavanje položaja pojedinog rezultata neke varijable. Centili i decili ne zahtijevaju normalnu raspodjelu. Na neki način, možemo reći kako su centili i decili mjere položaja pojedinog rezultata u području neparametrijske statistike. Centili predstavljaju relativni rang. Centile i decile ne možemo zbrajati kao što je to slučaj kod z vrijednosti.
U R jeziku imamo ugrađenu funkciju quantile() koja omogućava rad sa centilima.
Pretpostavimo u jednom primjeru mjerenje tjelesne težine na uzorku od 20 studentica.
tjelesna_tezina <- c(57, 54, 48, 63, 67, 62, 50, 73, 48, 51,
60, 70, 66, 62, 76, 59, 61, 55, 53, 71)
quantile(tjelesna_tezina) 0% 25% 50% 75% 100%
48.00 53.75 60.50 66.25 76.00 Korištenjem funkcije quantile bez pojedinih parametara unutar funkcije vrlo jednostavno dobivamo granice pojedinih kvartila za određeni raspon vrijednosti. Korištenjem funkcija možemo dobiti konkretne informacije za pojedinu vrijednost. U sljedećem koraku možemo dobiti granice raspodjela za pojedine decile.
quantile(tjelesna_tezina, prob = seq(0, 1, length = 11), type = 5) 0% 10% 20% 30% 40% 50% 60% 70% 80% 90% 100%
48.0 49.0 52.0 54.5 58.0 60.5 62.0 64.5 68.5 72.0 76.0 Dok, na istim podacima možemo dobiti granice npr. 35, 65 i 75 centil.
quantile(tjelesna_tezina, prob = c(0.35, 0.65, 0.75)) 35% 65% 75%
56.30 62.35 66.25 4.4.4 Z vrijednosti
Z-vrijednosti predstavljaju položaj pojedinačnog rezultata varijable. Z vrijednost se izražava u dijelovima standardne devijacije a što je jasno vidljivo i proizlazi iz formule.
Ovaj dio nije napisan u R-u, ili mi se barem tako čini.
\[\begin{equation} z=\frac{(x - \bar{X})}{SD} (\#eq:z) \end{equation}\]Uz pomoć z-vrijednosti a koja se zasniva na standardnoj devijaciji mogu se ispravno uspoređivati rezultati što su ih ispitanici postigli u dva ili više testova.
Pri uporabi z vrijednosti treba imati na umu;
Aritmetička sredina i standardna devijacija definiraju normalnu raspodjelu. Prema tome, treba voditi računa pri uporabi z vrijednosti sva ograničenja i mogućnosti interpretacije normalne raspodjele i uporabe aritmetičke sredine i standardne devijacije
Treba nam informacija gdje je podatak ili rezultat u nizu
Možemo izračunati koliko je ispod a koliko iznad određene vrijednosti
U slučaju ‘kompozitnog’ rezultata – z vrijednosti omogućavaju ZBRAJANJE i ODUZIMANJE!
Moguće je uspoređivati rezultate mjerenja koji su dobiveni različitim mjerama (krivo mišljenje – usporedba apsolutnih vrijednosti!, na vrijednost utječe aritmetička sredina i standardna devijacija)
Ukoliko ‘pješke’ računamo z vrijednosti, tada pomoću tablice možemo izračunati površinu normalne raspodjele. Inače, pomoću funkcija na računalu možemo odrediti veličinu površine koja je ujedno i vjerojatnost.
U odnosu na druge koeficijente koji se upotrebljavaju za izražavanje položaja rezultata, z vrijednosti imaju neke prednosti;
Z vrijednosti možemo zbrajati i dobivati prosjek – centile NE
Centili nisu ekvidistantne jedinice (nije jednak razmak između jedinica)
Kod uporabe centila i decila nema smisla koristiti decimalna mjesta, uporaba z – vrijednosti omogućava korištenje više decimalnih mjesta (preporučljivo 2)
Prednost centila, decila – ne treba biti normalna raspodjela. Z vrijednosti su vezane za normalnu raspodjelu.
