20*63.1 Osnovne naredbe i sintaksa
R koristimo za čitav niz različitih vrsta operacija i analiza: od običnog kalkulatora do složenih simulacija različitih kompleksnih sustava. R kao i svaki drugi programski jezik koristi određeni “rječnik” kojeg razumije, a taj “rječnik” nazivamo sintaksa programskog jezika. RStudio s druge strane služi kao jednostavno vizualno sučelje koje korisnik koristi u radu. “Riječi” odnosno naredbe koje pišemo kada radimo u programskom jeziku zovemo kod.
Uobičajen algoritam rada u R-u sastoji se od pisanja koda, pokretanja koda i evaluacije dobivenih rezultata kodiranja. Kada prvi put otvorimo RStudio prikazat će nam se okvir naziva console. Ovaj okvir može služiti za pisanje koda i pokretanje koda.
Ilustrirajmo kako možemo pisati i pokretati kod u konzoli. Upišimo sljedeći kod (sjetimo se da R možemo koristiti i kao običan kalkulator) i pokrenimo ga sa tipkom enter.
Odmah ispod upisanog koda dobijemo rezultat upisanog koda: 120.
[1] 120U nastavku udžbenika, nakon oznake uglatih zagrada [ ] bit će navedeni rezultati pokrenutog koda prikazani u konzoli, a unutar uglatih zagrada pisat će brojka redaka rezultata, primjerice [1].
Naravno, R razumije sve matematičke operacije, a nama kao krajnjem korisniku potrebno je jedino naučiti sintaksu kako željenu operaciju pretvoriti u kod koji R jezik razumije.
(4*5+10)/2[1] 15cos(pi*2)/0.5[1] 2Kada provedemo nekoliko različitih operacija u konzoli, vidimo da se ona jako brzo popuni informacijama i postane nepregledna. Naš rad također rijetko kad obavimo u jednoj sesiji, već ga dopunjavamo i korigiramo više puta tijekom dana, tjedana i mjeseci. Ono što napišemo u konzoli ne sprema se u dugotrajnu memoriju računala. Zato u RStudiu postoji okvir source koji primarno služi za pisanje koda. “Običan” kod u RStudiu pišemo u R skripti. Napravimo novu R skriptu sa File -> New File -> R Script.
Skripta je datoteka koju spremamo na računalo isto kao i druge datoteke samo u svom posebnom formatu (format R skripte je .r). Sve što u njoj napišemo (redovito sačuvajte promjene sa Ctrl + S ili klikom na oznaku Save u traci okvira source), ostaje nam spremno za buduću sesiju u RStudiu. Kod napisan u skripti pokrećemo nešto drugačije nego li u konzoli. U skripti kod pokrećemo tako da označimo mišem koji kod želimo pokrenuti i kliknemo kombinaciju Enter + Ctrl ili sa tipkom Run iz gornjeg desnog kuta našeg source okvira.
Kod pišemo u linijama koda, a svaka linija je označena rednim brojem sa lijeve strane. Stoga nije nužno da pri pokretanju koda iz skripte označimo mišem sav kod koji želimo pokrenuti već je dovoljno da kursor bude bilo gdje u liniji koda koju želimo pokrenuti. Dakle, kod pišemo u okviru source i spremamo ga kao R skriptu koju možemo ponovno učitati bilo kada i pokretati kod iz nje. Kod se pokreće u okviru console i tamo vidimo rezultate našeg koda i, vrlo često, greške. O greškama ćemo nešto kasnije, ali valja imati na umu da su one sastavni dio kodiranja i da se najiskusniji programeri svakodnevno susreću sa raznim vrstama grešaka.
R ćemo naravno koristiti za mnogo složenije operacije od samog kalkulatora. Zato u kratkotrajnu memoriju pojedine R sesije spremamo objekte koje koristimo. Za spremanje objekata koristimo oznaku <-.
No, uvijek uz naredbu za spremanje objekata moramo dati i ime objektu. Neka prvi primjer bude objekt naziva “x” koji je rezultat jednostavne matematičke operacije 2+5.
x <- 2 + 5Sada nam je objekt “x” spremljen u kratkoročnu memoriju (dok nam je upaljena trenutačna RStudio sesija). On nam je sad vidljiv u okviru Environment. U tom okviru bit će navedeni svi objekti koje smo tijekom trenutačne sesije kreirali i spremili s oznaku <-. Alternativno, umjesto oznake <- može se koristiti =, no u nastavku ove knjige koristit će se osnovna oznaka <- .
Objekt koji je spremljen možemo pozivati imenom i nad njim raditi druge operacije i transformacije. Primjerice, objekt x uvećajmo za 3.
x+3[1] 103.2 Kako (ne)nazvati objekte?
Komentari unutar koda označeni su sa # odnosno znakom za hashtag. Komentare možete pisati i unutar vašeg koda te oni neće biti pokrenuti. Preporuka je da vaš kod logički odvojite i strukturirate sa komentarima tako da i nakon pauze od više mjeseci možete lakše prepoznati logiku i slijed vaše R skripte. Jasno strukturiran i komentiran kod značajno doprinosi kvaliteti koda, posebno ako će više korisnika koristiti isti kod ili će on biti javno objavljen.
U svakodnevnom radu često kreiramo nove objekte koje trebamo imenovati. Iako većinu njih nećemo izvesti u neki drugi format, važno je držati se nekih pravila o nazivanju objekata. Glavna ideja kod davanja naziva objektu je da naziv opisuje objekt odnosno da ima nekakvu logičku opisnu poveznicu. Primjerice, ako spremamo nekakav objekt koji sadrži informacije o prosječnim ocjenama učenika na kraju školske godine onda ćemo taj objekt nazvati tako da nas asocira na njegov sadržaj. Tako naziv tog objekta može biti “ocjene”, “prosjeci”, “grades” ili bilo što drugo što nas asocira na prosječne ocjene učenika na kraju školske godine. Preporuka je koristiti specifične nazive, te svako mijenjanje objekta nazvati s novim nazivom, da se ne izgube prethodne informacije te da ne dođe do miješanja naziva.
Osim same ideje da naziv ima deskriptivnu vrijednost, R ima i neka pravila kod davanja naziva. Naziv objekta mora počinjati sa slovom. Naziv može sadržavati samo slova, slova i brojeve, točku . i donju crtu _. Kada imamo više objekata koji su slični, recimo objekt koji sadrži prosječne ocjene učenika i objekt koji sadrži medijalne ocjene učenika, potrebno je nazvati ih nešto detaljnije pa ćemo koristiti dvije ili više riječi u nazivu. Vodeći se osnovnim pravilima o nazivima, možemo objekt o prosječnim ocjenama učenika nazvati na beskonačno načina. Evo nekoliko primjera:
prosjecne_ocjene_ucenika
ProsjecneOcjeneUcenika
prosjecne.ocjene.ucenika
prosjecneocjeneucenika
PROSJECNEocjeneUCENIKA
Prosjecne_ocjene.ucenikaPrve tri varijante su konvencionalni način imenovanja objekata u R jeziku (i u drugim programskim jezicima) i podrazumijevaju razdvajanje riječi pomoću donje crte (_), točke (.) ili velikog slova na početku nove riječi. Posljednje tri varijante su također legitimne jer poštuju osnovna pravila o nazivanju, ali su manje pregledna i jasna, pogotovo kada u nekoj sesiji imamo desetke različitih objekata.
Preporučujemo da odaberete jedan od prva tri stila i da ga se držite tijekom cijele R skripte.
R je case sensitive odnosno razlikuje velika i mala slova. Ukoliko smo objekt nazvali “x_faktor”, a kasnije pozvali “x_Faktor” dobit ćemo grešku. Pregled spremljenog objekta napravit ćemo tako da napišemo njegovo ime i pokrenemo kod u toj liniji. Primjer:
x_faktor <- 5*3
x_faktor[1] 15Iako nije suprotno osnovnim pravilima pri davanju naziva, preporučamo da u nazivima ne koristite dijakritičke znakove (č,ć,š,đ,ž), a pogotovo ne kao prvo slovo u nazivu. Iako će na vašem računalu možda sve biti u redu, neko drugo računalo na kojem ćete pokrenuti kod ili će vaš suradnik na istraživanju/projektu/radu pokretati vaš kod, možda će imati sustav sa drugačijim encodingom, jezičnim postavkama ili postavkama za unos teksta te takve znakove neće čitati i vaš kod će biti neupotrebljiv.
3.3 Logički operatori
Operacije nad podacima u R jeziku temelje se na osnovnim logičkim operatorima odnosno standardiziranim oznakama koje predstavljaju neku logičku operaciju. Poznavanje logičkih operatora odnosno njihove sintakse je ključno za rad u R sučelju, čak i za najjednostavnije operacije.
& - znak za logičku operaciju “i” (Shift + 6) | - znak za logičku operaciju “ili” (Shift + W)
Osnovni aritmetički i logički operatori:
| Operator | Opis |
|---|---|
| < | manje od |
| <= | manje ili jednako od |
| > | veće od |
| >= | veće od ili jedanko |
| == | upravo ili jednako |
| != | ne (nije) jednako |
| !x | ne x |
x | y |
x ili y |
| x & y | x i y |
| isTRUE(x) | test ako je X ISTINA |
Obratimo pozornost na operator “jednako” koji se piše kao ==. Jedna od čestih sintaksnih pogrešaka je pisanje = za operator “jednako”.
3.4 Pozivanje naredbi i prečaci
R ima stotine ugrađenih naredbi (funkcija). Dodatnim proširenjima, koje nazivamo paketi (packages), proširujemo R mogućnosti. Funkcije pozivamo sa imenom funkcije nakon čega slijede zagrade. Svaka otvorena zagrada mora biti i na kraju funkcije zatvorena. Jedna od najčešćih pogrešaka je upravo zbog manjka ili viška zagrada pri pozivanju funkcija. Svaka funkcija ima argumente. Argumenti funkcije su dijelovi koda koji su nužni za uspješno aktiviranje funkcije. Osim nužnih argumenata, postoje i opcionalni argumenti. Opcionalni argumenti nam dodatno proširuju mogućnosti funkcije, no nisu nužni za samo izvršenje funkcije.