Z vrijednosti u R jeziku možemo napraviti na sljedeći način:
zproba_x <- (proba_x-mean(proba_x))/sd(proba_x)
zproba_x [1] -1.4863011 -1.1560120 -0.8257228 -0.4954337 -0.1651446 0.1651446
[7] 0.4954337 0.8257228 1.1560120 1.48630114.4.4.1 Zadatci: Opisna statistika
- Napravite niz brojeva od 80 do 100, nazovite ga NoviNiz, te mu odredite prosječnu vrijednost.
- Napravite niz brojeva od 150 do 1000, nazovite ga NoviNiz, te mu odredite prosječnu vrijednost i standardnu devijaciju.
- Napravite niz brojeva od 50 do 500, ali svaki treći broj. Nazovite ga Noviniz2 te tom skupu brojeva odredite aritmetičku sredinu i standardnu devijaciju.
2.a Napravite skup podataka koji u sebi sadrži podatke o deset osoba. Prema spolu su redom prvo muškarac pa žena od prvog do desetog. Visine osoba su redom: 181,183,176,166,189,183,183,176,172,179. Napravite izračun aritmetičke sredine i standardne devijacije prema spolu.
2.b Istraživali smo brzinu reakcije kod deset osoba u sekundama, uspoređujući lijevu i desnu ruku. Prema redoslijedu je prvo išla lijeva ruka, pa desna pa lijeva, itd. Brzine reakcije su bile redom: 50 61 56 58 52 59 65 66 67 68 68 52 52 67 62 66 58 65 62 55. Izračunajte aritmetičku sredinu posebno za lijevu i posebno za desnu ruku.
3.a U nekom razredu smo izmjerili težinu djece i ona je iznosila redom: 45, 29, 33, 50, 41, 46, 37,39, 46, 30,40, 31.
Koliko iznosi prosjek ovog skupa i standardna devijacija?
Koliko iznosi prosjek i standardna devijacija ovog skupa kada se iz njega maknu najveća i najniža vrijednost?
3.b Mjerili smo rezultate na upitniku političkih stavova gdje veći rezultati pokazuju intenzivnije političke stavove. Postojale su tri skupine po deset ispitanika: lijevi, desni i centar, te su prikazani i njihovi rezultati. Vaš zadatak je za svaku skupinu izračunati aritmetičku sredinu i standardnu devijaciju te opisati tko je imao najintenzivnije stavove, a tko najmanje intenzivne. Za varijablu političko opredjeljenje redom idu prvo lijevi, pa desni pa centar, pa lijevi i tako sve do 30-og ispitanika. Rezultati: 35 53 45 39 52 34 55 54 31 47 58 54 46 44 37 52 40 36 30 40 56 54 54 33 30 56 50 47 41 30.
4.a Zamislite da ste mjerili rezultat na nekom ispitu na 10000 osoba. Prosječna vrijednost iznosi 130, a standardna devijacija rezultata 10. Rezultati su normalno distribuirani.
između kojih rezultata se nalzi 68% rezultata
između kojih rezultata se nalazi 95% rezultata
između kojih rezultata se nalazi 99.7% rezultata
4.b Ako imamo neku mjerili smo brzinu otkucaja srca u općoj populaciji i bila je normalno distribuirana. Aritmetička sredina je iznosila 80 otkucaja u minuti, a standardna devijacija 10. Izračunajte: a) u kojem rasponu se nalazi 68% populacije b) u kojem rasponu se nalazi 95% populacije c) u kojem rasponu se nalazi 99% populacije d) ukoliko osoba ima 40 otkucaja srca u minuti, postoji li vjerojatnost da ta osoba ima problem sa srcem, prema Vama?
5.a U carData skupu podataka s nazivom: KosteckiDillon napravite izračun varijabli age , time, dos i airq, zasebno prema sljedećim faktorima: sex, hatype, headache. Opis varijabli se nalazi na: https://www.rdocumentation.org/packages/car/versions/2.1-6/topics/KosteckiDillon
5.b U carData paketu otvorite skup podataka Davis (https://www.rdocumentation.org/packages/carData/versions/3.0-4/topics/Davis). Izračunajte prema varijabli sex izračunajte aritmetičku sredinu za weight, height, repwt, repht. Napišite svoje zaključke tih usporedbi.