Svaka funkcija poziva se na sljedeći način:
ime_funkcije(argument_1, argument_2, argument_3)Ako poznajemo funkciju i redoslijed argumenata, možemo pisati skraćenu formu, odnosno bez navođenja nekih dijelova argumenata. Jedan od čestih argumenata je data= u kojem specificiramo objekt (podatke) kojeg će funkcija koristiti. Ako znamo da taj argument u nekoj funkciji dolazi na prvo mjesto, možemo preskočiti dio data= i odmah upisati objekt koji funkcija koristi (recimo “prosjecne_ocjene” koji smo vec koristili kao primjer).
Rad u RStudiu možemo olakšati sa već ugrađenim prečacima odnosno kombinacijama tipki. Naravno, one su konfigurabilne i korisnik ih može mijenjati u opcijama RStudia. Neke od najčešće korištenih su:
alt + - oznaka za spremanje objekta TAB otvaranje izbornika sa svim funkcijama i objektima koji započinju s prethodno upisanim slovima Ctrl + Shift + S pokretanje cijele skripte Ctrl + Enter pokretanje označenog koda ili onog segmenta u kojem se nalazi kursor Ctrl + Alt + F10 resetiranje R Ctrl + Shift + A automatsko formatiranje koda
Osim ovih, postoji čitav niz drugih prečaca, a popis možemo vidjeti i prečacem Alt + Shift + K. Također, možemo i sami kreirati novi prečac po želji kroz Tools -> Modify Keyboard Shortcuts
Pri zatvaranju R sesije, dobit ćemo pitanje želimo li spremiti “Workspace”. Spremanje Workspace-a nikad ne preporučamo jer on sprema sve objekte iz Environmenta i pri sljedećem pokretanju R sesije oni ostaju tu, a nakon nekog vremena se više ne sjećamo s kojim promjenama su oni sačuvani niti što predstavljaju te često mogu stvoriti određene logičke pogreške i sukobe među objektima u kreiranju našeg koda. Ova opcija se može trajno ugasiti u globalnim postavkama RStudia te preporučamo da to i napravite odmah. Uđite u Tools -> Global Options -> General i tamo odznačite Restore .RData into workspace at startup i u izborniku Save workspace to .RData on exit postavite Never.
3.5 Vektori, matrice, skupovi podataka, data frame
Skalari su pojedinačni brojevi. Vektori su jednodimenzionalni skup vrijednosti, a možemo reći da su vektori ujedno i polja. Vektori se definiraju pomoću funkcije konkatenacije (concatenate) tj. pomoću funkcije c(). Matrice predočavamo kao tablice tj. dvodimenzionalne tablice koje se sastoje od određenog broja redova (n) i stupaca (m) čiji zapis možemo označiti s [n,m].
Uobičajena forma podataka na koju je većina korisnika koji nisu upoznati s programskim jezicima i statističkom analizom/programiranjem jest “tablica” odnosno matrica koja se sastoji od redaka i stupaca. Uobičajeno je (iako ne nužno) da redci predstavljaju opažanja, a stupci varijable i u većini analiza korištenih u ovoj knjizi teži se ka takvoj, tzv. tidy strukturi podataka.
Varijable u R-u nalaze se u nekoliko temeljnih oblika: * dbl - realni broj (double) * int - cijeli broj (integer) * chr - znak (character) * fctr - faktor (factor) * date - datumi (date) * dttm - datum i vrijeme (date-time) * lgl - logički vektor -> poprima jedino modalitete TRUE ili FALSE (logical)
Vektore kreiramo s funkcijom c(). Vektor možemo kreirati koristeći već postojeće vektore ili stvoriti potpuno novi vektor kroz neku funkciju. Kreirajmo jedan jednostavni vektor koji sadrži brojeve od 1 do 10 i nazovimo ga “moj_prvi_vektor”. Upisivanjem njegovog naziva možemo vidjeti njegov sadržaj u konzoli.
moj_prvi_vektor <- c(1,2,3,4,5,6,7,8,9,10)
moj_prvi_vektor [1] 1 2 3 4 5 6 7 8 9 10Ovaj vektor sada je spremljen u kratkotrajnu memoriju RStudio sesije i nalazi se u okviru “Environment”. Pozivanjem njegovog imena možemo ga modificirati ili koristiti u drugim operacijama. Primjerice, kreirajmo novi vektor koji će sadržavati sve elemente iz vektora “moj_prvi_vektor”, ali 10 puta veće. Nad svakim vektorom možemo upotrijebiti osnovne matematičke operacije pa tako i množenje skalarom. Upravo to nam je dovoljno za dobiti željeni rezultat u ovom primjeru.
vektor2 <- moj_prvi_vektor*10
vektor2 [1] 10 20 30 40 50 60 70 80 90 100Izračunajmo prosjek, zbroj i raspon elemenata iz “moj_prvi_vektor”.
mean(moj_prvi_vektor)[1] 5.5sum(moj_prvi_vektor)[1] 55range(moj_prvi_vektor)[1] 1 10Obratimo pozornost gdje su rezultati - u konzoli. Mean(), sum() i range() našeg vektora nismo spremili kao zasebne objekte (s oznakom <-). Napravimo novi vektor koji ćemo spremiti kao objekt, a sadržavat će prosjek, zbroj i raspon elemenata iz “moj_prvi_vektor”.
vektor3 <- c(mean(moj_prvi_vektor), sum(moj_prvi_vektor), range(moj_prvi_vektor))
vektor3[1] 5.5 55.0 1.0 10.0Prethodni primjeri pokazuju nam neke osnovne načine kako vektore možemo modificirati ili koristiti u kreiranju novih vektora. Kasnije ćemo vidjeti kako vektore koristimo u slaganju kompleksnijih tipova objekata u R-u.
Općenita ideja programskih jezika je automatizacija što većeg broja operacija. U literaturi se često navodi zlatno pravilo prema kojem ne bi trebalo prepisivati kod koji se ponavlja više od 2 puta. Za takve operacije korisno je napisati vlastitu funkciju o čemu će više riječi biti kasnije. Prije pisanja vlastite funkcije valja provjeriti postoji li u R-u ili nekom “etabliranom” paketu funkcija koja obavlja radnju koja nas interesira jer je velika vjerojatnost da većinu funkcija koje nam trebaju imamo u obliku naredbi. Nastavno na naš nedavni primjer, napravimo vektor koji sadrži brojeve od 1 do 10, ali bez da ih ručno upisujemo kao u primjeru “moj_prvi_vektor”. Prikazat ćemo dva različita načina odnosno funkcije koje često koristimo.
vektor10_1 <- c(1:10)
vektor10_2 <- seq(from = 1, to = 10, by = 1)U uvodnom dijelu poglavlja smo spomenuli da argumente u funkcijama nužno ne moramo navoditi sa punom sintaksom. Na primjeru funkcije seq() koji kreira sekvencu pogledajmo što to podrazumijeva.
seq(from = 1, to = 20, by = 2) [1] 1 3 5 7 9 11 13 15 17 19seq(1, 20, 2) [1] 1 3 5 7 9 11 13 15 17 19Funkcija seq() zahtijeva minimalno tri argumenta: početak sekvence, kraj sekvence i inkrement odnosno razliku između svaka dva elementa u sekvenci (ona naravno može biti i negativna). Ukoliko poznajemo koji argumenti su potrebni u funkciji, ne moramo pisati pune nazive arguemenata već upisati samo vrijednosti. U slučaju funkcije seq() nije nužno pisati “from=”, “to=” i “by=” već samo poštujući redoslijed upisati željene karakteristike sekvence. Na isti način funkcionira većina funkcija u R-u. Ne zaboravimo da je redoslijed argumenata važan.
Dosada smo kreirali samo numeričke vektore. Kreirajmo jedan vektor sa znakovima.
drzave <- c("Hrvatska", "Italija", "Slovenija", "Austrija")Upisivanje znakova pri kreiranju vektora nužno mora biti unutar navodnih znakova ““. Svaki otvoreni navodni znak” mora biti i zatvoren. Višak ili manjak navodnih znakova je također jedna od najčešćih pogrešaka u pisanju koda.
Vratimo se na tipove varijabli odnosno klase. Za svaku varijablu, ali i bilo koji drugi objekt ili naredbu u R možemo provjeriti klasu. Za to nam služi naredba class().
class(drzave) [1] "character"class(moj_prvi_vektor) [1] "numeric"class(mean)[1] "function"Funkcija class() nam je redom pokazala kako je vektor “drzava” klase character, “moj_prvi_vektor” klase numeric, a “mean” klase function odnosno funkcija.
3.6 Pristupanje elementima vektora i modifikacija vektora
Svaki vektor ima svoj indeks odnosno brojčanu oznaku redoslijeda elementa u vektoru. Indeks vektora u R započinje s 1 (za razliku od većine drugih programskih jezika u kojima započinje s 0). To znači da prvi element u vektoru ima indeks 1, a svaki sljedeći ima indeks za 1 veći.
Indeksi nam, među ostalim, služe i u pozivanju specifičnog elementa vektora. Pristupanje specifičnom elementu vektora radimo pomoću uglatih zagrada [] nakon naziva vektora. Znak minus prije elementa znači da taj element ne želimo pozvati. Pogledajmo na primjeru vektora “drzave” pristup specificiranim elementima vektora.
drzave[2] # pristupamo drugom elementu vektora države[1] "Italija"drzave[c(1,4)] # pristupamo prvom i četvrtom elementu vektora države[1] "Hrvatska" "Austrija"drzave[-3] # pristupamo svim elementima osim trećeg[1] "Hrvatska" "Italija" "Austrija"Sada znamo pristupiti određenim elementima vektora. Povežimo to sa spremanjem vektora odnosno objekta i modificirajmo naš vektor “države”. Primjerice, promijenimo četvrti element vektora (Austrija) u “Francuska”.
drzave[4] <- "Francuska"
drzave[1] "Hrvatska" "Italija" "Slovenija" "Francuska"Na ovaj način možemo kreirati i novi element vektora koji sad ne postoji. Primjerice, kreirajmo peti element vektora “Portugal”.
drzave[5] <- "Portugal"
drzave[1] "Hrvatska" "Italija" "Slovenija" "Francuska" "Portugal" Također, možemo i logičkim operatorima zadavati argumente prema kojima želimo pristupati (ili mijenjati) specifičnim elementima vektora. Primjerice, sve elemente u vektoru koji su manji od 5 pretvorimo u nulu.
moj_prvi_vektor <- seq(1,10,1)
moj_prvi_vektor[moj_prvi_vektor<5] <- 0
moj_prvi_vektor [1] 0 0 0 0 5 6 7 8 9 103.7 Paketi (librar-y/is)
Jedna od snaga programskog jezika R i najčešće korištenog grafičkog sučelja RStudio su proširenja osnovnog R jezika odnosno naredbi. Proširenja se nazivaju paketi (packages). Paket se instalira naredbom install.packages("imepaketa").
Jednom instalirani paketi se u aktualnoj R skripti pozivaju s naredbom
library(imepaketa). Naredbe iz nekog paketa ne možemo koristiti ako taj paket nismo aktivirali s naredbomlibrary(). Radi što bolje čitljivosti koda i replikabilnosti R skripte preporučamo da se paketi pozivaju odmah na početku svake R skripte. Jednom pozvani paket, primjericelibrary(tidyverse)nije potrebno pozivati u ostatku sesije.
Tidyverse paket obuhvaća set paketa koji su kreirani od strane RStudio grupacije te predstavljaju najsveobuhvatniji pristup upravljanju i analizi podataka u R-u (Wickham et al., 2019) Tidyverse svijet predstavlja pristup programiranju u R-u koji je okrenut ka korisniku i na sustavan način pristupa sintaksi pozivanja funkcija i argumenata kroz sve svoje pakete. Paketi1 iz tidyverse svijeta proširenja (dplyr, ggplot2, tidyr, readr, purrr, tibble, string, forcats) spadaju u najčešće korištene pakete u R okruženju. Brojni korisnici R većinu svog kodiranja svode na korištenje tidyverse paketa (naravno uz osnovni R). Za one koji su upoznati s Python jezikom Pandas paket je najbolja direktna usporedba s tidyverse-om.
U nastavku udžbenika većinu transformacija i manipulacija podataka prikazat ćemo na više načina, uglavnom kroz osnovni R kod i kroz tidyverse pristup.
Instalirajmo cijeli tidyverse paket.
install.packages("tidyverse")Osim tidyverse paketa koristit ćemo i druge pakete. Na CRAN-u (službenom repozitoriju R paketa) u ožujku 2023. bilo je dostupno preko 19 200 različitih paketa. Preporuka je da koristite pakete koji se redovito ažuriraju, imaju dobru povijest korištenja i detaljno su dokumentirani.
Jednom instalirani paket i naredbu install.packages() više ne treba koristiti za isti paket već samo pozvati naredbe iz paketa s library(). Idealno, pozivanje paketa se piše na početku svake R skripte tako da kasnijim korištenjem ili u suradnji s drugima bude jasno koji paketi se koriste u kodu. Napomena, ako instalirate novu verziju R-a, morat ćete ponovno instalirati pakete, te je preporuka da aktivacija paketa bude dio koda koji koristite.
Naredbom ? otvaramo pomoć za svaku naredbu ili cijeli paket.
library(tidyverse)
?mean
?seq
?dplyr3.8 Data frame i upravljanje podatcima
Data frame je temeljni oblik “tablice” koju R prepoznaje. U osnovi ona se sastoji od više vektora. Idealni oblik data frame-a je matrica. Za one koji će preferirati tidyverse svijet kodiranja tibble je oblik gotovo identičan data frame-u i u osnovi za krajnjeg korisnika razlika se svodi na prikaz u konzoli i poduzorak2.
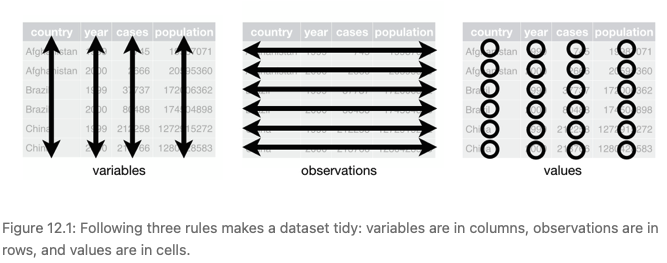
U idelanom obliku, pojedinačna varijabla predstavljena je stupcem dok su opažanja predstavljena retkom te je konačno pojedinačna vrijednost određena pojedinim opažanjem i varijablom.
Dataset je skup vrijednosti koje su predstavljene brojevima (kvantitativne varijable) ili znakovima (kvalitativne varijable). Svaka vrijednost pripada varijabli i entitetu. Varijabla sadrži vrijednosti nekog mjerenja koje imaju zajednički atribut ili mjernu vrijednost (visina, težina, temperatura i sl.). Entitet ili opažanje sadrži sve vrijednosti različitih varijabli koje pripadaju nekoj jedinici ili jedinki. To može biti osoba, grad, životinja, predmeti poput automobila i ostalo.
Na sljedećem slikovnom prikazu možemo shematski vidjeti što znači tidy (dostupno s: http://r4ds.had.co.nz/tidy-data.html).
Kreirajmo naš prvi skup podataka u formatu data frame.
Za početak, kreirajmo četiri vektora koji sadrže po 10 elemenata: ID, spol, visina, tjelesna težina. Kada ih spremimo kao zasebne objekte, povežimo ih u data frame s naredbom data.frame().
ID <- c(1:10)
spol <- c("m", "z", "m", "z", "m", "z", "m", "z", "m", "z")
visina <- c(188, 169, 178, 172, 185, 157, 189, 183, 182, 166)
tezina <- c(87, 45, 83, 67, 93, 52, 102, 79, 70, 59)
mjere <- data.frame(ID, spol, visina, tezina)
mjere ID spol visina tezina
1 1 m 188 87
2 2 z 169 45
3 3 m 178 83
4 4 z 172 67
5 5 m 185 93
6 6 z 157 52
7 7 m 189 102
8 8 z 183 79
9 9 m 182 70
10 10 z 166 59Redoslijed vektora koje spajamo u data frame je bitan jer će nam upravo navedenim redoslijedom biti poredani stupci. Data frame “mjere” sastoji se od 10 redaka i 4 stupca [10 x 4]. Slično kao i kod vektora, elementima data frame-a pristupamo sa oznakama retka i/ili stupca.
mjere[2,] # odaberimo samo drugi redak ID spol visina tezina
2 2 z 169 45mjere[,3] # odaberimo samo treći stupac [1] 188 169 178 172 185 157 189 183 182 166mjere[1:5, 3:4] # odaberimo podatke iz redaka 1 do 5, stupaca 3 i 4 visina tezina
1 188 87
2 169 45
3 178 83
4 172 67
5 185 93mjere[c(1,4), 3] # odaberimo podatke iz redaka 1 i 4, stupca 3[1] 188 172Osim specificiranja sa [n, m] gdje je n oznaka retka, a m oznaka stupca, možemo se koristiti i sa operatorom $ nakon naziva data frame-a. Operator $ služi za odabir stupca (varijable) iz data frame-a.
mjere$tezina [1] 87 45 83 67 93 52 102 79 70 59Primjetimo kako nakon upisivanja operatora $ RStudio otvara okvir koji nudi sve varijable (stupce) koji postoje unutar data frame-a. Ovakav način kodiranja nam značajno ubrzava pisanje koda i pojednostavnjuje upravljanje podacima.
Operator $ nam omogućuje i kreiranje novog stupca unutar postojećeg data frame-a. Napravimo novi stupac naziva BMI koji predstavlja indeks tjelesne težine (Body Mass Index) prema formuli za izračun BMI. Također, izračunajmo i prosječan BMI.
mjere$BMI <- mjere$tezina/(mjere$visina)^2*10000
mjere ID spol visina tezina BMI
1 1 m 188 87 24.61521
2 2 z 169 45 15.75575
3 3 m 178 83 26.19619
4 4 z 172 67 22.64738
5 5 m 185 93 27.17312
6 6 z 157 52 21.09619
7 7 m 189 102 28.55463
8 8 z 183 79 23.58984
9 9 m 182 70 21.13271
10 10 z 166 59 21.41094mean(mjere$BMI) # prosječan BMI [1] 23.21723.9 Podskup baziran na vrijednostima opažanja
Do sada smo koristili stvaranje podskupa podataka pomoću specificiranja pozicije elementa vektora ili data frame-a. U stvarnim analizama, rjeđe ćemo koristiti takav način stvaranja podskupa. Osnovni R i tidyverse paket sadrže nekoliko načina kojima možemo stvoriti podskup koji se bazira na vrijednostima opažanja.
Za daljnje primjere koristit ćemo se podacima koji su već ugrađeni u RStudio ili tidyverse paket. Ti podaci koriste se za učenje sintakse i rada u R jeziku te većina primjera i rješenja problema koji se mogu pronaći na internetu koriste upravo te podatke.
Počinjemo s osnovnim R naredbama. Nakon učitavanja podataka, uvijek je dobro pogledati njihov sadržaj i strukturu. Obično pozivanje naziva objekta čiji se sadržaj prikaže u konzoli nije najpraktičnije rješenje, pogotovo za veće data frame-ove. Funkcija View() otvara nam objekt u novom okviru unutar RStudia. Umjesto View() možemo i mišem kliknuti na naziv objekta u okviru “Environment” u kojem se nalazi popis naših objekata spremljenih u kratkotrajnu memoriju tekuće R sesije.
Za sažeti prikaz u konzoli, možemo koristiti naredbu head() za prikaz prvih 50 redaka iz skupa podataka ili tail() za prikaz posljednjih 50 redaka iz skupa podataka. U nastavku će se koristiti naredba head(). Radi preglednosti knjige, mi smo ograničili prikaz head() naredbe na prvih 6 redaka.
Učitajmo podatke o kriminalnim slučajevima u SAD-u (na 100 000 stanovnika te udio urbanog stanovništva). Koristiti ćemo ugrađeni skup podataka USArrests. Obzirom da je on ugrađen u RStudio, nije nužno spremati ga kao zaseban objekt naredbom <-, već ga možemo odmah pozvati u neku naredbu koju ćemo koristiti.
Napravimo novi objekt odnosno data frame koji će sadržavati samo one države koje imaju udio urbanog stanovništva viši od 69%.