6.a U sljedećem skupu podataka izračunajte: 1) Aritmetičku sredinu i standardnu devijaciju 2) Izračunajte medijan i interkvartilno raspršenje 3) Izračunajte mod, minimum i maksimum.
67 85 87 54 41 78 16 70 25 58 10 64 78 67 84 6 92 84 24 77 51 58 18 56 69 92 12 58
Koju biste vrijednost odabrali za prikaz rezultata i zašto?
6.b Svakoj vrijednosti u skupu dodajte 1, te zatim na tom novom skupu izračunajte aritmetičku sredinu, standardnu devijaciju, interkvartilno raspršenje i medijan. Komentirajte rezultate.
6.c Za svaki broj u nizu izvucite drugi korijen (naredba sqrt()), te zatim na tom novom nizu izračunajte aritmetičku sredinu, standardnu devijaciju, medijan i interkvartilno raspršenje.
7.a U sljedećem skupu podataka izračunajte: 1) Aritmetičku sredinu i standardnu devijaciju 2) Medijan i interkvartilno raspršenje 3) Mod, minimum i maksimum.
93 88 101 90 64 85 79 82 80 72 78 106 53 75 92 69 73 73 72 89 96 87 42 83 129 67 89 94 84 92 57 56 85 54 67 94 85 114 98 99 89 53 74 71 55 61 108 105 104 117
Koju biste vrijednost odabrali za prikaz rezultata i zašto?
7.b Svakoj vrijednosti u skupu oduzmite 10, te zatim na tom novom skupu izračunajte aritmetičku sredinu, standardnu devijaciju, interkvartilno raspršenje i medijan. Komentirajte rezultate.
7.c Svaki broj u nizu kvadrirajte, te zatim na tom novom nizu izračunajte aritmetičku sredinu, standardnu devijaciju, medijan i interkvartilno raspršenje.
8.a Otvorite skup podataka koji se nalazi u carData pod nazivom “salaries” (https://www.rdocumentation.org/packages/carData/versions/3.0-4/topics/Salaries). Izračunajte aritmetičku sredinu i medijan s pripadajućim mjerama raspršenja te interpretirajte rezultate. Usporedite varijablu “salaries” prema varijablama “rank”, “discipline” i “sex”.
8.b Otvorite skup podataka koji se nalazi u carData pod nazivom “BEPS” (https://www.rdocumentation.org/packages/carData/versions/3.0-4/topics/BEPS). Izračunajte aritmetičku sredinu i medijan s pripadajućim mjerama raspršenja te interpretirajte rezultate. Usporedite varijablu “political knowledge” prema varijablama “vote” i “gender”.
9.a Procijenjivali smo smrtnost od COVID-a u različitim gradovima u Hrvatskoj: Pula, Rijeka, Zagreb, Split, Osijek, Krapina, Sinj, Dubrovnik. Broj smrtnih slčučajeva prema gradovima je bio sljedeći: 13,22,56,34,21,11,9,8. Napravite tablicu apsolutnih i relativnih frekvencija, te kumulativnih i kumulativnih relativnih frekvencija. Interpretirajte nalaze.
9.b Procijenjivali smo spremnost na sudjelovanje u istraživanjima ovisno o studijskom programu: Na Sociologiji je 17 studenata izjavilo spremnost, na Psihologiji 15, na Medicini 43, na Ekonomiji 25, te na Pravu 8. Napravite tablicu apsolutnih i relativnih frekvencija, te kumulativnih i kumulativnih relativnih frekvencija. Interpretirajte nalaze.
10.a U paketu carData skupu podataka pod nazivom KosteckiDillon napravite tablice apsolutnih i relativnih frekvencija za sljedeće varijable: 1) Hatype 2) Medication. Interpretirajte nalaze.
10.b U paketu carData skupu podataka pod nazivom Moore (https://www.rdocumentation.org/packages/carData/versions/3.0-4/topics/Moore) napravite tablice apsolutnih i relativnih frekvencija za sljedeće varijable: 1) Partner status 2) F category.
Interpretirajte nalaze.