# pogledajmo sadržaj i strukturu podataka u konzoli
head(USArrests) Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7# zadržimo samo države koje imaju udio urbanog stanovništva više od 69%
# 1. način
urban_krim <- USArrests[USArrests$UrbanPop>69,]
urban_krim Murder Assault UrbanPop Rape
Arizona 8.1 294 80 31.0
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7
Connecticut 3.3 110 77 11.1
Delaware 5.9 238 72 15.8
Florida 15.4 335 80 31.9
Hawaii 5.3 46 83 20.2
Illinois 10.4 249 83 24.0
Massachusetts 4.4 149 85 16.3
Michigan 12.1 255 74 35.1
Missouri 9.0 178 70 28.2
Nevada 12.2 252 81 46.0
New Jersey 7.4 159 89 18.8
New Mexico 11.4 285 70 32.1
New York 11.1 254 86 26.1
Ohio 7.3 120 75 21.4
Pennsylvania 6.3 106 72 14.9
Rhode Island 3.4 174 87 8.3
Texas 12.7 201 80 25.5
Utah 3.2 120 80 22.9
Washington 4.0 145 73 26.2Što smo u odabiru država koje imaju udio urbanog stanovništva više od 69% zapravo napravili? Odabrali određene retke koji zadovoljavaju naš uvjet. Osim toga, odabrali smo i sve stupce našeg izvornog USArrests skupa podataka. Iz tog razloga nakon našeg uvjeta slijedi zarez nakon kojeg zatvaramo uglate zagrade. Da smo htjeli zadržati samo određene stupce, nakon zareza bi upisali pozicije ili nazive tih stupaca. Sjetimo se, data frame je formata [n,m] gdje je n broj redaka, a m broj stupaca.
# 2. način - pomoću funkcije subset
subset(USArrests, UrbanPop > 69, select = c("Murder", "Assault", "UrbanPop", "Rape")) Murder Assault UrbanPop Rape
Arizona 8.1 294 80 31.0
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7
Connecticut 3.3 110 77 11.1
Delaware 5.9 238 72 15.8
Florida 15.4 335 80 31.9
Hawaii 5.3 46 83 20.2
Illinois 10.4 249 83 24.0
Massachusetts 4.4 149 85 16.3
Michigan 12.1 255 74 35.1
Missouri 9.0 178 70 28.2
Nevada 12.2 252 81 46.0
New Jersey 7.4 159 89 18.8
New Mexico 11.4 285 70 32.1
New York 11.1 254 86 26.1
Ohio 7.3 120 75 21.4
Pennsylvania 6.3 106 72 14.9
Rhode Island 3.4 174 87 8.3
Texas 12.7 201 80 25.5
Utah 3.2 120 80 22.9
Washington 4.0 145 73 26.2Funkcija subset() ima tri osnovna argumenta: objekt iz kojeg želimo kreirati novi podskup (USArrests), uvjet kojeg opažanja moraju zadovoljiti da bi ušli u podskup (UrbanPop > 79) te stupce (varijable) koje želimo zadržati (u ovom slučaju želimo zadržati sve stupce pa unutar argumenta select = c() upisujemo sve nazive stupaca).
Sličnu logiku slijedi i tidyverse pristup. Razlika je u tome da je select() zasebna funkcija, a ne argument kao kod subset(). Napravimo sličan primjer sa funkcijom filter() samo ovaj puta uzimamo države s udjelom urbanog stanovništva većim od 79%.
urban_krim <- filter(USArrests, UrbanPop > 79)
head(urban_krim) Murder Assault UrbanPop Rape
Arizona 8.1 294 80 31.0
California 9.0 276 91 40.6
Florida 15.4 335 80 31.9
Hawaii 5.3 46 83 20.2
Illinois 10.4 249 83 24.0
Massachusetts 4.4 149 85 16.3Da bi mogli efektno koristiti uvjetne odabire dijela skupa podataka važno je poznavati sve osnovne logičke operatore poput == (jednako), != (nije jednako), >, <, >= i <=. Unutar kreiranja podskupa == označava znak jednakosti, a ne =. Ovo je jedan od čestih izvora grešaka u kodiranju, no konzola će nas upozoriti na ovaj problem.
Kod stvaranja podskupa često će nam koristiti operator %in% koji predstavlja logički operator “je li x unutar y”. Također, možemo koristiti više uvjeta prema kojima stvaramo novi podskup. Za to će nam trebati novi operatori & (i) te | (ili). Upotrijebimo novi set podataka koji se nalazi u tidyverse paketu - diamonds odnosno podatke o dijamantima. Primjer: odaberimo samo one dijamante koji su boje F, G ili H te im je cijena niža od 540.
dijamanti <- diamonds
bojeFGH <- filter(dijamanti, color %in% c("F", "G", "H") & price < 540)
head(bojeFGH)# A tibble: 6 × 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.26 Very Good H SI1 61.9 55 337 4.07 4.11 2.53
2 0.23 Very Good H VS1 59.4 61 338 4 4.05 2.39
3 0.22 Premium F SI1 60.4 61 342 3.88 3.84 2.33
4 0.23 Very Good H VS1 61 57 353 3.94 3.96 2.41
5 0.23 Very Good G VVS2 60.4 58 354 3.97 4.01 2.41
6 0.23 Very Good F VS1 60.9 57 357 3.96 3.99 2.42Sjetimo se da puni naziv argumenta “data =” ne trebamo pisati, dovoljno je na prvo mjesto upisati naziv skupa podataka kojeg filtriramo.
Ovaj skup podataka ima 10 varijabli. Ponekad će skupovi imati stotine varijabli od kojih ćete koristiti tek manji broj. U tom slučaju potrebno je “skratiti” stupce odnosno odabrati one koji nas interesiraju. Kao i ostale radnje u R-u, to možemo napraviti na više načina. Opet ćemo prikazati nekoliko načina iz osnovnog R i tidyverse paketa. Primjer: želimo zadržati neke stupce.
# zadržimo veličinu, transparentnost i cijenu dijamanta
subset(dijamanti, select = c("carat", "clarity", "price"))
# zadržimo veličinu, boju i dubinu dijamanta
dijamanti[c("carat", "color", "depth")]
# zadržimo cijenu, boju i rez dijamanta, tidyverse pristup
select(dijamanti, price, color, cut)
# zadržimo sve stupce od veličine (carat) do cijene (price)
select(dijamanti, carat:price)
# zadržimo sve stupce osim dubine (depth)
select(dijamanti, -depth) Za kraj, napomenimo da imenovanje novog objekta sa linijom koda dijamanti <- diamonds, isto kao i u ranijem primjeru SAD_krim <- USArrests nije nužno jer su objekti diamonds i USArrests ugrađeni u već pozvani tidyverse paket pa smo svugdje u funkcijama mogli koristiti naziv diamonds ili USArrests, no većina početnih korisnika RStudio okruženja koristi klik mišem na objekt u environmentu kojim stječe vizualni dojam o skupu podataka rađe nego head() funkciju te smo stoga uveli ovaj korak.
# ugrađeni skup diamonds
head(diamonds)# A tibble: 6 × 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48# ugrađeni skup USArrests
head(USArrests) Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.73.10 Stvaranje nove varijable
Napraviti nove varijable (poželjno u obliku stupca) unutar postojećeg data frame-a možemo raditi na već spomenuti način pomoću operatora $, funkcije cbind() ili funkcije mutate() koja je dio tidyverse paketa. Funkcija cbind() spaja različite stupce u jedan data frame (u postojeći ili neki novi), dok naredba mutate() stvara nove stupce koji predstavljaju funkcije (transformacije) postojećih varijabli.
Napravimo novi stupac koji će biti umnožak stupaca x, y i z iz skupa podataka diamonds. U ovom primjeru prikazat ćemo tri najčešća načina kako napraviti novi stupac.
dijamanti <- diamonds
# 1. način pomoću operatora $
dijamanti$volumen <- dijamanti$x*dijamanti$y*dijamanti$z obujam <- dijamanti$x*dijamanti$y*dijamanti$z
# 2. način pomoću cbind()
cbind(dijamanti, obujam) # 3. način pomoću mutate()
mutate(dijamanti, vol = x*y*z) # uočimo nove stupce "volumen", "obujam" i "vol"
head(dijamanti)# A tibble: 6 × 11
carat cut color clarity depth table price x y z volumen
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl> <dbl>
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 38.2
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 34.5
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 38.1
4 0.29 Premium I VS2 62.4 58 334 4.2 4.23 2.63 46.7
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75 51.9
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48 38.7Uočimo kako sve tidyverse funkcije prate isti obrazac: prvi argument funkcije je skup podataka koji koristimo, a potom slijede ostali argumenti.
3.11 Pipe operator
Do sada smo upotrijebili tri važne funkcije u upravljanju podacima: 1) stvaranje podskupa (na temelju uvjeta), 2) odabir stupaca i 3) dodavanje novog stupca. U svakodnevnom radu ove radnje često ćemo obavljati jednu za drugom i koristiti zadnju varijatnu podskupa. Primjer:
dijamanti <- diamonds
dijamanti <- filter(dijamanti, price < 700 & cut %in% c("Premium", "Ideal"))
dijamanti <- mutate(dijamanti, volumen = x*y*z)
dijamanti <- select(dijamanti, carat:clarity)
head(dijamanti)# A tibble: 6 × 4
carat cut color clarity
<dbl> <ord> <ord> <ord>
1 0.23 Ideal E SI2
2 0.21 Premium E SI1
3 0.29 Premium I VS2
4 0.23 Ideal J VS1
5 0.22 Premium F SI1
6 0.31 Ideal J SI2 Ovakav način kodiranja je potpuno ispravan, ali on može biti puno kraći i pregledniji, a dati potpuno jednak rezultat. Pipe operator %>% (njegov prečac na tipkovnici je ctrl + shift + m) je također dio tidyverse svijeta3 koji značajno pojednostavnjuje naš kod.
Kod u prethodnom dijelu možemo napisati na sljedeći način koristeći %>%:
dijamanti <- diamonds %>% filter(price < 700 & cut %in% c("Premium", "Ideal"))%>%
mutate(volumen=x*y*z) %>% select(carat:clarity)
head(dijamanti)# A tibble: 6 × 4
carat cut color clarity
<dbl> <ord> <ord> <ord>
1 0.23 Ideal E SI2
2 0.21 Premium E SI1
3 0.29 Premium I VS2
4 0.23 Ideal J VS1
5 0.22 Premium F SI1
6 0.31 Ideal J SI2 Četiri zasebna bloka koda pretvorili smo u jedan blok koda koji je također i pregledniji jer slijedi logiku izvođenja s lijeva na desno. Dakle, kod će se izvoditi na sljedeći način: učitaju se podaci “diamonds” iz kojih se stvori podskup dijamanata s cijenom manjom od 700 te Premium ili Ideal rezom. Potom se kreira novi stupac volumen koji je umnožak elemenata iz stupaca x, y i z te odaberu stupci od carat do clarity. Konačno, takav podskup spremljen je kao novi objekt naziva “dijamanti”.
Primjetimo da u ovakvom nizu nije bilo potrebno koristiti niti argument “data=” unutar filter(), mutate() i select()funkcija jer se kod izvodi s lijeva na desno, a povezuje ga poveznica %>% te R zna na koje podatke se odnose funkcije. Valja naglasiti da se podaci nastavljaju iz funkcije u funkciju i da je redoslijed ključan. Da smo u ovom slučaju select() upotrijebili prije mutate(), kod se ne bi mogao izvršiti jer mutate() ne bi mogao pronaći stupce x, y i z koje prethodno sa select() nismo zadržali.
Ovakav slijed u kodiranju ćemo koristiti i u ostatku ove knjige.
Radi preglednosti našeg koda, posebno u dužim linijama gdje imamo nizanje naredbi kao u aktualnom slučaju, preporučamo automatsko formatiranje koda. To možemo napraviti označivanjem koda kojeg želimo reformatirati i klikanjem na prečac:
ctrl+alt+i. Alternativno, možemo i sami prebaciti dio koda u novi red klikom naenter. Primjetimo kako je dio koda koji je u novom redu uvučen od početka linije! Ovo je jako važno, jer u slučaju da taj kod nije uvučen, R bi smatrao da se radi o novoj liniji, nizu funkcija, umjesto postojećem nizu koji je samo prebačena u novi redak radi preglednosti. Ovo je osobni izbor, reformatiranje koda nije nužno već samo opcija koja utječe na preglednost koda i cijele R skripte.
U recentnim verzijama R jezik je omogućio vlastitu varijantu pipe operatora |> kojem je kratica na tipkovnici ista kao i kod %>% operatora samo je u opcijama RStudija potrebno promijeniti koji operator koristimo, što se radi pod Global options -> Code -> Use native pipe operator, |> . Debata oko korištenja %>% ili |> pipe operatora se svodi na osobne preferencije korisnika i minorne razlike, a obzirom da je tidyverse operator %>% znatno stariji i već ustaljen kod većine korisnika u nastavku knjige ćemo koristiti upravo taj operator.
3.12 Grupiranje podataka i operacije nad grupiranim podacima
Do sada smo koristili funkcije koje bi tretirale naš data frame kao skup pojedinačnih opažanja i varijabli. Uz takav način rada, često ćemo naše podatke htjeti grupirati prema nekom obilježju odnosno varijabli. Krenimo s primjerom iz do sada poznatog skupa podataka diamonds. Za to ćemo koristiti tidyverse pristup i koristiti dvije nove funkcije: group_by i summarise.
Općeniti slijed u kodiranju nad grupiranim podacima koji uključuje summarise() funkciju izgleda ovako:
data_frame %>%
group_by(varijabla_prema_kojoj_zelimo_grupirati) %>%
summarise(naziv = funkcija_koju_zelimo_primijeniti)Primjer: izračunajmo prosječnu cijenu dijamanta po boji (varijabla color) i sačuvajmo takav data frame kao zaseban objekt
cijena_po_boji <- diamonds %>% group_by(color) %>%
summarise(prosjecna_cijena = mean(price, na.rm = TRUE))
head(cijena_po_boji)# A tibble: 6 × 2
color prosjecna_cijena
<ord> <dbl>
1 D 3170.
2 E 3077.
3 F 3725.
4 G 3999.
5 H 4487.
6 I 5092.Što se u pozadini dogodilo? Funkcijom group_by grupirali smo naše podatke po željenoj varijabli (color). Takvi podaci u osnovi nisu promijenili izgled i sadržaj našeg skupa diamonds, ali su uputili R da sljedeću operaciju nad skupom diamonds provede nad podskupovima dijamanata koji su grupirani po varijabli color. Group_by sam po sebi ne provodi nikakvu operaciju nad podacima te nam je zato bila potrebna nova funkcija - summarise(). Summarise() inače svodi cijeli skup podataka na jedan red, no ona se gotovo uvijek koristi nad grupiranim podacima. Obzirom da smo skup podataka sa group_by sveli na podskupove prema boji dijamanta (varijabla color), summarise() će svesti cijeli skup diamonds na onaj broj redova koliko različitih boja dijamanata postoji u skupu.
Dodatno, unutar već poznate funkcije mean() dodali smo i argument na.rm=TRUE koji nam u računanju prosjeka ne uzima u obzir NA elemente (Not Available) odnosno prazne ćelije u skupu podataka. Prosjek nekog vektora koji sadrži makar jedan NA je uvijek NA. Zapamtimo: NA nije nula ili prazan skup, NA jednostavno znači missing value, prazna ćelija, nepostojeća vrijednost.
Podatke možemo grupirati i po više kriterija, a također unutar summarise() funkcije možemo zadati i više funkcija koje želimo provesti nad grupiranim podacima. Primjer: izračunjamo prosječnu i najvišu cijenu dijamanata po boji i rezu (varijable color i cut) te broj dijamanata u svakoj podgrupi.
diamonds %>% group_by(color, cut) %>%
summarise(prosjecna_cijena = mean(price, na.rm = T),
najvisa_cijena = max(price, na.rm = T),
broj_dijamanata = n())`summarise()` has grouped output by 'color'. You can override using the
`.groups` argument.# A tibble: 35 × 5
# Groups: color [7]
color cut prosjecna_cijena najvisa_cijena broj_dijamanata
<ord> <ord> <dbl> <int> <int>
1 D Fair 4291. 16386 163
2 D Good 3405. 18468 662
3 D Very Good 3470. 18542 1513
4 D Premium 3631. 18575 1603
5 D Ideal 2629. 18693 2834
6 E Fair 3682. 15584 224
7 E Good 3424. 18236 933
8 E Very Good 3215. 18731 2400
9 E Premium 3539. 18477 2337
10 E Ideal 2598. 18729 3903
# ℹ 25 more rowsNaravno, što više kriterija za grupiranje zadajemo, to će nam i finalni skup podataka biti veći. Također, povećavanjem varijabli prema kojima grupiramo podatke otvaramo si i problem reprezentativnosti uzoraka odnosno rezultata koje dobivamo nad tim grupama. Povećavanje broja varijabli prema kojima grupiramo zapravo fragmentiramo naš skup na brojne manje podskupove. Uočimo još jednu novu funkciju - n() koja nam prebrojava broj članova u svakoj grupi podataka. Ta funkcija nam je korisna kako bi uočili koliki nam je uzorak za svaku grupu za koju računamo neke pokazatelje, a u ovom slučaju prosjek, i eventualno primijenili drugu mjeru.
Uočimo da na.rm=TRUE možemo pisati skraćeno, koristeći T umjesto TRUE. Isto vrijedi i za logičku vrijednost FALSE, možemo ju pisati skraćeno s F. Kad god možemo, skratimo naš kod i učinimo ga preglednijim!
Ako poštujemo sintaksu R jezika, možemo koristiti sve do sada naučene funkcije i argumente. Primjenimo sada kod za stvaranje podskupa: želimo izračunati prosječnu cijenu dijamanata po rezu (varijabla cut), ali samo za dijamante koji su skuplji od 600 dolara.
diamonds %>% group_by(cut) %>%
summarise(prosjek_skupih = mean(price[price>600]))# A tibble: 5 × 2
cut prosjek_skupih
<ord> <dbl>
1 Fair 4400.
2 Good 4308.
3 Very Good 4422.
4 Premium 4811.
5 Ideal 3685.Kada želimo završiti rad sa grupiranim podacima i nastaviti koristiti naš početni skup sa negrupiranim podacima, pozovimo funkciju ungroup(). Neke funkcije, poput summarise() će automatski i odgrupirati skup i obavijestiti nas u konzoli.
diamonds %>% ungroup()Tally() funkcija je slična summarise() funkciji. Tally() također može funkcionirati na grupiranim podacima, a poziva n() ili sum(n), ovisno o tome pozivamo li tally() prvi put u bloku koda ili ponovno. Count() funkcija je slična tally() funkciji s tim da ona preskače korak grupiranja. Na primjeru ćemo pojasniti:
# grupirajmo dijamante po boji i rezu, pozovimo tally() koji će nam dati n()
diamonds %>% group_by(color, cut)%>% tally()# A tibble: 35 × 3
# Groups: color [7]
color cut n
<ord> <ord> <int>
1 D Fair 163
2 D Good 662
3 D Very Good 1513
4 D Premium 1603
5 D Ideal 2834
6 E Fair 224
7 E Good 933
8 E Very Good 2400
9 E Premium 2337
10 E Ideal 3903
# ℹ 25 more rows# isti rezultat dobijemo koristeći count()
diamonds %>% count(color, cut)# A tibble: 35 × 3
color cut n
<ord> <ord> <int>
1 D Fair 163
2 D Good 662
3 D Very Good 1513
4 D Premium 1603
5 D Ideal 2834
6 E Fair 224
7 E Good 933
8 E Very Good 2400
9 E Premium 2337
10 E Ideal 3903
# ℹ 25 more rowsPri kraju ovog dijela upravljanja podacima spomenimo funkciju arrange(). Oni koji su navikli na Excelov način rada često koriste neku vrstu arrange() funkcije kako bi poredali podatke po nekom kriteriju. U RStudiu možemo unutar funkcije View() odnosno grafičkog sučelja u kojem pregledavamo naše skupove podataka poredati sve varijable klikom miša na odgovarajuću strelicu pokraj naziva varijable.
Takav način sortiranja podataka unutar View() opcije ne mijenja stvarni sadržaj i redoslijed unutar skupa podataka već služi samo za vizualizaciju naših podataka. Ako želimo trajno promijeniti redoslijed podataka onda koristimo arrange() funkciju nad našim skupom podataka. Poredajmo skup dijamanti prema cijeni od više ka nižoj sa argumentom desc() koji podrazumijeva descending odnosno padajuću vrijednost.
diamonds %>% arrange(desc(price))# A tibble: 53,940 × 10
carat cut color clarity depth table price x y z
<dbl> <ord> <ord> <ord> <dbl> <dbl> <int> <dbl> <dbl> <dbl>
1 2.29 Premium I VS2 60.8 60 18823 8.5 8.47 5.16
2 2 Very Good G SI1 63.5 56 18818 7.9 7.97 5.04
3 1.51 Ideal G IF 61.7 55 18806 7.37 7.41 4.56
4 2.07 Ideal G SI2 62.5 55 18804 8.2 8.13 5.11
5 2 Very Good H SI1 62.8 57 18803 7.95 8 5.01
6 2.29 Premium I SI1 61.8 59 18797 8.52 8.45 5.24
7 2.04 Premium H SI1 58.1 60 18795 8.37 8.28 4.84
8 2 Premium I VS1 60.8 59 18795 8.13 8.02 4.91
9 1.71 Premium F VS2 62.3 59 18791 7.57 7.53 4.7
10 2.15 Ideal G SI2 62.6 54 18791 8.29 8.35 5.21
# ℹ 53,930 more rows3.13 Transformacija skupa podataka
Idealni oblik skupa podataka za analizu je onaj u kojem stupci predstavljaju varijable, a redci opažanja. U svakodnevnom radu često ćemo nailaziti na skupove podataka koji nisu takvog oblika. Ponekad i naša analiza zahtijeva da koristimo oblik podataka koji je drugačiji od navedenog. U ovom dijelu pokazat ćemo kako jednostavno tidyverse pristupom možemo transformirati naš skup podataka po pitanju odnosa redaka i stupaca.
Postoje dva osnova tipa transformacije skupa podataka po pitanju odnosa redaka i stupaca. Prvi je “produživanje” skupa, odnosno povećanje broja redaka, a smanjenje broja stupaca. Ovaj slučaj najčešće imamo kada su nam neki stupci opažanja, a trebali bi biti varijable. Za navedeno ćemo koristiti funkciju pivot_longer(). Za one koji su koristili tidyverse prije rujna 2019. godine (tidyr verzija 1.0.0), poznata je funkcija gather() koja i dalje funkcionira, ali više nije u aktivnom razvoju.
Drugi slučaj je onaj u kojem želimo imati veći broj stupaca, a manji broj redaka, odnosno želimo “proširiti” skup podataka. Za navedeno ćemo koristiti funkciju pivot_wider(). Ova funkcija je novija varijanta starije funkcije spread().
Započnimo sa “produživanjem” skupa sa pivot_longer() na primjeru skupa podataka USPersonalExpenditure. U ovom slučaju ćemo osim samog produživanja napraviti još nekoliko transformacija skupa podataka, upravo jer u svakodnevnom radu nećemo uvijek raditi sa “idealnim” oblikom podataka. Za početak pogledajmo kako izgleda taj skup podataka i koje je klase.
head(USPersonalExpenditure) 1940 1945 1950 1955 1960
Food and Tobacco 22.200 44.500 59.60 73.2 86.80
Household Operation 10.500 15.500 29.00 36.5 46.20
Medical and Health 3.530 5.760 9.71 14.0 21.10
Personal Care 1.040 1.980 2.45 3.4 5.40
Private Education 0.341 0.974 1.80 2.6 3.64class(USPersonalExpenditure)[1] "matrix" "array" U ovom slučaju se radi o klasi “matrix” i “array”. Za početak, pretvorimo ovaj skup u data frame s funkcijom koju smo već koristili i nazovimo ga “siroki_US”.
siroki_US <- as.data.frame(USPersonalExpenditure)
head(siroki_US) 1940 1945 1950 1955 1960
Food and Tobacco 22.200 44.500 59.60 73.2 86.80
Household Operation 10.500 15.500 29.00 36.5 46.20
Medical and Health 3.530 5.760 9.71 14.0 21.10
Personal Care 1.040 1.980 2.45 3.4 5.40
Private Education 0.341 0.974 1.80 2.6 3.64Sada imamo format s kojim želimo raditi, “data frame”. Ovaj skup sadrži potrošnju za pet osnovnih skupina proizvoda i usluga (Food and Tobacco, Household operation i ostale) za svakih pet godina od 1940 do 1960. Želimo da konačni skup ima varijable koje se odnose na skupinu proizvoda i usluga naziva “kategorija”, iznos potrošnje za svaku skupinu naziva “potrosnja” i godinu na koju se odnosi naziva “godina”.
No, prije samog rada, primjetimo jednu novost: skupine proizvoda i usluga (Food and Tobacco, Household operation i ostale) nisu klasična varijabla (stupac)! Oni su tzv. nazivi redaka (R ih naziva rownames) i kao takvi se ne smatraju “punopravnom” varijablom. Dakle, ne možemo raditi uobičajene operacije koje smo do sad radili sa stupcima. Prije sljedećeg koraka u transformaciji skupa u duži oblik, moramo rownames pretvoriti u pravu varijablu odnosno stupac. To ćemo najjednostavnije napraviti pomoću funkcije rownames_to_column() iz tidyverse() paketa.
siroki_US <- siroki_US %>% rownames_to_column(var = "kategorija")
head(siroki_US) kategorija 1940 1945 1950 1955 1960
1 Food and Tobacco 22.200 44.500 59.60 73.2 86.80
2 Household Operation 10.500 15.500 29.00 36.5 46.20
3 Medical and Health 3.530 5.760 9.71 14.0 21.10
4 Personal Care 1.040 1.980 2.45 3.4 5.40
5 Private Education 0.341 0.974 1.80 2.6 3.64Tek sada imamo skup u formatu kojeg možemo dalje transformirati u duži oblik. Da bi razumjeli zašto uopće radimo “produživanje”, pokušajte sada iz postojećeg skupa “siroki_US” izračunati prosječne potrošnje po kategorijama! Nije intuitivno niti slično logici koju smo do sada koristili u R okruženju. Zato idemo “produžiti” ovaj skup podataka.
dugi_US <- siroki_US %>%
pivot_longer(-kategorija, names_to ="godina", values_to = "potrosnja")
head(dugi_US)# A tibble: 6 × 3
kategorija godina potrosnja
<chr> <chr> <dbl>
1 Food and Tobacco 1940 22.2
2 Food and Tobacco 1945 44.5
3 Food and Tobacco 1950 59.6
4 Food and Tobacco 1955 73.2
5 Food and Tobacco 1960 86.8
6 Household Operation 1940 10.5Sada imamo konačan, duži oblik skupa USPersonalExpenditure! Što smo napravili u funkciji pivot_longer(), odnosno koji argumenti su nužni? Prvo, skup koji transformiramo (siroki_US) kojeg smo “izvukli” ispred funkcije pivot_longer() sa pipe poveznicom ( %>% ). Unutar same pivot_longer() funkcije nužna su nam tri argumenta: 1. na koje stupce se produžavanje odnosi (u našem slučaju, sve stupce osim prvog stupca naziva kategorija) 2. “names_to” argument kojim dajemo naziv novog stupca koji sadrži nazive “širokih” stupaca, u našem slučaju to će biti naziv “godina” jer će taj novi stupac sadržavati godine od 1940 do 1960 3. “values_to” argument kojim dajemo naziv novog stupca koji sadrži vrijednosti iz “širokih” stupaca, u našem slučaju to će biti naziv “potrosnja” jer će taj novi stupac sadržavati potrošnju
Ova tri argumenta su nužda da bi se “široki” skup podataka pretvorio u “duži” skup podataka. Nad ovakvim, dužim skupom podataka sada možemo jednostavno provoditi sve one radnje koje se odnose na grupiranje, operacije nad grupiranim podacima, filtriranje i slično. Vratimo se sada na onaj primjer, izračunajmo prosječnu potrošnju po svim kategorijama. Vrlo jednostavno, koristimo radnju nad grupiranim podacima, a koja prije “produživanja” skupa nije bila tako jednostavna.
prosjek_kateg <- dugi_US %>% group_by(kategorija) %>%
summarise(prosjek = mean(potrosnja))
prosjek_kateg# A tibble: 5 × 2
kategorija prosjek
<chr> <dbl>
1 Food and Tobacco 57.3
2 Household Operation 27.5
3 Medical and Health 10.8
4 Personal Care 2.85
5 Private Education 1.87Suprotan primjer imamo nad podacima koji su u “dugom” obliku, a želimo ih “proširiti”. Za to ćemo koristiti ugrađeni skup naziva chickwts koji ima dva stupca: težinu pilića (varijabla weight) i hranu kojom su hranjeni (varijabla feed). Iako je postojeći oblik stupaca korektan i zapravo poželjan za većinu analiza, prikazat ćemo kako ga “proširiti” na način da svaka vrsta hrane (varijabla feed) bude zaseban stupac (varijabla). Prije “proširivanja” moramo biti sigurni da je svaki redak (u ovom slučaju jedan redak je jedno pile), a to ćemo postići tako da kreiramo novi stupac s rednim brojem svakog pilića. U nekim skupovima podataka ovaj dio neće biti potreban za “proširivanje” skupa.
# pogledajmo izvorni oblik skupa
head(chickwts) weight feed
1 179 horsebean
2 160 horsebean
3 136 horsebean
4 227 horsebean
5 217 horsebean
6 168 horsebean# kreirajmo unikatni identifikator za svaku jedinku
# ovaj korak nam je potreban jer neke jedinke imaju istu težinu (weight)
chickwts_dugi <- chickwts %>% group_by(feed) %>% mutate(id = row_number())
# proširimo naš skup
chickwts_siroki <- chickwts_dugi %>%
pivot_wider(names_from = feed, values_from = weight)%>%
select(-id)
# pogledajmo rezultat
head(chickwts_siroki)# A tibble: 6 × 6
horsebean linseed soybean sunflower meatmeal casein
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 179 309 243 423 325 368
2 160 229 230 340 257 390
3 136 181 248 392 303 379
4 227 141 327 339 315 260
5 217 260 329 341 380 404
6 168 203 250 226 153 3183.14 Funkcije i iteracije
Za izbjegavanje pogrešaka pri kodiranju potrebno je minimizirati ručni unos repetitivnih naredbi. Korištenje funkcija poželjno je svaki puta kada moramo nekakav kod prepisati više od dva puta. Primjerice, u skupu podataka USArrests želimo od svake varijable (Murder, Assault, UrbanPop i Rape) oduzeti njenu prosječnu vrijednost (centrirati). Bez uporabe funkcija, to možemo napraviti na sljedeći način:
head(USArrests) Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7USArrests$Murder <- USArrests$Murder-mean(USArrests$Murder, na.rm = TRUE)
USArrests$Assault <- USArrests$Assault-mean(USArrests$Assault, na.rm = TRUE)
USArrests$UrbanPop <- USArrests$UrbanPop-mean(USArrests$UrbanPop, na.rm = TRUE)
USArrests$Rape <- USArrests$Rape-mean(USArrests$Rape, na.rm = TRUE)
head(USArrests) Murder Assault UrbanPop Rape
Alabama 5.412 65.24 -7.54 -0.032
Alaska 2.212 92.24 -17.54 23.268
Arizona 0.312 123.24 14.46 9.768
Arkansas 1.012 19.24 -15.54 -1.732
California 1.212 105.24 25.46 19.368
Colorado 0.112 33.24 12.46 17.468Pisanje ovakvog koda nepotrebno troši vrijeme, povećava opsežnost cijelog koda i analize te povećava vjerojatnost pogreške pri unosu. Najčešća pogreška u ovakvom tipu radnji bila bi upis pogrešnog naziva varijable uslijed ponavljanja (“copy/paste”) sličnih naredbi i naziva. Primjerice:
# Uočavate li pogrešku?
USArrests$Assault <- mean(USArrests$Murder, na.rm = TRUE) Također, koliko bi linija koda morali upisati kada bi naš skup podataka imao dvadeset, trideset varijabli? Kolika bi vjerojatnost pogreške u takvom slučaju bila?
Kako bi se takve greške minimizirale, a uz to i pojednostavnilo kodiranje i izbjeglo nepotrebno ručno upisivanje, koristit ćemo funkcije.
Za početak, koristimo osnovnu R sintaksu i sami kreirajmo funkciju koja će obaviti isti posao koji smo gore “ručno” radili, odnosno centrirali podatke iz skupa podataka USArrests. Za kreiranje funkcije potrebno nam je njeno ime, argumenti i blok odnosno tijelo funkcije koje pišemo unutar zagrada {}. Ovako izgleda funkcija:
ime_funkcije <- function(x) {tijelo} Na primjeru centriranja USArrests skupa podataka, napravimo funkciju naziva centriranje i pokrenimo ju na svakoj varijabli skupa USArrests.
# Obrišimo sve objekte iz "Environment-a" da dobijemo čisti skup "USArrests"
rm(list = ls())
head(USArrests) Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7centriranje <- function(x) {
centar <- mean(x, na.rm = TRUE)
(x-centar)
}
USArrests$Murder <- centriranje(USArrests$Murder)
USArrests$Assault <- centriranje(USArrests$Assault)
USArrests$UrbanPop <- centriranje(USArrests$UrbanPop)
USArrests$Rape <- centriranje(USArrests$Rape)
#centrirani skup
head(USArrests) Murder Assault UrbanPop Rape
Alabama 5.412 65.24 -7.54 -0.032
Alaska 2.212 92.24 -17.54 23.268
Arizona 0.312 123.24 14.46 9.768
Arkansas 1.012 19.24 -15.54 -1.732
California 1.212 105.24 25.46 19.368
Colorado 0.112 33.24 12.46 17.468Sada smo centrirali sve varijable iz skupa podataka USArrests. Obratimo pozornost na glavne elemente funkcije koju smo kreirali. Nazvali smo je “centriranje”. Element x je standard i on predstavlja varijablu koju želimo “provesti” kroz funkciju. U našem slučaju će x biti Murder, Assault, UrbanPop i Rape. U tijelu funkcije koristili smo novu varijablu centar koja predstavlja aritmetičku sredinu naše x varijable. Posljednji element funkcije jest razlika između x i aritmetičke sredine od x koju smo zapisali u obliku (x - centar). Pročitajte funkciju od početka do kraja i zamislite kako se x odnosno Murder, Assault, UrbanPop i Rape “provlače” kroz algoritam: prvo im izračunamo aritmetičku sredinu (prosječnu vrijednost) i onda prosjek oduzmemo od inicijalne vrijednosti.
Kreiranjem funkcije uštedjeli smo na kodiranju samog centriranja odnosno dijela koda: USArrests$Murder-mean(USArrests$Murder, na.rm = TRUE). No, još uvijek smo ručno prepisivali svaku varijablu koju želimo centrirati. Za automatiziranje tog dijela, ulazimo u područje iteracija odnosno ponavaljanja.
Osnovni R kod iteracije bazira na for() naredbi, koje su poznate svima koji su programirali u bilo kojem drugom programskom jeziku. Drugi paketi, posebno tidyverse pristup R programiranju osmislili su još jednostavnije, ugrađene, naredbe koje oponašaju neke najčešće korištene tipove iteracija. Kako bi nastavili pojednostavljivanje primjera s centriranjem USArrests skupa, iteracije ćemo prvo obraditi prema tidyverse pristupu, pa onda putem for() naredbi.
Naredba lapply() provest će funkciju kroz svaki element skupa podataka i vratiti objekt kao listu. Naredbom data.frame() pretvorit ćemo je u naš poznati data frame objekt.
Sintaksa funkcije glasi: lapply(skup_podataka, funkcija).
# Obrišimo sve objekte iz "Environment-a" da dobijemo čisti skup "USArrests"
rm(list = ls())
head(USArrests) Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7centriranje <- function(x) {
centar <- mean(x, na.rm = TRUE)
(x-centar)
}
# Centrirali smo skup USArrests
USArrests <- data.frame(lapply(USArrests, centriranje))
# Pogedajmo centrirani skup podataka
head(USArrests) Murder Assault UrbanPop Rape
1 5.412 65.24 -7.54 -0.032
2 2.212 92.24 -17.54 23.268
3 0.312 123.24 14.46 9.768
4 1.012 19.24 -15.54 -1.732
5 1.212 105.24 25.46 19.368
6 0.112 33.24 12.46 17.468Korištenjem lapply() funkcije izbjegli smo ručno pozivanje funkcije centriranje na svaku varijablu kao u prethodnom primjeru. Sada smo konačno minimizirali ručno prepisivanje svake varijable i ručno oduzimanje prosjeka od elementa te minimizirali pogreške u sintaksi.
Najnoviji tidyverse pristup bazira se na setu map() naredbi. Set map() naredbi ima niz različitih oblika poput map_at(), map_if(), map_chr() i druge, ali zajedničko svim naredbama jest da pokreću neku funkciju od interesa nad svakim elementom vektora (ili uvjetno, odabranim elementima).
Temeljna map() funkcija vraća objekt u obliku liste, dok map_dbl(), map_chr(), map_lgl() i map_int() vraćaju objekt u obliku odgovarajućeg tipa vektora (vidljivo iz naziva sufiksa funkcije). Naredbe map_dfr() i map_dfc() vraćaju data frame povezujući retke (map_dfr()) ili stupce (map_dfc()).
Pojasnit ćemo na sljedećem primjeru u kojem želimo izračunati medijalnu vrijednost svake vrste kriminala (Murder, Assault, UrbanPop i Rape) u skupu USArrests.
rm(list = ls())
head(USArrests) Murder Assault UrbanPop Rape
Alabama 13.2 236 58 21.2
Alaska 10.0 263 48 44.5
Arizona 8.1 294 80 31.0
Arkansas 8.8 190 50 19.5
California 9.0 276 91 40.6
Colorado 7.9 204 78 38.7# rezultat u obliku liste
USArrests %>% map(median) $Murder
[1] 7.25
$Assault
[1] 159
$UrbanPop
[1] 66
$Rape
[1] 20.1# rezultat u obliku vektora (numeričkog)
USArrests %>% map_dbl(median) Murder Assault UrbanPop Rape
7.25 159.00 66.00 20.10 # rezultat u obliku *data frame*-a
USArrests %>% map_dfr(median) # A tibble: 1 × 4
Murder Assault UrbanPop Rape
<dbl> <dbl> <dbl> <dbl>
1 7.25 159 66 20.1# spremimo posljednji *data frame* kao objekt
medijan_kriminala <- USArrests %>% map_dfr(median)
head(medijan_kriminala)# A tibble: 1 × 4
Murder Assault UrbanPop Rape
<dbl> <dbl> <dbl> <dbl>
1 7.25 159 66 20.1Skupovi podataka su u svakodnevnom radu rijetko isključivo jednog tipa varijabli, uređeni i “čisti” kao “USArrests”. Pogledajmo ponašanje funkcije map() na primjeru već poznatog, a nešto “realnijeg” skupa podataka diamonds koji sadrži više tipova varijabli i missing values odnosno NA elemente. Kao i na prošlom primjeru, izračunajmo medijalnu vrijednost svake varijable.
# zašto imamo pogrešku?
diamonds %>% map_dfr(median) Funkcija map() ovdje može biti zgodna za pogledati tip svih varijabli u skupu podataka.
# pogledajmo koji tip varijabli postoji u skupu diamonds
diamonds %>% map(class) $carat
[1] "numeric"
$cut
[1] "ordered" "factor"
$color
[1] "ordered" "factor"
$clarity
[1] "ordered" "factor"
$depth
[1] "numeric"
$table
[1] "numeric"
$price
[1] "integer"
$x
[1] "numeric"
$y
[1] "numeric"
$z
[1] "numeric"Vidimo da osim numeričkih varijabli imamo i faktorske varijable, za koje, bez transformacije, ne možemo izračunati medijalnu vrijednost pomoću funkcije median(). Istu situaciju bi imali u slučaju znakovnih ili logičkih varijabli. U ovakvim slučajevima, koji su u svakodnevnom radu, uobičajeni, poslužit ćemo se uvjetnom varijantom map() funkcije, odnosno map_if() naredbom. Naredba map_if() treba 2 argumenta. Prvi argument je uvjet koji element mora zadovoljiti, a drugi argument je funkcija koja će se pokrenuti nad tim elementom. U našem primjeru, prvo testiramo je li varijabla numeričkog tipa, ako jest, tražimo vrijednost medijana. Dodatno, koristili smo treći argument (opcionalni) .else= kojim zadajemo što učiniti s onima koji nisu zadovoljili uvjet (u našem slučaju, nisu numeričke varijable). Argumentom .else=class zadali smo naredbu da u slučaju ne-numeričkih varijabli rezultat bude klasa te varijable odnosno tip varijable.
diamonds %>% map_if(is.numeric, median, .else = class)$carat
[1] 0.7
$cut
[1] "ordered" "factor"
$color
[1] "ordered" "factor"
$clarity
[1] "ordered" "factor"
$depth
[1] 61.8
$table
[1] 57
$price
[1] 2401
$x
[1] 5.7
$y
[1] 5.71
$z
[1] 3.53Konačno, za numeričke varijable smo izračunali medijalne vrijednosti, a za one koje nisu numeričke, samo smo ispisali njihov tip varijable.
3.15 Učitavanje podataka iz drugih formata
Do sada smo spominjali kreiranje vektora, matrica i data frame-ova unutar samog R okruženja. U svakodnevnom radu rijetko ćemo sami kreirati skupove podataka: učitavat ćemo ih iz vanjskih izvora. Jedan od nativnih R formata skupova podataka je .rds no rijetke su online baze podataka koje u startu nude podatke u takvom formatu.
Također, većina podataka koje ste do sada koristili dolaze ili iz Office okruženja (.xls ili .xlsx) ili nekog drugog statističkog paketa (SPSS, SAS, STATA itd.). Srećom, R je moćan alat koji bez problema (ili uz minimalne kompromise) učitava gotovo sve što želite.
Sve veći naglasak na otvorenosti podataka i analiza nameće potrebu za koliko-toliko standardnim formatom podataka. U tom smjeru se comma separated value (zarezom odvojene vrijednosti) format odnosno .csv format istaknuo kao najčešći format s kojim se susrećemo u svakodnevnom radu. Eurostat, DZS i brojne druge agencije i rezultati znanstvenih istraživanja daju .csv format kao jedan od standardnih formata u kojima publiciraju skupove podataka.
Za učitavanje .csv podataka možemo koristiti sljedeće funkcije:
read.csv()iliread.csv2()read_csv()(tidyverse paket)read.table()fread()(data.table paket)
Svaka od njih ima određene specifičnosti, od kojih read.table() zahtijeva najveći broj argumenata. read.csv() i njegov tidyverse pandan read_csv() su sasvim dovoljne za učitavanje svih .csv skupova podataka. Ukoliko naš .csv koristi neki drugi znak za odvajanje stupaca, recimo tabulator (prazni prostor) ili točku, dovoljno je korigirati argument sep= unutar funkcije. Ponekad se pojavi i greška vezano za deimalne brojeve prilikom čitanja podataka u R-u, te u tom slučaju treba specificirati oznaku za decimalne brojeve korištenjem naredbe dec="." Podsjetimo se, za proučiti nužne i opcionalne argumente neke funkcije, samo pokrenemo ? prije naziva funkcije, primjerice:
?read.csvKod velikih .csv datoteka, učitavanje može biti sporo. U tom slučaju, preporučamo koristiti fread() funkciju iz data.table paketa koja je višestruko brža od prethodno opisanih funkcija za učitavanje .csv datoteka. Jedini argument unutar fread() funkcije koji je potreban je file = "naziv_datoteke.csv".
Za učitavanje podataka iz formata programa SPSS, SAS i Stata potrebno je instalirati paket haven te pozvati odgovarajući library(haven). Tada možemo koristiti funkcije:
read_sasiread_savza učitavanje SAS formataread_dtairead_stataza učitavanje Stata formataread_spssza učitavanje SPSS formata
Za učitavanje Excel-ovih formata .xls i .xlsx potrebno je instalirati dodani paket readxl. Instalirajmo paket s Install.packages(readxl) i pokrenimo library(readxl) te možemo koristiti funkcije koja učitava Excelove podatke, a to su:
read_xls()read_xlsx()
Učitavanje podataka iz vanjskih izvora zahtijeva argument file= ili path= unutar odgovarajuće funkcije (primjerice read.csv() ili read_xlsx()). U tom argumentu nužno je navesti cijelu putanju odnosno adresu datoteke koju želimo učitati i to u navodnicima. Primjer: read_xlsx(path="Documents/primjeri/R_folder/tablica.xlsx")
Koristeći projekte ili kontrolirajući gdje nam je aktualni radni direktorij, možemo značajno olakšati pisanje koda odnosno pozivanje vanjskih objekata u RStudio. Više o tome u sljedećem dijelu Projekti i radni direktorij.
Po početnim postavkama, RStudio stavlja mapu Dokumenti ili Documents
3.16 Projekti i radni direktorij
Radni direktorij je mapa koju RStudio smatra temeljnom mapom u kojoj sprema aktualnu R skriptu, eksportira skupove podataka, grafikone, učitava podatke i ostalo.
Po defaultu, RStudio stavlja mapu Dokumenti ili Documents kao radni direktorij. Ručno ga možemo promijeniti klikom miša na Tools -> Global options te odabrati novi radni direktorij.
Putanju aktualnog radnog direktorija možemo dobiti s naredbom getwd().
# putanja radnog direktorija će se prikazati u konzoli
getwd() Kodom možemo promijeniti radni direktorij s naredbom setwd(). Ponovno, potrebno je navesti punu putanju novog radnog direktorija. Primjerice ovako: setwd(/putanja/do/mog/radnog/direktorija). Možemo za svaku našu odvojenu analizu raditi posebne direktorije i svaki put mijenjati lokaciju radnog direktorija, ali to ne preporučamo jer postoji puno jednostavniji način upravljanja našim radom u R okruženju, a omogućava ga RStudio. Dodatno, ako imate kolaboraciju s nekim, ta osoba će vrlo vjerojatno imati drugačiju putanju za svoje R direktorije. Stoga nikako ne preporučamo koristiti ručno postavljanje i navođenje cijelih putanja u R.
R okruženje prepoznaje nešto što se naziva R projekt, a RStudio ima implementirano jednostavno grafičko sučelje za upravljanje projektima. Projekti su zapravo mape koje zaokružuju naš rad u R okruženju na neku temu odnosno analizu. Kliknimo na File -> New Project i kreirajmo novi projekt naziva “Moj_prvi_projekt” (odaberite opcije New Directory i Empty Project).
Time smo kreirali novu mapu naziva Moj_prvi_projekt na našem računalu i ona će biti radni direktorij za sve R skripte, grafikone, vanjske skupove podataka koje unutra spremimo, eksportirane podatke i ostalo što radimo unutar tog projekta.
Kako budemo imali više projekata, tako ćemo ih i otvarati kroz opciju File->Open Project ili direktno kroz mapu na računalu otvarajući “.Rproj” datoteku.
Klikom na okvir Files u RStudiu možemo vidjeti što se sve nalazi u folderu našeg aktualno otvorenog projekta.
Nakon kreiranog projekta, ta mapa postaje i ostaje radni direktorij za taj projekt. Više nije potrebno provjeravati i ručno postavljati radni direktorij. Još važnije, nije potrebno pisati pune putanje datoteka koje pozivamo u R ili kada eksportiramo podatke van R okruženja (grafikoni, tablice itd.).
Primjer: želimo učitati skup podataka iz vanjskog izvora, Excel tablicu naziva tablica.xlsx. Prije kreiranja projekta, bilo je potrebno napisati punu putanju te tablice, primjerice read_xlsx(path="Documents/primjeri/R_folder/tablica.xlsx"). Nakon što smo kreirali projekt i premjestili/kopirali tablica.xlsx u mapu od projekta, potrebno je samo pozvati njeno ime jer RStudio uzima projektnu mapu kao “glavnu” mapu iz koje vuče sve vanjske datoteke (ili eksportira rezultate iz R analize). Tako je dovoljno napisati read_xlsx(path="tablica.xlsx").
Osim što smanjujemo količinu koda koji trebamo pisati ovime izbjegavamo i pisanje punih naziva putanja, što uvijek dovodi do problema kada našu R skriptu dijelimo s koautorom istraživanja koji će sigurno imati drugačije putanje na svom računalu.
3.17 Zadatci za vježbu
Zadatak 1.
- Kreirajte vektor naziva “ime” koji sadrži 8 različitih imena
- Kreirajte vektor naziva “spol” koji sadrži 8 opažanja o spolu “m” ili “z”
- Kreirajte vektor naziva “visina” koji sadrži 8 opažanja o visini u centimetrima
- Kreirajte vektor naziva “tezina” koji sadrži 8 opažanja o tjelesnoj težini u kilogramima
- Spojite navedena četiri vektora u data frame
Zadatak 2.
- Izračunajte prosječnu visinu
- Izračunajte raspon težine
- Izračunajte prvi kvartil težine
Zadatak 3.
- Izračunajte prosječno ime. Zašto ne možete izračunati? Kakvu vrstu greške dobivamo, logičku ili sintaksnu?
Zadatak 4.
- Izračunajte prosječnu visinu i prosječnu težinu kod muškaraca
- Kreirajte novu varijablu u data frame-u naziva BMI koji predstavlja indeks tjelesne težine, a računa se po formuli \(BMI = težina (kg) / visina (m)^2\) (visina je u metrima!)
Zadatak 5.
- Kreirajte funkciju kojom se u skupu podataka USArrests od svakog elementa oduzme njena standardna devijacija
Iako ćemo uglavnom koristiti samo neke pakete poput dplyr, purrr i ggplot2, u tekstu ćemo spominjati tidyverse kao cjelinu te ćemo u našim skriptama učitavati cijeli tidyverse paket. Za one koji žele znati detaljnije i razlikovati pojedine pakete unutar tidyverse svijeta preporučujemo stranicu https://www.tidyverse.org/ odnosno knjigu (Wickham et al., 2023) R for Data Science, dostupnu na: https://r4ds.hadley.nz/↩︎
Data frame će u konzoli prikazati prvih 50 redaka, a tibble 10 i sve stupce koji stanu u okvir ekrana. Također, tibble će dodatno prikazati i tip svakog stupca (numeric, character…). U odnosu na data frame, poduzorak tibble-a će dati upozorenje u konzoli (poruku warning) ukoliko ne postoji stupac kojeg pozivamo i neće prikazati djelomično podudaranje.↩︎
U trenutku pisanja ove knjige na službenim kanalima razvojnog tima R jezika najavljeno je uvođenje i “pipe” operatora u osnovni R jezik u obliku
|>↩︎